M-PACE: Mother Child Framework for Multimodal Compliance
作者: Shreyash Verma, Amit Kesari, Vinayak Trivedi, Anupam Purwar, Ratnesh Jamidar
分类: cs.CV, cs.CL
发布日期: 2025-09-17
备注: The M-PACE framework uses a "mother-child" AI model system to automate and unify compliance checks for ads, reducing costs while maintaining high accuracy
💡 一句话要点
M-PACE:用于多模态合规的母子框架,降低审核成本并提升效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 合规性检查 大语言模型 广告审核 母子模型 成本优化 自动化 视觉语言
📋 核心要点
- 传统多模态内容合规流程复杂,依赖多个独立模块,导致高运营成本和低效率。
- M-PACE框架利用母子MLLM结构,母模型评估子模型输出,实现单次处理视觉和文本内容。
- 实验表明,M-PACE显著降低推理成本,同时保持了与更复杂模型相当的准确性。
📝 摘要(中文)
本文提出多模态参数无关合规引擎(M-PACE),旨在统一处理视觉和文本内容,以评估跨视觉-语言输入的属性。传统合规框架依赖于分离的多阶段流程,集成图像分类、文本提取、音频转录等模块,导致运营开销增加、可扩展性受限,且难以适应动态指南。M-PACE采用母子MLLM设置,通过更强大的母MLLM评估较小子模型的输出,显著减少对人工审核的依赖,从而实现质量控制自动化。在广告合规用例中,M-PACE能够评估超过15个合规相关属性。实验结果表明,推理成本降低超过31倍,最有效的模型(Gemini 2.0 Flash作为子MLLM)的单张图像成本为0.0005美元,而Gemini 2.5 Pro的成本为0.0159美元,同时保持了相当的准确性,突出了M-PACE在实际广告数据部署中实现的成本与输出质量之间的权衡。
🔬 方法详解
问题定义:当前多模态内容(如广告)的合规性检查依赖于多个独立的模块,例如图像分类、文本提取等。这些模块组成的pipeline不仅复杂,而且难以维护和扩展,同时也增加了运营成本。此外,面对不断变化的合规标准,这种pipeline的更新和调整也十分困难。
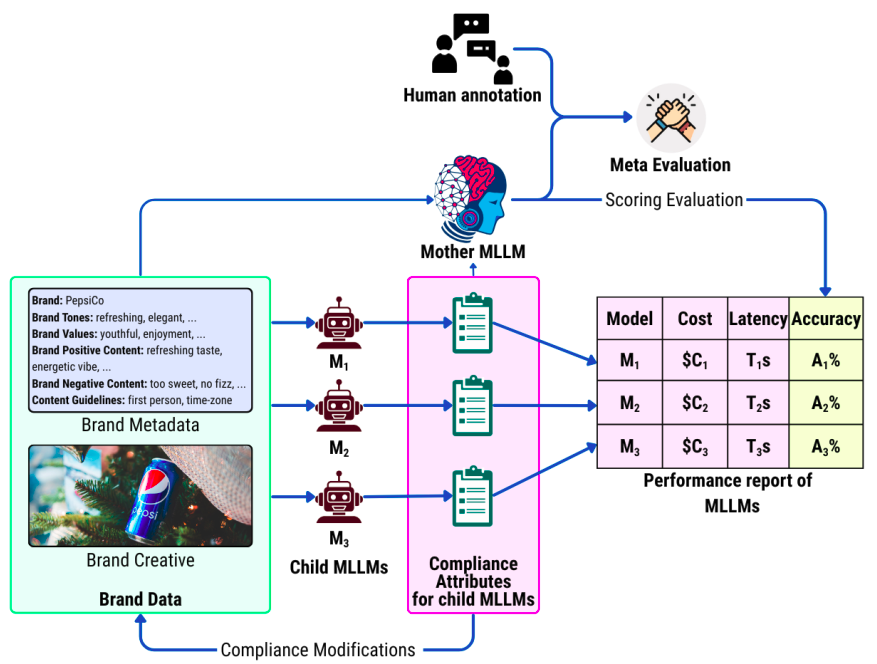
核心思路:论文的核心思路是利用多模态大语言模型(MLLM)的强大能力,将多个独立的合规检查模块统一到一个框架中。通过母子MLLM的结构,母模型负责评估子模型的输出,从而实现更高效、更灵活的合规性检查。这种设计旨在降低对人工审核的依赖,并提高自动化程度。
技术框架:M-PACE框架的核心是母子MLLM结构。子MLLM负责处理输入的视觉和文本信息,并生成初步的合规性评估结果。母MLLM则负责对子MLLM的输出进行评估和筛选,从而提高整体的准确性和可靠性。整个流程可以概括为:输入多模态数据 -> 子MLLM处理 -> 母MLLM评估 -> 输出合规性评估结果。
关键创新:M-PACE的关键创新在于其母子MLLM结构,以及将多模态合规性检查问题转化为一个统一的MLLM任务。通过母模型的评估,可以有效地纠正子模型的错误,从而提高整体的性能。此外,M-PACE框架具有很强的灵活性,可以根据不同的合规标准和应用场景,选择不同的子模型和母模型。
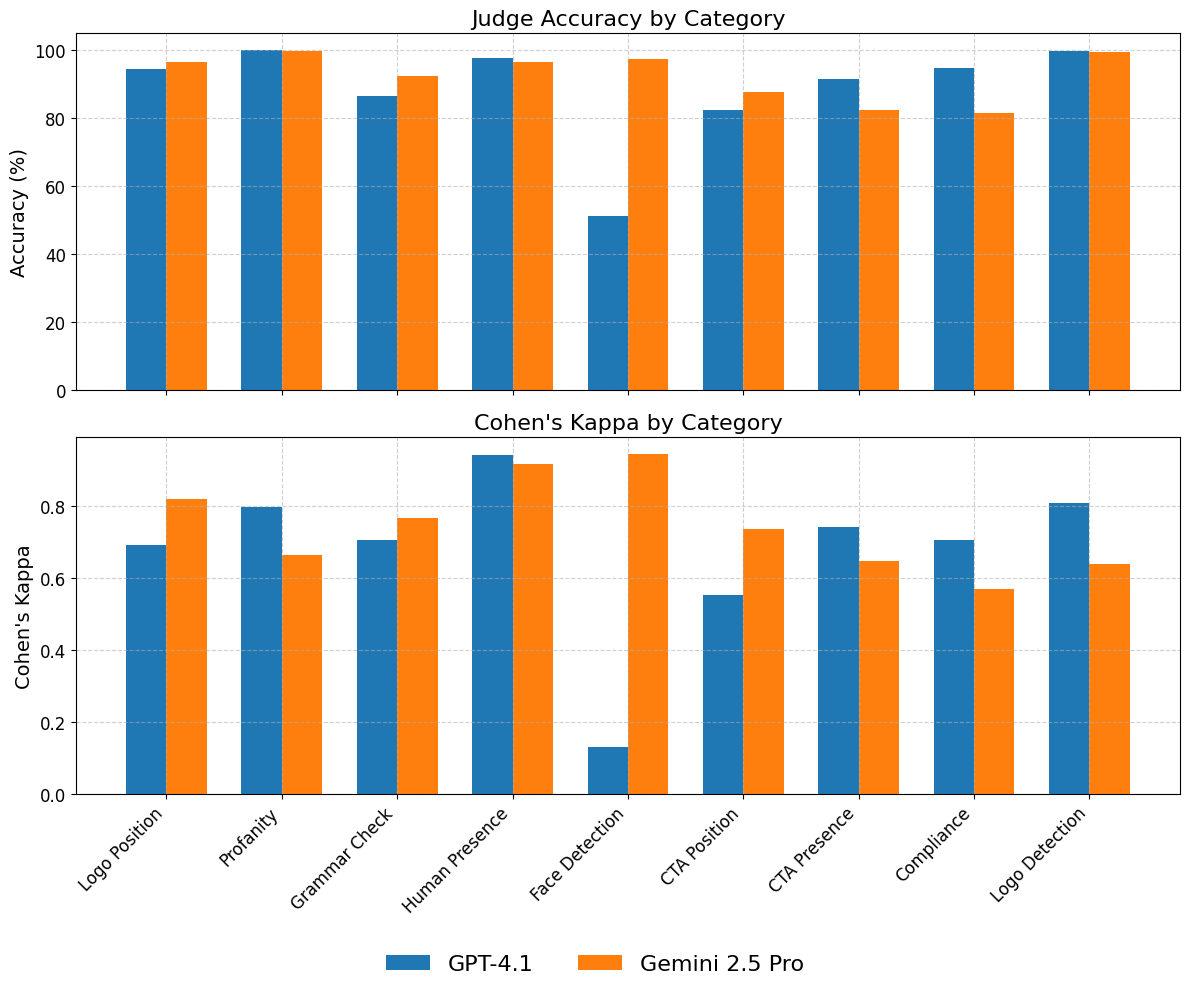
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,母子模型的选择是关键设计之一。论文提到使用Gemini 2.0 Flash作为子模型,Gemini 2.5 Pro作为母模型,并在成本和准确性之间进行权衡。此外,论文还引入了人工标注的基准数据集,用于评估M-PACE的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,M-PACE框架在广告合规性检查任务中表现出色。通过使用Gemini 2.0 Flash作为子模型,推理成本降低超过31倍,单张图像成本仅为0.0005美元,同时保持了与Gemini 2.5 Pro相当的准确性(成本为0.0159美元)。这充分证明了M-PACE框架在降低成本和提高效率方面的优势。
🎯 应用场景
M-PACE框架可广泛应用于需要多模态内容合规性检查的领域,例如广告审核、社交媒体内容监管、电商平台商品审核等。该框架能够显著降低人工审核成本,提高审核效率,并确保内容符合相关法规和平台规范。未来,M-PACE有望扩展到更多领域,例如金融风控、医疗诊断等。
📄 摘要(原文)
Ensuring that multi-modal content adheres to brand, legal, or platform-specific compliance standards is an increasingly complex challenge across domains. Traditional compliance frameworks typically rely on disjointed, multi-stage pipelines that integrate separate modules for image classification, text extraction, audio transcription, hand-crafted checks, and rule-based merges. This architectural fragmentation increases operational overhead, hampers scalability, and hinders the ability to adapt to dynamic guidelines efficiently. With the emergence of Multimodal Large Language Models (MLLMs), there is growing potential to unify these workflows under a single, general-purpose framework capable of jointly processing visual and textual content. In light of this, we propose Multimodal Parameter Agnostic Compliance Engine (M-PACE), a framework designed for assessing attributes across vision-language inputs in a single pass. As a representative use case, we apply M-PACE to advertisement compliance, demonstrating its ability to evaluate over 15 compliance-related attributes. To support structured evaluation, we introduce a human-annotated benchmark enriched with augmented samples that simulate challenging real-world conditions, including visual obstructions and profanity injection. M-PACE employs a mother-child MLLM setup, demonstrating that a stronger parent MLLM evaluating the outputs of smaller child models can significantly reduce dependence on human reviewers, thereby automating quality control. Our analysis reveals that inference costs reduce by over 31 times, with the most efficient models (Gemini 2.0 Flash as child MLLM selected by mother MLLM) operating at 0.0005 per image, compared to 0.0159 for Gemini 2.5 Pro with comparable accuracy, highlighting the trade-off between cost and output quality achieved in real time by M-PACE in real life deployment over advertising data.