Lightweight Metadata-Aware Mixture-of-Experts Masked Autoencoder for Earth Observation
作者: Mohanad Albughdadi
分类: cs.CV, cs.LG
发布日期: 2025-09-13
💡 一句话要点
提出元数据感知的轻量级混合专家掩码自编码器,用于高效地球观测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 地球观测 掩码自编码器 混合专家模型 元数据感知 轻量级模型
📋 核心要点
- 现有地球观测模型计算成本高,限制了其可访问性和下游任务的复用。
- 提出元数据感知的混合专家掩码自编码器,结合稀疏路由和地理时序信息。
- 实验表明,该模型在参数量小的情况下,性能可与大型模型竞争,提升了迁移能力。
📝 摘要(中文)
本文提出了一种轻量级的元数据感知混合专家掩码自编码器(MoE-MAE),仅包含250万参数,旨在解决地球观测领域大型基础模型计算成本高昂的问题。该模型结合了稀疏专家路由和地理时序条件,将图像与经纬度以及季节/每日循环编码相结合。MoE-MAE在BigEarthNet-Landsat数据集上进行预训练,并使用线性探针评估其冻结编码器的嵌入。实验结果表明,尽管模型体积小,但其性能可与更大的架构相媲美,证明了元数据感知的预训练能够提高迁移能力和标签效率。在缺乏显式元数据的EuroSAT-Landsat数据集上的评估也显示出与具有数亿参数的模型相比具有竞争力的性能。这些结果表明,紧凑的、元数据感知的MoE-MAE是未来地球观测基础模型高效且可扩展的一步。
🔬 方法详解
问题定义:地球观测领域的大型基础模型虽然性能强大,但计算资源需求高昂,难以部署和应用。现有方法缺乏对地球观测数据中固有元数据(如地理位置、时间信息)的有效利用,限制了模型的泛化能力和效率。
核心思路:本文的核心思路是设计一个轻量级的模型,同时利用地球观测数据的元数据信息来提升模型的性能和泛化能力。通过结合混合专家模型(MoE)的稀疏激活特性和元数据条件输入,在保证模型容量的同时降低计算成本。
技术框架:该模型是一个掩码自编码器(MAE),包含一个编码器和一个解码器。编码器接收部分掩码的图像块和对应的元数据信息作为输入。元数据信息包括经纬度坐标和时间信息(季节/每日循环编码)。编码器的输出经过一个混合专家层(MoE),该层根据输入选择性地激活不同的专家网络。解码器接收编码器的输出,重建原始图像。
关键创新:该论文的关键创新在于将混合专家模型(MoE)与元数据信息相结合。MoE允许模型拥有更大的容量,同时保持较低的计算成本,因为每次只激活部分专家。元数据信息的引入使得模型能够更好地理解地球观测数据的时空特性,从而提高模型的性能和泛化能力。
关键设计:模型使用Transformer作为编码器和解码器的基本构建块。混合专家层使用可学习的路由函数来选择激活哪些专家。损失函数是重建图像与原始图像之间的均方误差。元数据信息通过嵌入层转换为向量,并与图像块的嵌入向量拼接后输入到编码器中。
🖼️ 关键图片

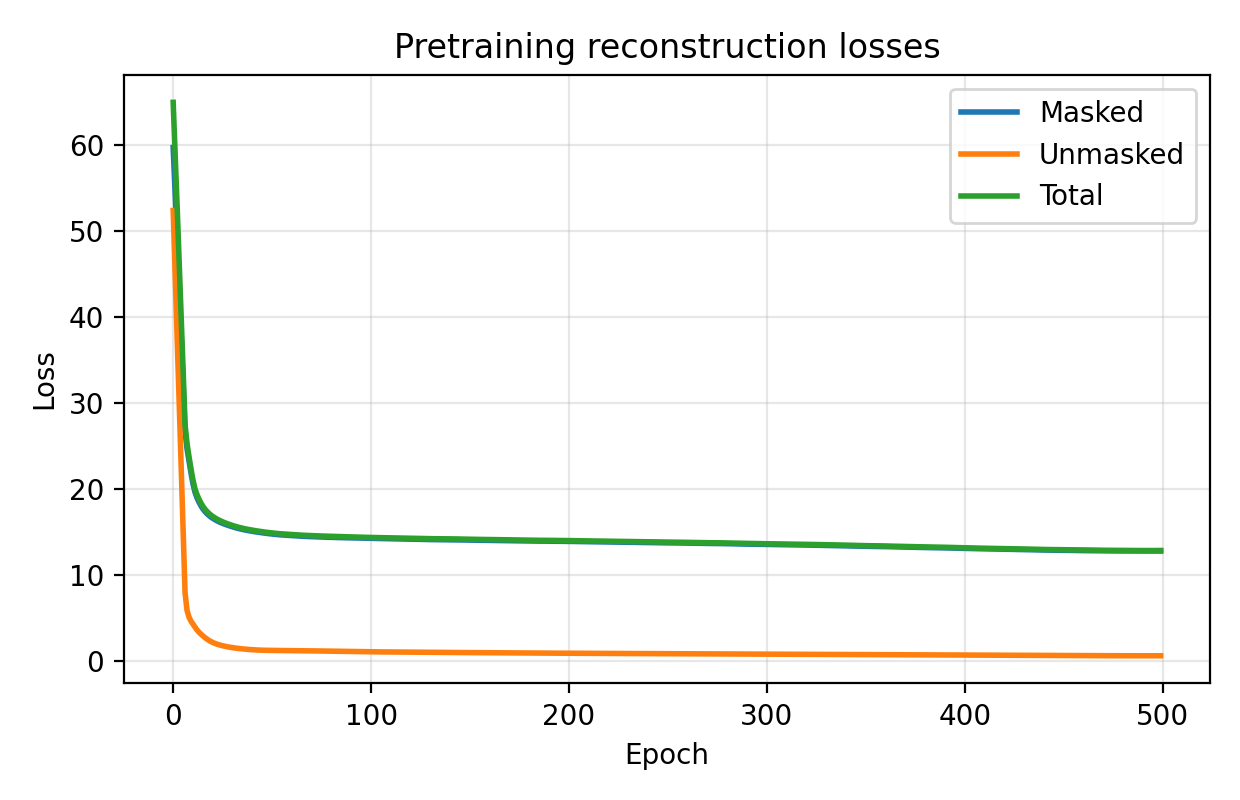
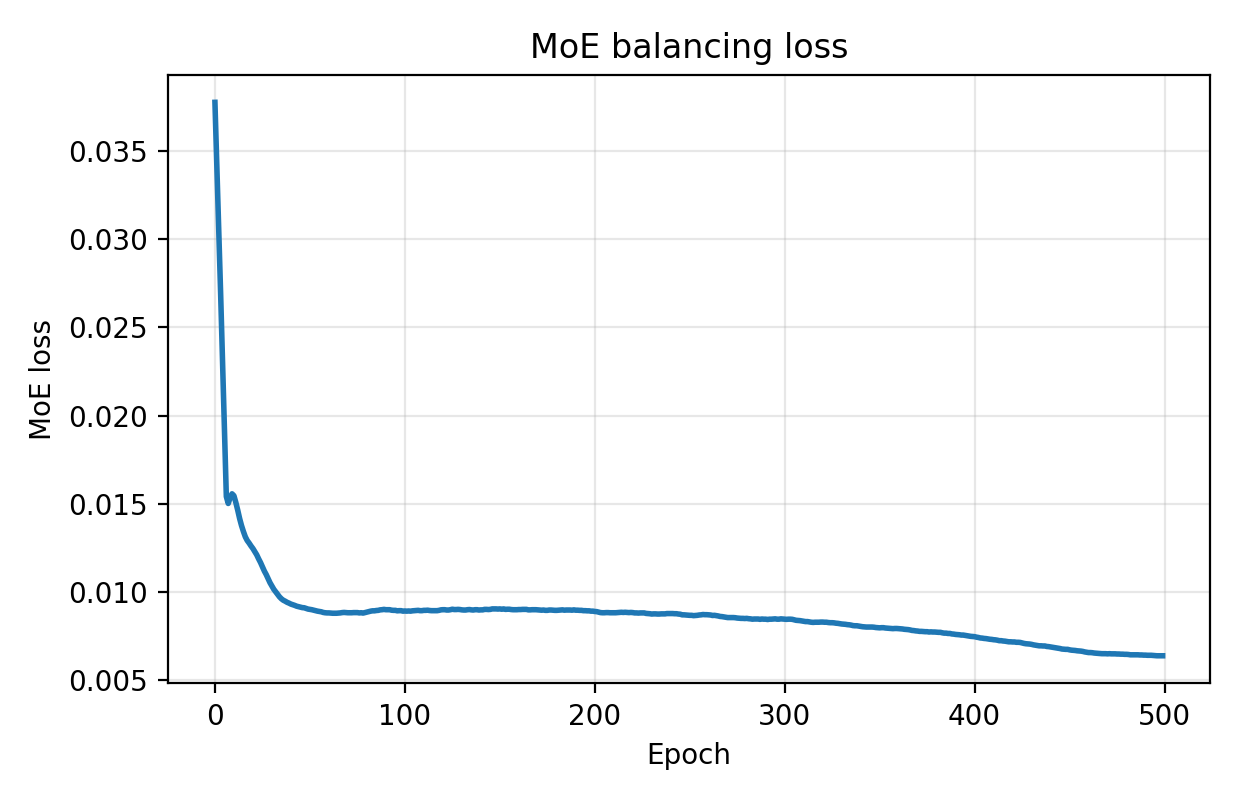
📊 实验亮点
实验结果表明,该模型在BigEarthNet-Landsat数据集上预训练后,在EuroSAT-Landsat数据集上进行评估,即使EuroSAT-Landsat数据集缺乏显式元数据,该模型仍然表现出与具有数亿参数的模型相比具有竞争力的性能。这证明了元数据感知的预训练能够提高模型的泛化能力和标签效率,并且轻量级模型也能达到甚至超过大型模型的性能。
🎯 应用场景
该研究成果可应用于遥感图像分类、目标检测、场景分割等多种地球观测任务。轻量级模型更易于部署在资源受限的设备上,例如无人机或边缘计算平台。元数据感知的预训练方法可以提高模型在不同地理区域和时间段的泛化能力,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Recent advances in Earth Observation have focused on large-scale foundation models. However, these models are computationally expensive, limiting their accessibility and reuse for downstream tasks. In this work, we investigate compact architectures as a practical pathway toward smaller general-purpose EO models. We propose a Metadata-aware Mixture-of-Experts Masked Autoencoder (MoE-MAE) with only 2.5M parameters. The model combines sparse expert routing with geo-temporal conditioning, incorporating imagery alongside latitude/longitude and seasonal/daily cyclic encodings. We pretrain the MoE-MAE on the BigEarthNet-Landsat dataset and evaluate embeddings from its frozen encoder using linear probes. Despite its small size, the model competes with much larger architectures, demonstrating that metadata-aware pretraining improves transfer and label efficiency. To further assess generalization, we evaluate on the EuroSAT-Landsat dataset, which lacks explicit metadata, and still observe competitive performance compared to models with hundreds of millions of parameters. These results suggest that compact, metadata-aware MoE-MAEs are an efficient and scalable step toward future EO foundation models.