MapAnything: Universal Feed-Forward Metric 3D Reconstruction
作者: Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bulò, Christian Richardt, Deva Ramanan, Sebastian Scherer, Peter Kontschieder
分类: cs.CV, cs.AI, cs.LG, cs.RO
发布日期: 2025-09-16 (更新: 2026-01-23)
备注: 3DV 2026. Project Page: https://map-anything.github.io/
💡 一句话要点
MapAnything:通用前馈度量3D重建模型,统一解决多种3D视觉任务
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 Transformer网络 多视图几何 深度估计 相机定位 通用模型 度量重建
📋 核心要点
- 现有3D重建方法通常针对特定任务设计,缺乏通用性和联合训练能力。
- MapAnything采用基于Transformer的前馈网络,统一处理多种几何输入,直接回归度量3D场景。
- 实验表明,MapAnything在多种3D视觉任务上表现优异,并具备高效的联合训练能力。
📝 摘要(中文)
本文提出MapAnything,一个统一的基于Transformer的前馈模型,它接收单张或多张图像以及可选的几何输入(如相机内参、位姿、深度或部分重建),然后直接回归度量3D场景几何和相机。MapAnything利用多视图场景几何的分解表示,即深度图、局部光线图、相机位姿和度量比例因子集合,有效地将局部重建升级为全局一致的度量框架。通过标准化跨不同数据集的监督和训练,以及灵活的输入增强,MapAnything能够通过单个前馈过程解决广泛的3D视觉任务,包括未校准的运动结构恢复、校准的多视图立体、单目深度估计、相机定位、深度补全等。我们提供了广泛的实验分析和模型消融研究,表明MapAnything优于或匹配专门的前馈模型,同时提供更有效的联合训练行为,从而为通用3D重建骨干网络铺平了道路。
🔬 方法详解
问题定义:现有3D重建方法通常是任务特定的,例如,运动结构恢复、多视图立体、单目深度估计等都需要单独的模型和训练流程。这些方法难以进行联合训练,无法充分利用不同任务之间的互补信息。此外,现有方法在处理不同类型的几何输入时缺乏灵活性。
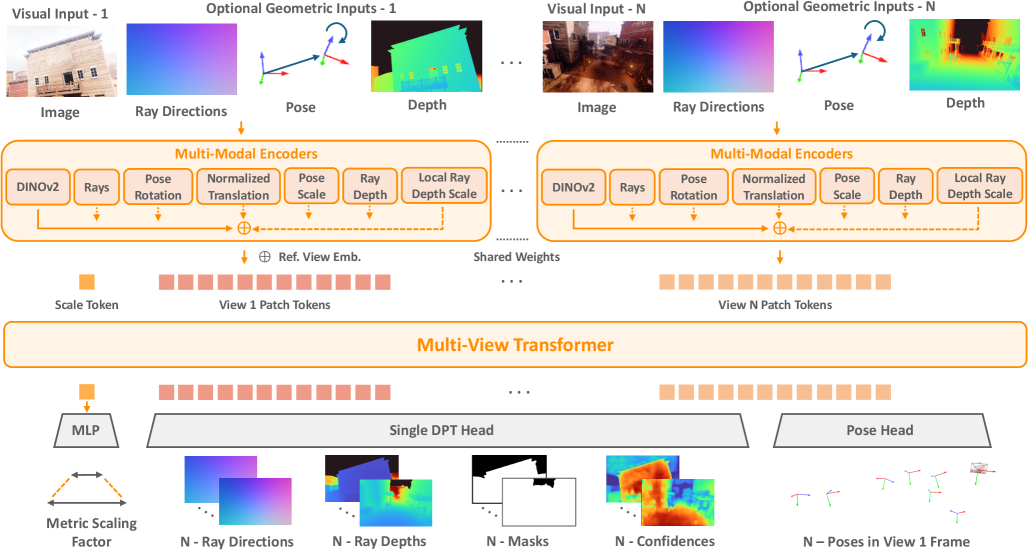
核心思路:MapAnything的核心思路是构建一个通用的前馈模型,能够处理多种类型的几何输入(如图像、相机参数、深度图等),并直接回归度量3D场景几何和相机位姿。通过使用Transformer架构,模型可以学习不同输入之间的关系,并进行有效的特征融合。
技术框架:MapAnything的整体架构包括以下几个主要模块:1) 输入编码器:将图像和几何输入编码成特征向量。2) Transformer网络:学习不同特征之间的关系,并进行特征融合。3) 解码器:将融合后的特征解码成深度图、局部光线图、相机位姿和度量比例因子等。4) 度量重建模块:将局部重建结果升级为全局一致的度量框架。
关键创新:MapAnything的关键创新在于其通用性和灵活性。它能够处理多种类型的几何输入,并解决多种3D视觉任务,而无需针对特定任务进行定制。此外,MapAnything采用基于Transformer的架构,能够有效地学习不同输入之间的关系,并进行特征融合。
关键设计:MapAnything的关键设计包括:1) 使用Transformer网络进行特征融合。2) 采用分解表示来表示多视图场景几何。3) 标准化跨不同数据集的监督和训练。4) 灵活的输入增强策略。损失函数包括深度损失、位姿损失和尺度损失等。网络结构细节包括Transformer的层数、头数和隐藏层大小等。
🖼️ 关键图片


📊 实验亮点
MapAnything在多个3D视觉任务上取得了优异的性能。例如,在未校准的运动结构恢复任务中,MapAnything的重建精度优于现有的专门模型。在多视图立体任务中,MapAnything的重建质量与最先进的方法相当。此外,MapAnything还展示了高效的联合训练能力,可以在多个数据集上进行训练,并提高整体性能。
🎯 应用场景
MapAnything具有广泛的应用前景,包括机器人导航、自动驾驶、增强现实、虚拟现实、三维地图构建等领域。它可以作为通用3D重建骨干网络,为各种3D视觉应用提供基础支持。该研究的实际价值在于降低了开发和部署3D视觉应用的成本,并提高了3D重建的效率和精度。未来,MapAnything可以进一步扩展到处理更大规模的场景和更复杂的几何结构。
📄 摘要(原文)
We introduce MapAnything, a unified transformer-based feed-forward model that ingests one or more images along with optional geometric inputs such as camera intrinsics, poses, depth, or partial reconstructions, and then directly regresses the metric 3D scene geometry and cameras. MapAnything leverages a factored representation of multi-view scene geometry, i.e., a collection of depth maps, local ray maps, camera poses, and a metric scale factor that effectively upgrades local reconstructions into a globally consistent metric frame. Standardizing the supervision and training across diverse datasets, along with flexible input augmentation, enables MapAnything to address a broad range of 3D vision tasks in a single feed-forward pass, including uncalibrated structure-from-motion, calibrated multi-view stereo, monocular depth estimation, camera localization, depth completion, and more. We provide extensive experimental analyses and model ablations demonstrating that MapAnything outperforms or matches specialist feed-forward models while offering more efficient joint training behavior, thus paving the way toward a universal 3D reconstruction backbone.