Adapting Medical Vision Foundation Models for Volumetric Medical Image Segmentation via Active Learning and Selective Semi-supervised Fine-tuning
作者: Jin Yang, Daniel S. Marcus, Aristeidis Sotiras
分类: eess.IV, cs.CV
发布日期: 2025-09-13 (更新: 2025-10-21)
备注: 17 pages, 5 figures, 8 tables
💡 一句话要点
提出ASFDA方法,通过主动学习和选择性半监督微调,高效适配医学视觉基础模型用于体积医学图像分割。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像分割 主动学习 领域自适应 半监督学习 医学视觉基础模型
📋 核心要点
- 现有方法随机选择样本微调医学视觉基础模型,忽略了样本的信息量,导致适配效率低下。
- ASFDA方法通过主动学习选择信息量大的样本进行微调,并结合选择性半监督微调,提高适配效率和性能。
- 该方法设计了DKD和ASD两种查询指标,分别衡量源域-目标域知识差距和解剖分割难度,指导样本选择。
📝 摘要(中文)
医学视觉基础模型(Med-VFMs)通过大量无标注图像的自监督预训练,具备卓越的医学图像理解能力。为了提高它们在下游自适应评估(特别是分割任务)上的性能,通常会随机选择目标领域的一些样本进行微调。然而,缺乏研究探索如何高效地适配Med-VFMs,以在目标领域上实现最佳性能。因此,迫切需要设计一种高效的微调方法,通过选择信息量大的样本来最大化Med-VFMs在目标领域上的适应性能。为此,我们提出了一种主动源域无关领域自适应(ASFDA)方法,以高效地将Med-VFMs适配到目标领域,用于体积医学图像分割。ASFDA采用了一种新颖的主动学习(AL)方法,从目标领域选择信息量最大的样本来微调Med-VFMs,无需访问源域预训练样本,从而以最小的选择预算最大化其性能。在该AL方法中,我们设计了一种主动测试时样本查询策略,通过两个查询指标从目标域中选择样本,包括多样化知识散度(DKD)和解剖分割难度(ASD)。DKD旨在衡量源域-目标域知识差距和域内多样性,利用预训练知识来指导查询来自目标域的源域差异大且语义多样的样本。ASD旨在通过自适应地测量前景区域的预测熵来评估解剖结构分割的难度。此外,我们的ASFDA方法采用选择性半监督微调,通过识别未查询样本中具有高可靠性的样本,来提高微调的性能和效率。
🔬 方法详解
问题定义:论文旨在解决医学视觉基础模型(Med-VFMs)在特定目标域的体积医学图像分割任务中的适配问题。现有方法通常采用随机选择目标域样本进行微调的方式,效率低下,无法充分利用Med-VFMs的预训练知识。痛点在于如何高效地选择最具信息量的样本,以最小的标注代价最大化模型在目标域的性能。
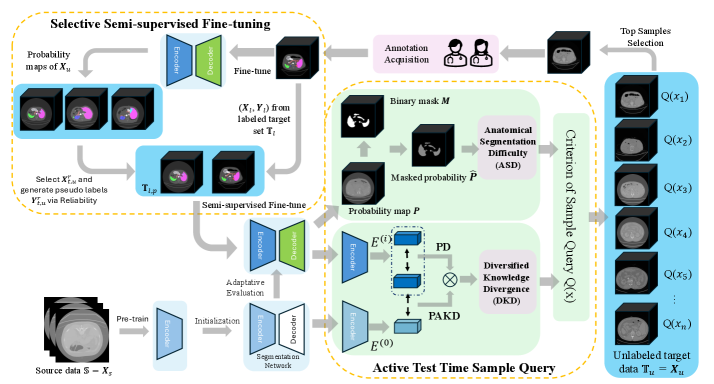
核心思路:论文的核心思路是利用主动学习(AL)策略,从目标域中选择最具代表性和信息量的样本进行微调,从而提高Med-VFMs在目标域的分割性能。同时,为了进一步提高效率,采用了选择性半监督微调,利用未标注样本中置信度高的预测结果来辅助训练。这样可以在有限的标注预算下,充分利用目标域数据,提升模型性能。
技术框架:ASFDA方法主要包含两个阶段:主动学习样本选择和选择性半监督微调。在主动学习阶段,首先使用DKD和ASD两种查询指标对目标域样本进行评估,选择信息量最大的样本。DKD衡量源域-目标域的知识差异和域内多样性,ASD评估解剖结构分割的难度。然后,使用选择的样本对Med-VFMs进行微调。在选择性半监督微调阶段,利用模型对未标注样本的预测结果,选择置信度高的样本进行半监督训练,进一步提升模型性能。
关键创新:论文的关键创新在于提出了DKD和ASD两种查询指标,用于主动学习样本选择。DKD指标能够有效地衡量源域-目标域的知识差异和域内多样性,从而选择出最具代表性的样本。ASD指标能够评估解剖结构分割的难度,从而选择出对模型提升最有帮助的样本。此外,选择性半监督微调也是一个创新点,它能够充分利用未标注样本的信息,提高微调的效率和性能。
关键设计:DKD指标的计算涉及源域和目标域的知识表示,具体实现可能包括计算特征向量之间的距离或散度。ASD指标的计算涉及预测熵,需要设定一个阈值来判断预测结果的置信度。选择性半监督微调的具体实现可能包括使用一致性正则化或伪标签等技术。具体的损失函数设计和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
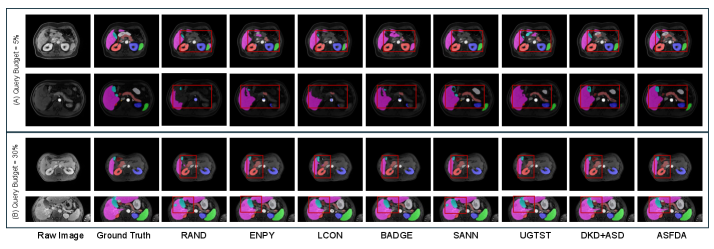
论文提出了ASFDA方法,通过主动学习和选择性半监督微调,提高了医学视觉基础模型在体积医学图像分割任务中的性能。具体实验结果未知,但可以预期,该方法在有限标注数据下,能够显著提升分割精度,并优于随机选择样本进行微调的基线方法。性能提升幅度取决于具体数据集和实验设置。
🎯 应用场景
该研究成果可应用于多种医学图像分割任务,例如肿瘤分割、器官分割等。通过高效地适配医学视觉基础模型,可以减少对大量标注数据的依赖,降低标注成本,并提高分割精度。这对于临床诊断、手术规划和治疗评估具有重要的实际价值,有助于提高医疗效率和改善患者预后。
📄 摘要(原文)
Medical Vision Foundation Models (Med-VFMs) have superior capabilities of interpreting medical images due to the knowledge learned from self-supervised pre-training with extensive unannotated images. To improve their performance on adaptive downstream evaluations, especially segmentation, a few samples from target domains are selected randomly for fine-tuning them. However, there lacks works to explore the way of adapting Med-VFMs to achieve the optimal performance on target domains efficiently. Thus, it is highly demanded to design an efficient way of fine-tuning Med-VFMs by selecting informative samples to maximize their adaptation performance on target domains. To achieve this, we propose an Active Source-Free Domain Adaptation (ASFDA) method to efficiently adapt Med-VFMs to target domains for volumetric medical image segmentation. This ASFDA employs a novel Active Learning (AL) method to select the most informative samples from target domains for fine-tuning Med-VFMs without the access to source pre-training samples, thus maximizing their performance with the minimal selection budget. In this AL method, we design an Active Test Time Sample Query strategy to select samples from the target domains via two query metrics, including Diversified Knowledge Divergence (DKD) and Anatomical Segmentation Difficulty (ASD). DKD is designed to measure the source-target knowledge gap and intra-domain diversity. It utilizes the knowledge of pre-training to guide the querying of source-dissimilar and semantic-diverse samples from the target domains. ASD is designed to evaluate the difficulty in segmentation of anatomical structures by measuring predictive entropy from foreground regions adaptively. Additionally, our ASFDA method employs a Selective Semi-supervised Fine-tuning to improve the performance and efficiency of fine-tuning by identifying samples with high reliability from unqueried ones.