Dense Video Understanding with Gated Residual Tokenization
作者: Haichao Zhang, Wenhao Chai, Shwai He, Ang Li, Yun Fu
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-09-17 (更新: 2025-09-18)
💡 一句话要点
提出密集视频理解方法以解决低帧率采样问题
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 密集视频理解 门控残差标记化 高帧率视频 时间推理 运动补偿 语义合并 视频理解
📋 核心要点
- 现有视频理解方法主要依赖低帧率采样,导致重要的时间信息丢失,特别是在信息频繁变化的场景中。
- 本文提出的密集视频理解(DVU)方法,通过门控残差标记化(GRT)技术,优化了视频标记过程,提升了高帧率视频的理解能力。
- 实验结果显示,GRT在DIVE基准上表现优异,超越了现有的VLLM基线,并且在帧率提升时性能持续改善。
📝 摘要(中文)
高时间分辨率对于捕捉视频理解中的细粒度细节至关重要。然而,现有的视频大型语言模型(VLLMs)和基准测试大多依赖于低帧率采样,忽略了密集的时间信息。为了解决这一问题,本文提出了密集视频理解(DVU),通过减少标记时间和标记开销,实现高帧率视频理解。同时,提出了DIVE基准,专注于密集时间推理。为使DVU更具实用性,提出了门控残差标记化(GRT),该框架通过运动补偿和语义场景合并,显著提高了效率和可扩展性。实验结果表明,GRT在DIVE基准上超越了更大的VLLM基线,并且随着帧率的提高表现良好。
🔬 方法详解
问题定义:本文旨在解决现有视频理解方法在低帧率采样下丢失密集时间信息的问题,尤其是在信息频繁变化的场景中,如讲座理解等。现有方法在处理这些场景时,无法实现精确的时间对齐,导致理解效果不佳。
核心思路:论文提出的密集视频理解(DVU)通过门控残差标记化(GRT)技术,旨在提高视频理解的时间分辨率,减少标记时间和计算开销,从而实现高帧率视频的有效理解。
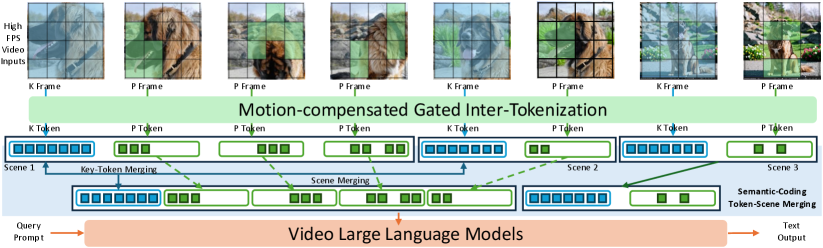
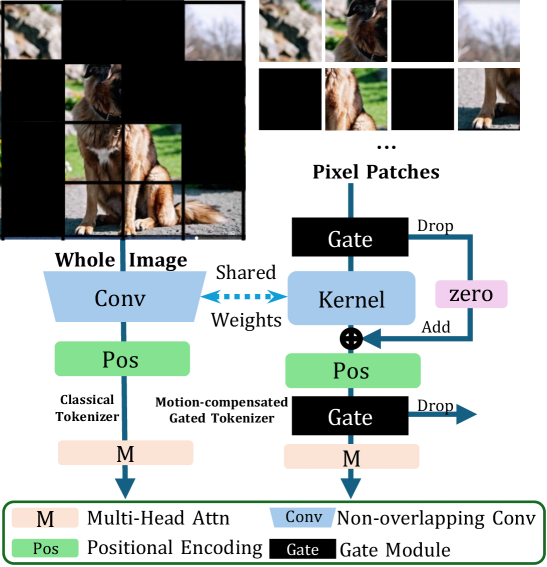
技术框架:GRT框架分为两个主要阶段:第一阶段是运动补偿的跨门控标记化,通过像素级运动估计跳过静态区域,从而实现标记数量的亚线性增长;第二阶段是语义场景内标记合并,进一步减少冗余,同时保留动态语义信息。
关键创新:GRT的核心创新在于其双阶段的标记化策略,结合运动补偿和语义合并技术,显著提升了视频理解的效率和可扩展性。这一方法与传统的低帧率采样方法本质上不同,后者往往忽略了密集时间信息。
关键设计:在GRT中,运动补偿阶段使用像素级运动估计来识别静态区域,减少不必要的计算;而在语义合并阶段,通过聚合静态区域内的标记,进一步优化标记数量和计算效率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GRT在DIVE基准上超越了更大的VLLM基线,具体表现为在高帧率下的理解能力显著提升,验证了密集时间信息的重要性。GRT的性能随着帧率的提高而持续改善,展示了其良好的可扩展性。
🎯 应用场景
该研究的潜在应用领域包括教育视频分析、实时监控、体育赛事解说等,能够在需要高时间分辨率的场景中提供更精准的理解和分析。未来,该方法可能推动视频理解技术在自动驾驶、智能监控等领域的广泛应用,提升系统的智能化水平。
📄 摘要(原文)
High temporal resolution is essential for capturing fine-grained details in video understanding. However, current video large language models (VLLMs) and benchmarks mostly rely on low-frame-rate sampling, such as uniform sampling or keyframe selection, discarding dense temporal information. This compromise avoids the high cost of tokenizing every frame, which otherwise leads to redundant computation and linear token growth as video length increases. While this trade-off works for slowly changing content, it fails for tasks like lecture comprehension, where information appears in nearly every frame and requires precise temporal alignment. To address this gap, we introduce Dense Video Understanding (DVU), which enables high-FPS video comprehension by reducing both tokenization time and token overhead. Existing benchmarks are also limited, as their QA pairs focus on coarse content changes. We therefore propose DIVE (Dense Information Video Evaluation), the first benchmark designed for dense temporal reasoning. To make DVU practical, we present Gated Residual Tokenization (GRT), a two-stage framework: (1) Motion-Compensated Inter-Gated Tokenization uses pixel-level motion estimation to skip static regions during tokenization, achieving sub-linear growth in token count and compute. (2) Semantic-Scene Intra-Tokenization Merging fuses tokens across static regions within a scene, further reducing redundancy while preserving dynamic semantics. Experiments on DIVE show that GRT outperforms larger VLLM baselines and scales positively with FPS. These results highlight the importance of dense temporal information and demonstrate that GRT enables efficient, scalable high-FPS video understanding.