Rate-Distortion Limits for Multimodal Retrieval: Theory, Optimal Codes, and Finite-Sample Guarantees
作者: Thomas Y. Chen
分类: cs.IT, cs.CV
发布日期: 2025-09-14
备注: ICCV MRR 2025
💡 一句话要点
为多模态检索建立信息论极限,提出最优编码方案并提供有限样本保证。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 率失真理论 信息论极限 熵编码 对比学习 有限样本分析 自适应编码
📋 核心要点
- 现有多模态检索方法缺乏理论指导,难以确定最优的编码位数以实现高质量检索。
- 论文提出了一种熵加权随机量化器,并结合自适应温度解码器,逼近理论上的率失真极限。
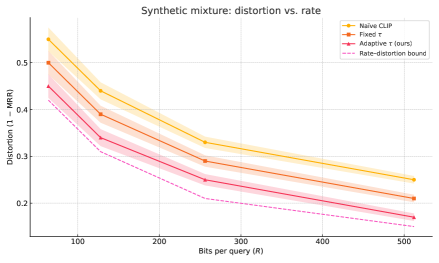
- 实验表明,该方法在性能上接近理论最优,显著优于固定温度和朴素CLIP等基线方法。
📝 摘要(中文)
本文为多模态检索建立了首个信息论极限。将排序问题建模为有损源编码,推导了倒数排序失真下的单字母率失真函数R(D),并证明了一个逆界,该逆界分解为一个模态平衡项加上一个倾斜惩罚项κΔH,用于捕获熵不平衡和跨模态冗余。然后,构建了一个显式的熵加权随机量化器,该量化器具有自适应的、每个模态的温度解码器;Blahut-Arimoto论证表明,该方案使用n个训练三元组,在R(D)的O(n^{-1})范围内实现了失真。VC类型的分析产生了第一个有限样本超额风险界,其复杂度以亚线性的方式缩放模态数量和熵差距。在受控高斯混合和Flickr30k上的实验证实,我们的自适应代码位于理论前沿的两个百分点内,而固定温度和朴素的CLIP基线则明显滞后。总而言之,我们的结果为高质量多模态检索的“每个查询需要多少位”提供了一个原则性的答案,并为熵感知对比目标、持续学习检索器和检索增强生成器提供了设计指导。
🔬 方法详解
问题定义:论文旨在解决多模态检索中的信息论极限问题,即在给定失真度的情况下,每个查询需要多少位信息才能实现高质量的检索。现有方法缺乏理论指导,难以确定最优的编码位数,并且忽略了不同模态之间的熵不平衡和冗余性,导致检索性能受限。
核心思路:论文将多模态检索问题建模为有损源编码问题,利用率失真理论来分析检索性能的理论极限。核心思想是设计一种能够有效压缩多模态信息,同时保持检索性能的编码方案。通过最小化率失真函数,可以找到最优的编码位数和失真度之间的平衡。
技术框架:论文提出的技术框架主要包括以下几个模块:1) 率失真函数推导:推导了倒数排序失真下的单字母率失真函数R(D),该函数描述了在给定失真度D的情况下,所需的最小信息率R。2) 熵加权随机量化器:设计了一种熵加权随机量化器,用于将多模态信息编码成离散的码本。3) 自适应温度解码器:设计了一种自适应的、每个模态的温度解码器,用于从码本中解码出多模态信息。4) 有限样本分析:利用VC理论,对所提出的编码方案进行了有限样本分析,得到了超额风险界。
关键创新:论文的关键创新点在于:1) 首次为多模态检索建立了信息论极限,为该领域的研究提供了理论基础。2) 提出了一种熵加权随机量化器,能够有效地压缩多模态信息,同时保持检索性能。3) 设计了一种自适应温度解码器,能够根据不同模态的熵值动态调整解码参数,从而提高检索性能。4) 提供了有限样本保证,证明了所提出的编码方案在有限样本下的有效性。
关键设计:论文的关键设计包括:1) 熵加权:在量化过程中,根据不同模态的熵值对码本进行加权,使得熵值较高的模态能够获得更多的编码位数。2) 自适应温度:在解码过程中,根据不同模态的熵值动态调整温度参数,从而控制解码的平滑程度。3) 损失函数:采用倒数排序失真作为损失函数,该损失函数能够更好地反映检索性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,论文提出的自适应编码方案在受控高斯混合和Flickr30k数据集上均表现出色,性能接近理论前沿,与理论最优值相差不超过两个百分点。相比之下,固定温度和朴素的CLIP基线方法则明显落后,验证了自适应编码方案的有效性。
🎯 应用场景
该研究成果可应用于多种多模态检索场景,例如图像-文本检索、视频-文本检索等。通过指导熵感知对比目标的构建,可以提升检索系统的性能。此外,该研究还可应用于持续学习检索器和检索增强生成器,提高系统的适应性和生成质量。该研究为多模态检索系统的设计和优化提供了理论指导。
📄 摘要(原文)
We establish the first information-theoretic limits for multimodal retrieval. Casting ranking as lossy source coding, we derive a single-letter rate-distortion function $R(D)$ for reciprocal-rank distortion and prove a converse bound that splits into a modality-balanced term plus a skew penalty $κ\,ΔH$ capturing entropy imbalance and cross-modal redundancy. We then construct an explicit entropy-weighted stochastic quantizer with an adaptive, per-modality temperature decoder; a Blahut-Arimoto argument shows this scheme achieves distortion within $O(n^{-1})$ of $R(D)$ using $n$ training triples. A VC-type analysis yields the first finite-sample excess-risk bound whose complexity scales sub-linearly in both the number of modalities and the entropy gap. Experiments on controlled Gaussian mixtures and Flickr30k confirm that our adaptive codes sit within two percentage points of the theoretical frontier, while fixed-temperature and naive CLIP baselines lag significantly. Taken together, our results give a principled answer to "how many bits per query are necessary" for high-quality multimodal retrieval and provide design guidance for entropy-aware contrastive objectives, continual-learning retrievers, and retrieval-augmented generators.