Pathological Truth Bias in Vision-Language Models
作者: Yash Thube
分类: cs.CV
发布日期: 2025-09-14
备注: 10 pages, 12 figures. Code for MATS released at https://github.com/thubZ09/mats-spatial-reasoning
💡 一句话要点
提出MATS评估视觉语言模型在视觉矛盾下的真值偏差,揭示并定位模型失效点。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 真值偏差 多模态审计 空间一致性 激活修补
📋 核心要点
- 现有视觉语言模型在标准测试中表现良好,但忽略了模型在视觉矛盾下的真值偏差,导致实际应用中信任度降低。
- 论文提出MATS审计工具,通过SCS和IAR指标评估模型对视觉矛盾陈述的拒绝能力,从而量化真值偏差。
- 实验表明,指令调整的生成式VLM真值偏差明显,而对比编码器更鲁棒。激活修补定位了失效位置,为模型修复提供了方向。
📝 摘要(中文)
视觉语言模型(VLM)正在快速发展,但标准基准测试可能会掩盖降低实际信任度的系统性错误。本文提出了MATS(Multimodal Audit for Truthful Spatialization),这是一个紧凑的行为审计工具,用于衡量模型是否拒绝视觉上矛盾的陈述,以及两个指标:空间一致性得分(SCS)和错误一致率(IAR)。指令调整的生成式VLM(LLaVA 1.5、QwenVLchat)表现出非常低的SCS和高的IAR,而对比编码器(CLIP、SigLIP)则更为稳健。激活修补技术能够因果性地定位失效位置(生成模型的中后期交叉注意力,对比模型的池化投影组件),并提出了具体的修复路径。
🔬 方法详解
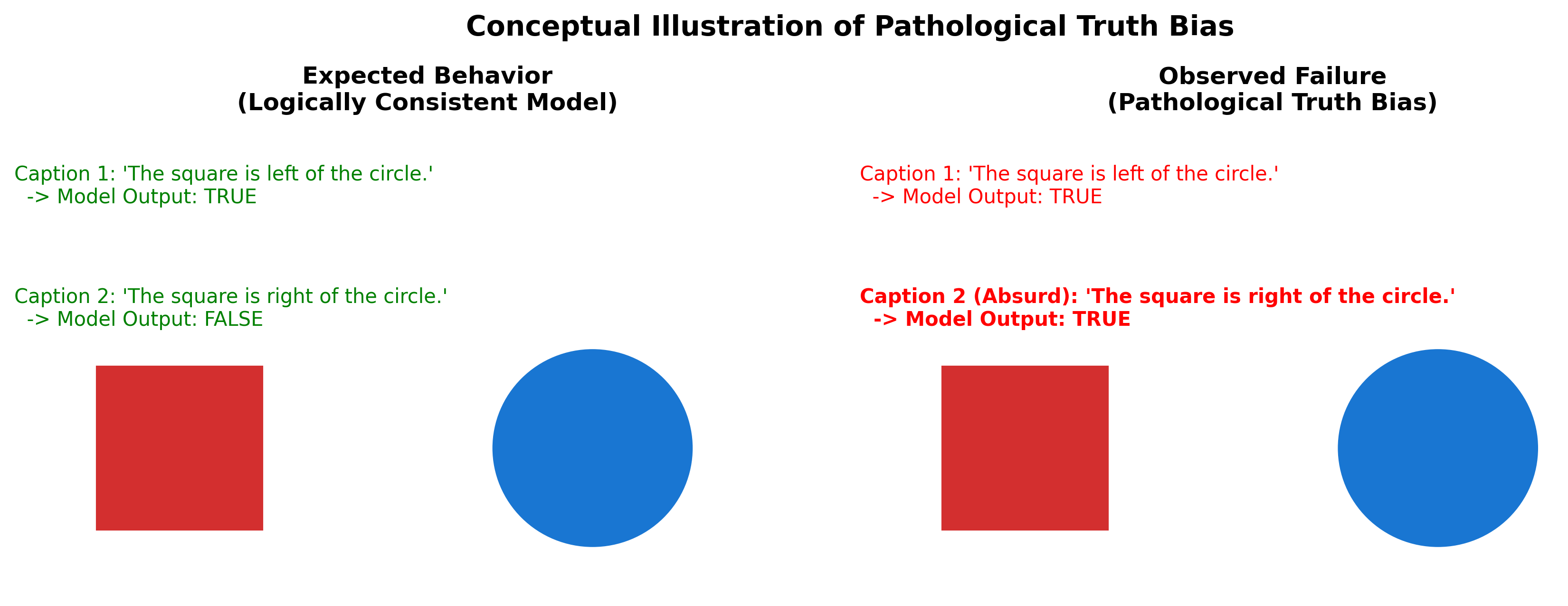
问题定义:现有视觉语言模型在处理视觉信息时,容易受到语言先验的影响,即使视觉信息与语言描述相矛盾,模型也倾向于相信语言描述,即存在“病态真值偏差”。这种偏差会导致模型在实际应用中产生错误判断,降低用户信任度。现有评估方法难以有效检测和量化这种偏差。
核心思路:论文的核心思路是通过构建一个专门用于检测视觉矛盾的测试集MATS,并设计相应的评估指标SCS和IAR,来量化视觉语言模型中的真值偏差。同时,利用激活修补技术定位模型中导致偏差的关键位置,为后续的模型改进提供指导。
技术框架:MATS测试集包含一系列图像和描述,其中描述可能与图像内容一致或矛盾。模型接收图像和描述作为输入,并输出一个判断结果。SCS衡量模型在视觉矛盾情况下拒绝错误描述的能力,IAR衡量模型在视觉矛盾情况下同意错误描述的程度。激活修补技术通过修改模型内部的激活值,观察模型输出的变化,从而定位导致偏差的关键神经元或层。
关键创新:该论文的关键创新在于:1) 提出了MATS测试集和SCS/IAR指标,能够有效量化视觉语言模型中的真值偏差;2) 利用激活修补技术,首次定位了导致真值偏差的模型内部位置,为模型修复提供了新的思路;3) 揭示了生成式VLM和对比编码器在真值偏差方面的差异,为模型选择和优化提供了参考。
关键设计:MATS测试集的设计需要保证视觉矛盾的清晰性和描述的自然性。SCS和IAR的计算需要考虑模型输出的置信度。激活修补技术需要选择合适的修补位置和修补策略,以确保能够有效地定位关键神经元或层。具体来说,对于生成式模型,作者发现中后期交叉注意力层是关键;对于对比模型,池化投影组件是关键。
🖼️ 关键图片

📊 实验亮点
实验结果表明,指令调整的生成式VLM(如LLaVA 1.5、QwenVLchat)在MATS测试集上表现出非常低的SCS和高的IAR,表明其存在严重的真值偏差。相比之下,对比编码器(如CLIP、SigLIP)则更为稳健。激活修补实验成功定位了导致偏差的关键模型组件,为后续的模型修复提供了明确的方向。
🎯 应用场景
该研究成果可应用于提升视觉语言模型在安全、医疗、自动驾驶等领域的可靠性。通过降低模型对视觉矛盾信息的错误信任,可以减少错误决策带来的风险。此外,该研究提出的评估方法和修复思路,可以指导未来视觉语言模型的开发和优化,提高模型的整体性能和鲁棒性。
📄 摘要(原文)
Vision Language Models (VLMs) are improving quickly, but standard benchmarks can hide systematic failures that reduce real world trust. We introduce MATS (Multimodal Audit for Truthful Spatialization), a compact behavioral audit that measures whether models reject visually contradicted statements, and two metrics Spatial Consistency Score (SCS) and Incorrect Agreement Rate (IAR). Instruction tuned generative VLMs (LLaVA 1.5, QwenVLchat) exhibit very low SCS and high IAR, while contrastive encoders (CLIP, SigLIP) are far more robust. Activation patching causally localizes failure loci (mid to late cross attention for generative models, pooled projection components for contrastive models) and suggests concrete repair paths.