QuizRank: Picking Images by Quizzing VLMs
作者: Tenghao Ji, Eytan Adar
分类: cs.HC, cs.CV
发布日期: 2025-09-18 (更新: 2025-09-19)
💡 一句话要点
QuizRank:利用视觉语言模型进行问答式图像排序,提升维基百科文章配图质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 图像排序 问答系统 维基百科 图像选择
📋 核心要点
- 维基百科文章的配图质量参差不齐,且编辑者在图像选择方面缺乏专业训练,导致部分配图效果不佳。
- QuizRank的核心思想是将图像选择转化为VLM的问答任务,通过提问图像内容相关问题来评估图像质量。
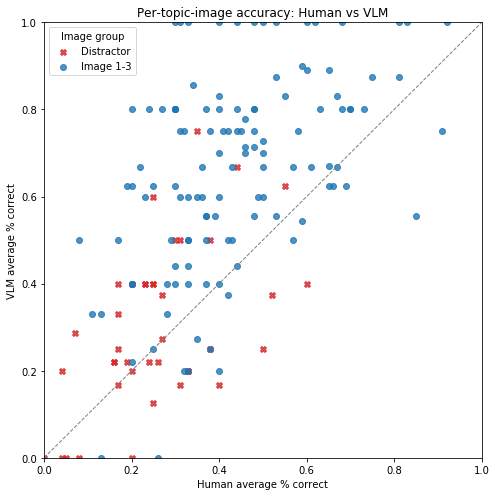
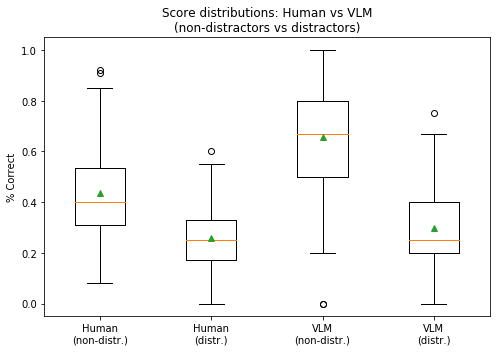
- 实验表明,QuizRank与人类的判断具有高度一致性,并且能够有效区分视觉上相似的图像,提升排序效果。
📝 摘要(中文)
本文提出了一种名为QuizRank的图像选择新方法,旨在利用大型语言模型(LLMs)和视觉语言模型(VLMs)对图像作为学习干预手段进行排序,从而提升维基百科文章的配图效果。该方法将文章主题的文本描述转化为关于概念重要视觉特征的多项选择题。然后,利用这些问题来“考查”视觉语言模型(VLM):图像越能帮助回答问题,其排名就越高。为了进一步区分视觉上相似的项目,本文引入了对比QuizRank,它利用目标概念(例如,西部蓝知更鸟)和干扰概念(例如,山蓝知更鸟)的特征差异来生成问题。实验结果表明,视觉语言模型作为有效的视觉评估器具有潜力,与人类答题者高度一致,并能有效地对图像进行区分性排序。
🔬 方法详解
问题定义:论文旨在解决维基百科文章配图质量不高的问题。现有方法依赖人工选择,效率低且质量不稳定,缺乏客观的评估标准。此外,对于视觉上相似的概念,现有方法难以有效区分,导致配图不够精准。
核心思路:论文的核心思路是将图像选择问题转化为一个基于视觉语言模型的问答任务。通过生成与文章主题相关的多项选择题,并利用VLM来回答这些问题,从而评估图像在多大程度上能够帮助读者理解文章内容。图像能够帮助VLM更好地回答问题,则认为该图像质量更高。
技术框架:QuizRank的整体框架包含以下几个主要模块:1) 问题生成模块:根据文章主题的文本描述,生成关于图像视觉特征的多项选择题。2) VLM问答模块:利用VLM对候选图像进行问答测试,评估图像在回答问题方面的表现。3) 图像排序模块:根据VLM的问答结果,对候选图像进行排序,选择排名最高的图像作为最终配图。对比QuizRank在此基础上,增加了利用目标概念和干扰概念的特征差异来生成问题的步骤。
关键创新:论文的关键创新在于将图像选择问题转化为一个可量化的VLM问答任务。通过利用VLM的视觉理解能力,自动评估图像的质量,避免了人工选择的主观性和低效率。此外,对比QuizRank通过引入对比学习的思想,进一步提升了对视觉相似概念的区分能力。
关键设计:问题生成模块的设计至关重要,需要确保生成的问题能够准确反映文章主题的视觉特征。VLM的选择也会影响最终的排序结果,需要选择具有较强视觉理解能力的VLM。对比QuizRank中,目标概念和干扰概念的选择需要仔细考虑,以确保能够生成具有区分性的问题。具体的损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,QuizRank与人类答题者在图像选择方面具有高度一致性,证明了VLM作为视觉评估器的有效性。对比QuizRank能够有效区分视觉上相似的图像,提升排序效果。具体的性能数据和提升幅度在论文中未明确给出,属于未知信息。
🎯 应用场景
QuizRank可应用于各种需要图像选择的场景,例如在线教育、新闻报道、产品展示等。通过自动评估图像质量,可以提高信息传递的效率和准确性,提升用户体验。未来,该方法可以进一步扩展到视频选择等领域,具有广阔的应用前景。
📄 摘要(原文)
Images play a vital role in improving the readability and comprehension of Wikipedia articles by serving as `illustrative aids.' However, not all images are equally effective and not all Wikipedia editors are trained in their selection. We propose QuizRank, a novel method of image selection that leverages large language models (LLMs) and vision language models (VLMs) to rank images as learning interventions. Our approach transforms textual descriptions of the article's subject into multiple-choice questions about important visual characteristics of the concept. We utilize these questions to quiz the VLM: the better an image can help answer questions, the higher it is ranked. To further improve discrimination between visually similar items, we introduce a Contrastive QuizRank that leverages differences in the features of target (e.g., a Western Bluebird) and distractor concepts (e.g., Mountain Bluebird) to generate questions. We demonstrate the potential of VLMs as effective visual evaluators by showing a high congruence with human quiz-takers and an effective discriminative ranking of images.