A Comparison and Evaluation of Fine-tuned Convolutional Neural Networks to Large Language Models for Image Classification and Segmentation of Brain Tumors on MRI
作者: Felicia Liu, Jay J. Yoo, Farzad Khalvati
分类: cs.CV, cs.AI
发布日期: 2025-09-12
💡 一句话要点
对比微调LLM与CNN在脑肿瘤MRI图像分类与分割任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 卷积神经网络 脑肿瘤分割 医学图像分类 微调 MRI图像 视觉语言模型
📋 核心要点
- 现有LLM在医学图像任务中应用潜力未知,缺乏与传统CNN的直接对比。
- 探索通用视觉-语言LLM在脑肿瘤分类与分割任务中的性能,并与定制3D CNN进行比较。
- 实验表明,CNN在分类和分割任务中均优于LLM,LLM微调后性能提升有限。
📝 摘要(中文)
大型语言模型(LLM)在基于文本的医疗保健任务中表现出强大的性能。然而,它们在基于图像的应用中的效用仍未被探索。本文研究了LLM在医学成像任务中的有效性,特别是胶质瘤分类和分割,并将它们的性能与传统的卷积神经网络(CNN)进行了比较。使用BraTS 2020多模态脑部MRI数据集,我们评估了一个通用视觉-语言LLM (LLaMA 3.2 Instruct)在微调前后的性能,并将其性能与定制的3D CNN进行了基准测试。对于胶质瘤分类(低级别vs.高级别),CNN达到了80%的准确率和平衡的精确率和召回率。通用LLM达到了76%的准确率,但特异性仅为18%,经常错误分类低级别肿瘤。微调将特异性提高到55%,但整体性能下降(例如,准确率降至72%)。对于分割,实现了三种方法——中心点、边界框和多边形提取。CNN准确地定位了胶质瘤,尽管有时会遗漏小肿瘤。相比之下,LLM始终将预测聚集在图像中心附近,没有区分胶质瘤的大小、位置或放置。微调改进了输出格式,但未能有意义地提高空间准确性。边界多边形方法产生了随机的、非结构化的输出。总的来说,CNN在两项任务中都优于LLM。LLM显示出有限的空间理解能力,并且微调带来的改进很小,这表明,就目前的形式而言,它们不太适合基于图像的任务。可能需要更严格的微调或替代训练策略,LLM才能在医学领域实现更好的性能、鲁棒性和实用性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在医学图像处理任务中的有效性,具体问题是脑肿瘤的分类和分割。现有方法,特别是传统的卷积神经网络(CNN),在这些任务中表现良好,但LLM在图像理解方面的潜力尚未充分探索。现有方法的痛点在于缺乏对LLM在医学图像领域的适用性的系统性评估。
核心思路:论文的核心思路是将预训练的通用视觉-语言LLM(LLaMA 3.2 Instruct)应用于脑肿瘤分类和分割任务,并通过微调来提升其性能。通过与专门设计的3D CNN进行对比,评估LLM在医学图像理解方面的优势和局限性。
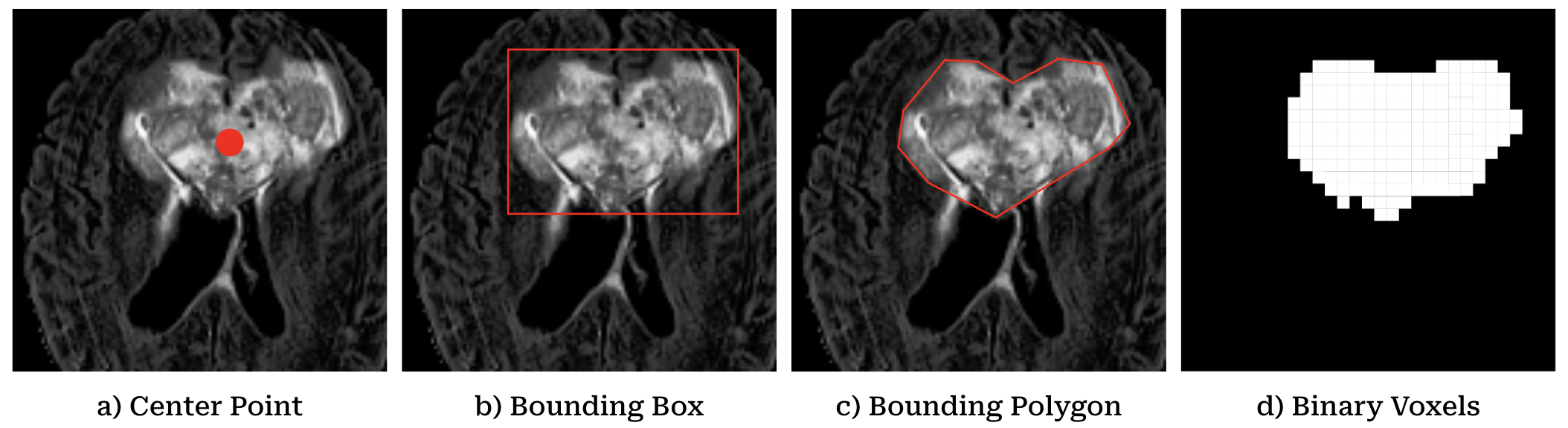
技术框架:整体框架包括以下几个主要步骤:1) 使用BraTS 2020数据集对LLaMA 3.2 Instruct进行微调;2) 使用微调后的LLM进行脑肿瘤分类(低级别 vs. 高级别);3) 使用微调后的LLM进行脑肿瘤分割,采用中心点、边界框和多边形提取三种方法;4) 将LLM的性能与定制的3D CNN进行比较。
关键创新:论文的关键创新在于首次系统性地评估了通用视觉-语言LLM在医学图像分类和分割任务中的性能,并将其与传统的CNN进行了直接对比。这为LLM在医学图像领域的应用提供了重要的参考。
关键设计:在分类任务中,使用交叉熵损失函数对LLM进行微调。在分割任务中,尝试了三种不同的方法:中心点预测、边界框预测和多边形提取。对于边界框和多边形提取,采用了特定的提示工程(prompt engineering)来指导LLM生成结构化的输出。数据集采用BraTS 2020,包含多模态MRI图像。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在脑肿瘤分类任务中,CNN达到80%的准确率,而LLM的初始准确率为76%,微调后降至72%。在分割任务中,CNN能够准确地定位肿瘤,而LLM的预测结果集中在图像中心,无法有效区分肿瘤的大小和位置。总体而言,CNN在两项任务中均优于LLM。
🎯 应用场景
该研究为LLM在医学图像分析领域的应用提供了参考,有助于推动AI在疾病诊断、治疗规划等方面的应用。未来的研究可以探索更有效的微调策略和模型架构,以提升LLM在医学图像任务中的性能,从而辅助医生进行更准确的诊断和治疗。
📄 摘要(原文)
Large Language Models (LLMs) have shown strong performance in text-based healthcare tasks. However, their utility in image-based applications remains unexplored. We investigate the effectiveness of LLMs for medical imaging tasks, specifically glioma classification and segmentation, and compare their performance to that of traditional convolutional neural networks (CNNs). Using the BraTS 2020 dataset of multi-modal brain MRIs, we evaluated a general-purpose vision-language LLM (LLaMA 3.2 Instruct) both before and after fine-tuning, and benchmarked its performance against custom 3D CNNs. For glioma classification (Low-Grade vs. High-Grade), the CNN achieved 80% accuracy and balanced precision and recall. The general LLM reached 76% accuracy but suffered from a specificity of only 18%, often misclassifying Low-Grade tumors. Fine-tuning improved specificity to 55%, but overall performance declined (e.g., accuracy dropped to 72%). For segmentation, three methods - center point, bounding box, and polygon extraction, were implemented. CNNs accurately localized gliomas, though small tumors were sometimes missed. In contrast, LLMs consistently clustered predictions near the image center, with no distinction of glioma size, location, or placement. Fine-tuning improved output formatting but failed to meaningfully enhance spatial accuracy. The bounding polygon method yielded random, unstructured outputs. Overall, CNNs outperformed LLMs in both tasks. LLMs showed limited spatial understanding and minimal improvement from fine-tuning, indicating that, in their current form, they are not well-suited for image-based tasks. More rigorous fine-tuning or alternative training strategies may be needed for LLMs to achieve better performance, robustness, and utility in the medical space.