Lost in Translation? Vocabulary Alignment for Source-Free Adaptation in Open-Vocabulary Semantic Segmentation
作者: Silvio Mazzucco, Carl Persson, Mattia Segu, Pier Luigi Dovesi, Federico Tombari, Luc Van Gool, Matteo Poggi
分类: cs.CV
发布日期: 2025-09-18 (更新: 2025-09-29)
备注: BMVC 2025 - Project Page: https://thegoodailab.org/blog/vocalign - Code: https://github.com/Sisso16/VocAlign
💡 一句话要点
VocAlign:面向开放词汇语义分割的无源域自适应词汇对齐方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇语义分割 无源域自适应 视觉语言模型 词汇对齐 伪标签
📋 核心要点
- 现有开放词汇语义分割方法在无源域自适应场景下,难以有效利用视觉语言模型中的丰富知识。
- VocAlign通过词汇对齐策略增强伪标签生成,并结合师生范式,实现更有效的知识迁移和泛化。
- 实验表明,VocAlign在CityScapes数据集上取得了显著的mIoU提升,并在零样本分割任务中表现出色。
📝 摘要(中文)
本文提出了一种名为VocAlign的全新无源域自适应框架,专门为开放词汇语义分割中的视觉语言模型(VLM)设计。我们的方法采用了一种师生范式,并增强了一种词汇对齐策略,该策略通过整合额外的类别概念来改进伪标签的生成。为了确保效率,我们使用低秩适应(LoRA)来微调模型,在保留其原始能力的同时,最大限度地减少计算开销。此外,我们为学生模型提出了一种Top-K类别选择机制,该机制显著降低了内存需求,同时进一步提高了自适应性能。我们的方法在CityScapes数据集上实现了显著的6.11 mIoU改进,并在零样本分割基准测试中表现出卓越的性能,为开放词汇设置中的无源域自适应树立了新的标准。
🔬 方法详解
问题定义:论文旨在解决开放词汇语义分割中,无源域自适应的问题。现有的方法难以充分利用视觉语言模型(VLM)的知识,导致在目标域上的性能不佳。痛点在于如何有效地将源域的知识迁移到目标域,同时避免对源域数据的依赖。
核心思路:论文的核心思路是通过词汇对齐来增强伪标签的质量,从而提高无源域自适应的效果。具体来说,通过引入额外的类别概念,使得伪标签更加准确和完整,从而更好地指导学生模型的训练。同时,采用师生范式,利用教师模型生成伪标签,学生模型进行学习。
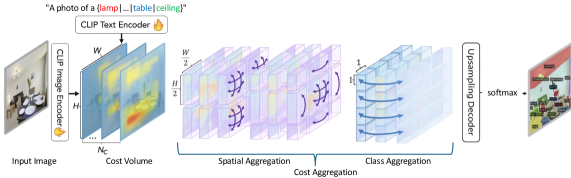
技术框架:VocAlign框架主要包含以下几个模块:1) 教师模型:使用预训练的VLM,负责生成伪标签。2) 学生模型:使用LoRA进行微调,学习教师模型生成的伪标签。3) 词汇对齐模块:通过引入额外的类别概念,增强伪标签的质量。4) Top-K类别选择模块:减少学生模型的内存需求,并提高自适应性能。
关键创新:论文的关键创新在于提出了词汇对齐策略,该策略通过引入额外的类别概念,使得伪标签更加准确和完整。与现有方法相比,VocAlign能够更好地利用VLM的知识,从而在目标域上取得更好的性能。此外,Top-K类别选择机制也降低了计算成本。
关键设计:论文使用LoRA进行模型微调,降低了计算开销。Top-K类别选择机制选择置信度最高的K个类别,用于学生模型的训练,减少了内存需求。损失函数采用标准的交叉熵损失函数,用于衡量学生模型预测结果与伪标签之间的差异。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
VocAlign在CityScapes数据集上实现了6.11 mIoU的显著提升,并在零样本分割基准测试中表现出卓越的性能。相较于现有方法,VocAlign在无源域自适应的开放词汇语义分割任务中取得了显著的进步,为该领域的研究提供了新的思路。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、遥感图像分析等领域,提升模型在不同环境下的泛化能力和分割精度。通过利用开放词汇的优势,可以实现对未知场景的有效理解和分割,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
We introduce VocAlign, a novel source-free domain adaptation framework specifically designed for VLMs in open-vocabulary semantic segmentation. Our method adopts a student-teacher paradigm enhanced with a vocabulary alignment strategy, which improves pseudo-label generation by incorporating additional class concepts. To ensure efficiency, we use Low-Rank Adaptation (LoRA) to fine-tune the model, preserving its original capabilities while minimizing computational overhead. In addition, we propose a Top-K class selection mechanism for the student model, which significantly reduces memory requirements while further improving adaptation performance. Our approach achieves a notable 6.11 mIoU improvement on the CityScapes dataset and demonstrates superior performance on zero-shot segmentation benchmarks, setting a new standard for source-free adaptation in the open-vocabulary setting.