Traffic-MLLM: A Spatio-Temporal MLLM with Retrieval-Augmented Generation for Causal Inference in Traffic
作者: Waikit Xiu, Qiang Lu, Xiying Li, Chen Hu, Shengbo Sun
分类: cs.CV
发布日期: 2025-09-14
💡 一句话要点
Traffic-MLLM:融合检索增强生成的时空多模态大语言模型,用于交通因果推理
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 交通视频理解 因果推理 检索增强生成 知识注入
📋 核心要点
- 现有交通视频理解方法难以准确建模时空因果关系,且缺乏领域知识整合能力,限制了其在复杂交通场景中的应用。
- Traffic-MLLM通过高质量交通数据集微调Qwen2.5-VL,并结合CoT和RAG,实现领域知识注入,提升模型推理能力。
- 实验表明,Traffic-MLLM在TrafficQA和DriveQA上达到SOTA,并展现出优秀的零样本推理和跨场景泛化能力。
📝 摘要(中文)
随着智能交通系统的发展,交通视频理解在全面的场景感知和因果分析中扮演着越来越关键的角色。然而,现有方法在准确建模时空因果关系和整合领域特定知识方面面临着显著的挑战,限制了它们在复杂场景中的有效性。为了解决这些限制,我们提出了Traffic-MLLM,一个为精细交通分析量身定制的多模态大语言模型。该模型基于Qwen2.5-VL骨干网络,利用高质量的交通特定多模态数据集,并使用低秩适应(LoRA)进行轻量级微调,显著增强了其建模视频序列中连续时空特征的能力。此外,我们引入了一个创新的知识提示模块,将思维链(CoT)推理与检索增强生成(RAG)融合,从而能够将详细的交通规则和领域知识精确地注入到推理过程中。这种设计显著提高了模型的逻辑推理和知识适应能力。在TrafficQA和DriveQA基准测试上的实验结果表明,Traffic-MLLM实现了最先进的性能,验证了其处理多模态交通数据的卓越能力。它还表现出卓越的零样本推理和跨场景泛化能力。
🔬 方法详解
问题定义:现有交通视频理解方法难以准确建模交通场景中的时空因果关系,并且缺乏有效整合交通规则等领域知识的能力。这导致模型在复杂交通场景下的推理和决策能力不足,无法满足智能交通系统对精细化场景理解和因果分析的需求。
核心思路:Traffic-MLLM的核心思路是利用多模态大语言模型强大的表征学习和推理能力,结合高质量的交通领域数据进行微调,并通过检索增强生成(RAG)的方式将交通规则等领域知识注入到模型中,从而提升模型在交通场景下的理解和推理能力。这样设计的目的是为了弥补现有方法在时空因果关系建模和领域知识整合方面的不足。
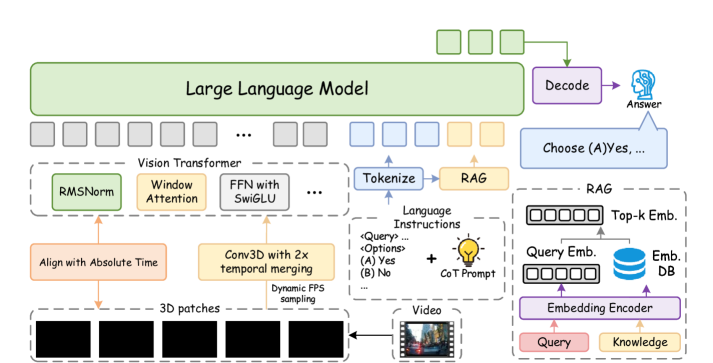
技术框架:Traffic-MLLM的整体架构基于Qwen2.5-VL多模态大语言模型。主要包含以下几个模块:1) 视觉编码器:用于提取交通视频中的视觉特征。2) 语言模型:基于Qwen2.5-VL,负责进行文本理解和生成。3) 低秩适应(LoRA)微调模块:利用高质量的交通领域多模态数据集对模型进行轻量级微调,提升模型对交通场景的理解能力。4) 知识提示模块:融合了思维链(CoT)推理和检索增强生成(RAG),用于将交通规则等领域知识注入到模型中。
关键创新:Traffic-MLLM的关键创新在于其知识提示模块,该模块将思维链(CoT)推理与检索增强生成(RAG)相结合,实现了领域知识的精确注入。与传统的知识注入方法相比,该方法能够更有效地利用外部知识,提升模型的逻辑推理和知识适应能力。此外,使用LoRA进行轻量级微调,降低了计算成本,使得模型更容易部署和应用。
关键设计:在LoRA微调过程中,采用了高质量的交通领域多模态数据集,包括TrafficQA和DriveQA等。知识提示模块中,RAG部分使用了领域知识库,包含了详细的交通规则和法规。CoT推理部分则通过设计合适的提示词,引导模型进行逐步推理。损失函数方面,采用了交叉熵损失函数,用于优化模型的生成能力。
🖼️ 关键图片

📊 实验亮点
Traffic-MLLM在TrafficQA和DriveQA基准测试上取得了最先进的性能,验证了其处理多模态交通数据的卓越能力。相较于现有方法,Traffic-MLLM在TrafficQA上取得了显著的性能提升,并在DriveQA上展现出强大的竞争力。此外,Traffic-MLLM还表现出卓越的零样本推理和跨场景泛化能力,表明其具有很强的实际应用潜力。
🎯 应用场景
Traffic-MLLM可应用于智能交通系统的多个领域,如自动驾驶、交通监控、交通事件检测和交通流量预测。通过对交通视频进行精细化分析和因果推理,可以提升自动驾驶系统的安全性,提高交通监控系统的效率,并为交通管理部门提供决策支持。该研究的未来影响在于推动智能交通系统向更智能、更安全、更高效的方向发展。
📄 摘要(原文)
As intelligent transportation systems advance, traffic video understanding plays an increasingly pivotal role in comprehensive scene perception and causal analysis. Yet, existing approaches face notable challenges in accurately modeling spatiotemporal causality and integrating domain-specific knowledge, limiting their effectiveness in complex scenarios. To address these limitations, we propose Traffic-MLLM, a multimodal large language model tailored for fine-grained traffic analysis. Built on the Qwen2.5-VL backbone, our model leverages high-quality traffic-specific multimodal datasets and uses Low-Rank Adaptation (LoRA) for lightweight fine-tuning, significantly enhancing its capacity to model continuous spatiotemporal features in video sequences. Furthermore, we introduce an innovative knowledge prompting module fusing Chain-of-Thought (CoT) reasoning with Retrieval-Augmented Generation (RAG), enabling precise injection of detailed traffic regulations and domain knowledge into the inference process. This design markedly boosts the model's logical reasoning and knowledge adaptation capabilities. Experimental results on TrafficQA and DriveQA benchmarks show Traffic-MLLM achieves state-of-the-art performance, validating its superior ability to process multimodal traffic data. It also exhibits remarkable zero-shot reasoning and cross-scenario generalization capabilities.