Humor in Pixels: Benchmarking Large Multimodal Models Understanding of Online Comics
作者: Yuriel Ryan, Rui Yang Tan, Kenny Tsu Wei Choo, Roy Ka-Wei Lee
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-09-12 (更新: 2025-09-17)
备注: 27 pages, 8 figures, EMNLP 2025 Findings
💡 一句话要点
提出PixelHumor基准数据集,评估大型多模态模型对在线漫画幽默的理解能力。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 幽默理解 漫画分析 基准数据集 大型语言模型
📋 核心要点
- 现有大型多模态模型在理解幽默和叙事连贯性方面存在明显不足,难以有效整合视觉和文本信息。
- PixelHumor数据集通过多面板漫画,提供了一个评估模型理解多模态幽默和叙事序列能力的基准。
- 实验表明,即使是最先进的模型在漫画面板排序任务上的表现也远低于人类水平,揭示了模型的局限性。
📝 摘要(中文)
理解幽默是社交智能的核心,但对于大型多模态模型(LMMs)来说仍然是一个巨大的挑战。我们引入了PixelHumor,这是一个包含2800个带注释的多面板漫画的基准数据集,旨在评估LMMs解释多模态幽默和识别叙事序列的能力。对最先进的LMMs进行的实验揭示了显著的差距:例如,顶级模型在面板排序方面的准确率仅为61%,远低于人类的表现。这突显了当前模型在整合视觉和文本线索以实现连贯叙事和幽默理解方面的关键局限性。通过为评估多模态上下文和叙事推理提供一个严格的框架,PixelHumor旨在推动LMMs的发展,使其更好地参与自然、具有社会意识的互动。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在理解在线漫画中的幽默和叙事连贯性方面的不足。现有方法难以有效整合视觉和文本信息,导致模型在理解上下文、识别叙事序列以及捕捉幽默感方面表现不佳。这阻碍了LMMs在社交互动等需要高级理解能力的场景中的应用。
核心思路:论文的核心思路是构建一个专门用于评估LMMs幽默理解能力的基准数据集PixelHumor。该数据集包含大量带注释的多面板漫画,通过面板排序等任务,迫使模型学习理解视觉和文本之间的复杂关系,从而提高其幽默感和叙事理解能力。
技术框架:PixelHumor数据集包含2800个多面板漫画,每个漫画都经过人工标注,包括面板顺序、幽默类型等信息。研究人员使用该数据集对现有的LMMs进行评估,通过设计特定的任务(如面板排序、幽默识别)来测试模型在不同方面的表现。评估结果可以帮助研究人员发现模型的弱点,并指导模型改进。
关键创新:PixelHumor数据集的创新之处在于其专注于评估LMMs对多模态幽默的理解能力。与现有的通用型多模态数据集不同,PixelHumor专门针对漫画这种富含视觉和文本信息的媒介,设计了更具挑战性的评估任务。这使得研究人员能够更精确地评估模型在理解上下文、识别叙事序列以及捕捉幽默感方面的能力。
关键设计:数据集的关键设计在于多面板漫画的选择和标注。漫画的选择需要保证内容具有一定的幽默感和叙事性,同时涵盖不同的风格和主题。标注方面,除了面板顺序外,还包括幽默类型、关键人物、情感倾向等信息。这些标注可以用于设计不同的评估任务,并为模型提供更丰富的训练数据。具体的参数设置、损失函数、网络结构等技术细节取决于所使用的LMMs模型。
🖼️ 关键图片

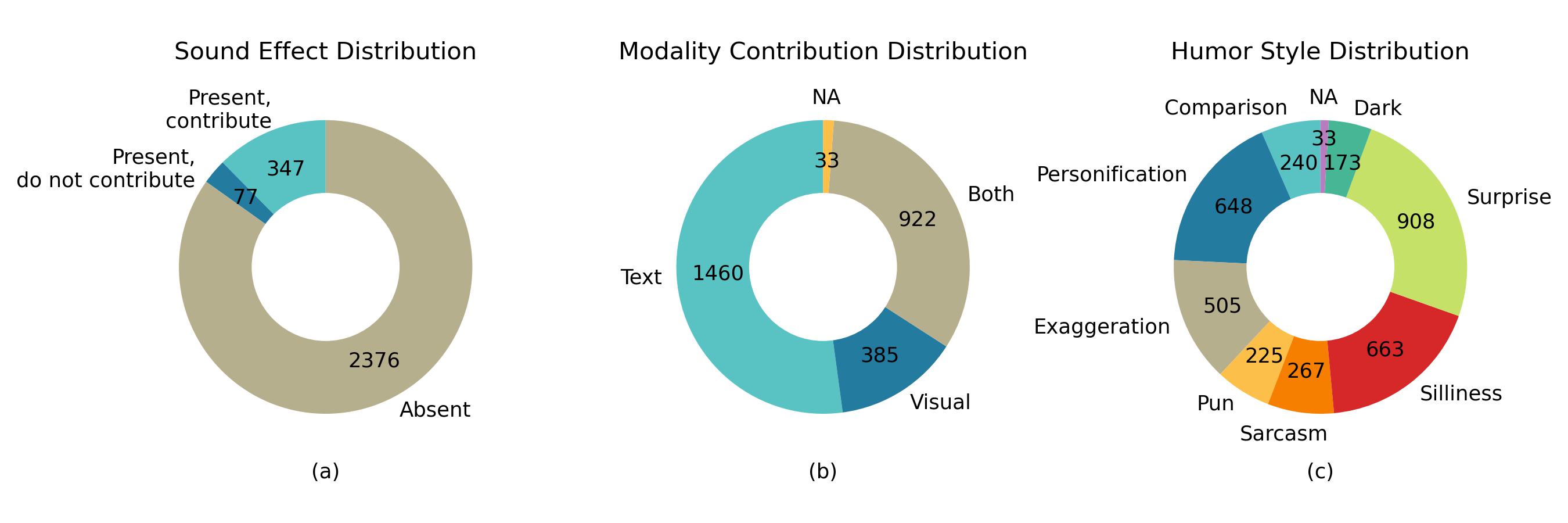
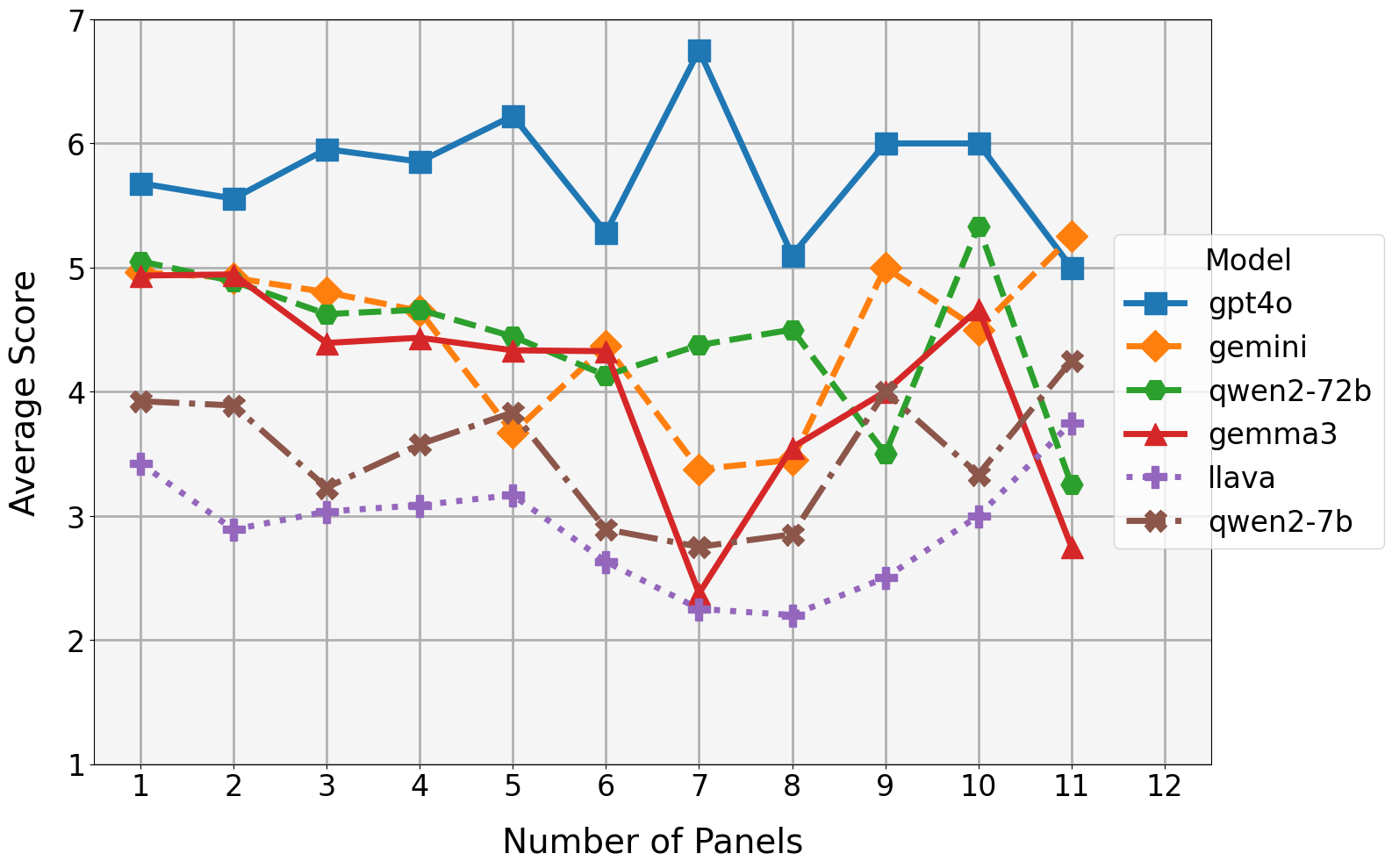
📊 实验亮点
实验结果表明,即使是最先进的LMMs在PixelHumor数据集上的表现也远低于人类水平。例如,顶级模型在面板排序任务上的准确率仅为61%,与人类的表现存在显著差距。这表明当前模型在整合视觉和文本信息以理解幽默和叙事方面仍存在很大的提升空间。该数据集为后续研究提供了一个有力的评估工具。
🎯 应用场景
该研究成果可应用于提升聊天机器人、虚拟助手等AI系统在社交互动中的表现。通过提高模型对幽默和叙事的理解能力,可以使AI系统更自然、更具人情味,从而改善用户体验。此外,该研究也有助于开发更智能的教育和娱乐应用,例如个性化漫画推荐、自动生成幽默对话等。
📄 摘要(原文)
Understanding humor is a core aspect of social intelligence, yet it remains a significant challenge for Large Multimodal Models (LMMs). We introduce PixelHumor, a benchmark dataset of 2,800 annotated multi-panel comics designed to evaluate LMMs' ability to interpret multimodal humor and recognize narrative sequences. Experiments with state-of-the-art LMMs reveal substantial gaps: for instance, top models achieve only 61% accuracy in panel sequencing, far below human performance. This underscores critical limitations in current models' integration of visual and textual cues for coherent narrative and humor understanding. By providing a rigorous framework for evaluating multimodal contextual and narrative reasoning, PixelHumor aims to drive the development of LMMs that better engage in natural, socially aware interactions.