Mars Traversability Prediction: A Multi-modal Self-supervised Approach for Costmap Generation
作者: Zongwu Xie, Kaijie Yun, Yang Liu, Yiming Ji, Han Li
分类: cs.CV, cs.RO
发布日期: 2025-09-14
💡 一句话要点
提出一种多模态自监督方法,用于火星车地形 traversability costmap 生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 火星探测 Traversability Costmap 多模态融合 自监督学习 DINOv3 FiLM 机器人导航
📋 核心要点
- 现有方法在行星探测车 traversability costmap 生成方面存在不足,尤其是在多模态数据融合和自监督学习方面。
- 该论文提出了一种基于 DINOv3 图像编码器和 FiLM 传感器融合的多模态自监督框架,用于预测 traversability costmap。
- 实验结果表明,该模型在各种干扰条件下表现出高度的鲁棒性,并提供了一个高保真仿真环境和自监督标注流程。
📝 摘要(中文)
本文提出了一种鲁棒的多模态框架,用于预测行星漫游车的 traversability costmap。该模型融合了相机和激光雷达数据,生成鸟瞰图(BEV)地形 costmap,并使用 IMU 导出的标签进行自监督训练。关键更新包括基于 DINOv3 的图像编码器、基于 FiLM 的传感器融合以及结合 Huber 损失和平滑项的优化损失。实验消融研究(移除图像颜色、遮挡输入、添加噪声)表明,MAE/MSE 仅有微小变化(例如,当激光雷达稀疏化时,MAE 从约 0.0775 增加到 0.0915),表明几何信息主导了学习到的 cost,并且模型具有很高的鲁棒性。我们将性能差异小归因于 IMU 标签主要反映地形几何形状而非语义信息,以及数据多样性有限。与先前声称取得巨大收益的工作不同,我们强调我们的贡献:(1) 高保真、可复现的仿真环境;(2) 基于 IMU 的自监督标注流程;(3) 强大的多模态 BEV costmap 预测模型。我们讨论了局限性以及未来的工作,例如领域泛化和数据集扩展。
🔬 方法详解
问题定义:论文旨在解决行星探测车在复杂地形中导航时,如何准确预测 traversability costmap 的问题。现有方法通常依赖人工标注数据或简单的几何模型,难以适应火星等复杂环境,且多模态数据融合效果不佳。
核心思路:论文的核心思路是利用自监督学习,从 IMU 数据中提取 traversability 的标签,并结合相机和激光雷达等多模态数据,训练一个能够预测 BEV costmap 的模型。通过这种方式,可以减少对人工标注数据的依赖,并充分利用不同传感器提供的信息。
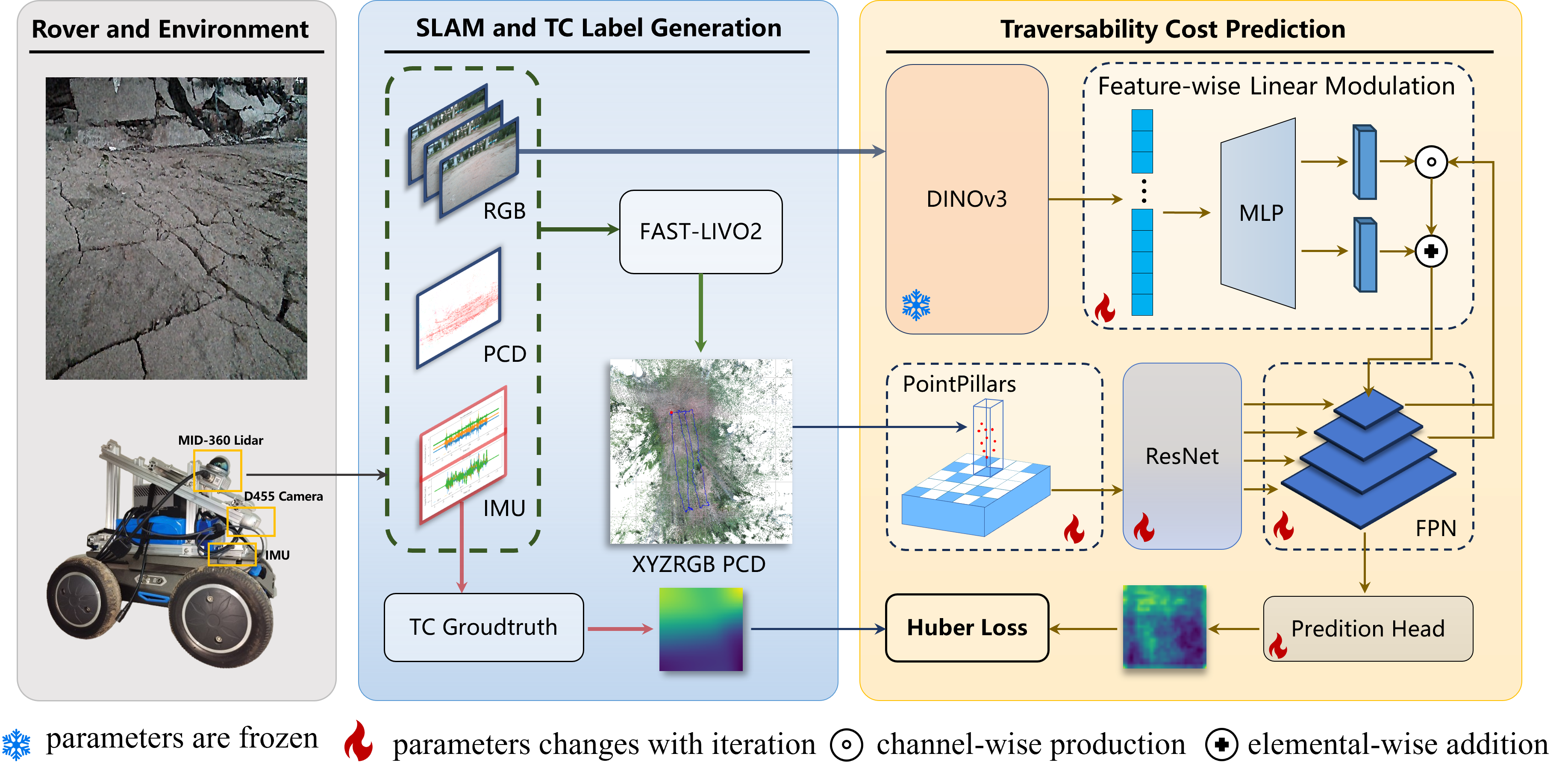
技术框架:整体框架包含以下几个主要模块:1) 基于 DINOv3 的图像编码器,用于提取图像特征;2) 激光雷达数据处理模块,将点云数据转换为 BEV 表示;3) 基于 FiLM 的传感器融合模块,将图像和激光雷达特征进行融合;4) costmap 预测模块,根据融合后的特征预测 BEV costmap;5) 自监督训练模块,使用 IMU 数据生成的标签进行训练。
关键创新:论文的关键创新在于:1) 提出了一种基于 IMU 数据的自监督标注流程,无需人工标注即可生成训练标签;2) 使用 DINOv3 预训练模型作为图像编码器,提高了图像特征的提取能力;3) 采用 FiLM 进行多模态特征融合,能够有效地整合不同传感器的数据。
关键设计:在技术细节上,论文采用了 Huber 损失和平滑项相结合的优化损失函数,以提高 costmap 的预测精度和平滑性。此外,论文还构建了一个高保真度的仿真环境,用于生成训练数据和评估模型性能。DINOv3 图像编码器的具体参数设置和 FiLM 融合模块的结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该模型在各种干扰条件下表现出高度的鲁棒性。例如,当激光雷达数据稀疏化时,MAE 仅从约 0.0775 增加到 0.0915,表明模型对几何信息具有很强的依赖性。此外,该论文还提供了一个高保真、可复现的仿真环境,为后续研究提供了便利。
🎯 应用场景
该研究成果可应用于火星探测车、月球车等行星探测任务中,提高探测车在复杂地形中的导航能力和自主性。此外,该方法也可应用于地面机器人、自动驾驶等领域,提升机器人在复杂环境中的感知和决策能力。未来,通过领域泛化和数据集扩展,该方法有望在更广泛的场景中得到应用。
📄 摘要(原文)
We present a robust multi-modal framework for predicting traversability costmaps for planetary rovers. Our model fuses camera and LiDAR data to produce a bird's-eye-view (BEV) terrain costmap, trained self-supervised using IMU-derived labels. Key updates include a DINOv3-based image encoder, FiLM-based sensor fusion, and an optimization loss combining Huber and smoothness terms. Experimental ablations (removing image color, occluding inputs, adding noise) show only minor changes in MAE/MSE (e.g. MAE increases from ~0.0775 to 0.0915 when LiDAR is sparsified), indicating that geometry dominates the learned cost and the model is highly robust. We attribute the small performance differences to the IMU labeling primarily reflecting terrain geometry rather than semantics and to limited data diversity. Unlike prior work claiming large gains, we emphasize our contributions: (1) a high-fidelity, reproducible simulation environment; (2) a self-supervised IMU-based labeling pipeline; and (3) a strong multi-modal BEV costmap prediction model. We discuss limitations and future work such as domain generalization and dataset expansion.