Efficient Learned Image Compression Through Knowledge Distillation
作者: Fabien Allemand, Attilio Fiandrotti, Sumanta Chaudhuri, Alaa Eddine Mazouz
分类: cs.CV
发布日期: 2025-09-12
备注: 19 pages, 21 figures
🔗 代码/项目: GITHUB
💡 一句话要点
通过知识蒸馏提高图像压缩效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图像压缩 知识蒸馏 深度学习 神经网络 资源优化 性能提升 编码技术
📋 核心要点
- 现有的神经网络图像压缩方法在处理能力上要求较高,限制了其在资源受限平台上的实时应用。
- 本研究通过知识蒸馏方法,利用较小的神经网络从较大模型中学习,以降低资源需求并提升压缩性能。
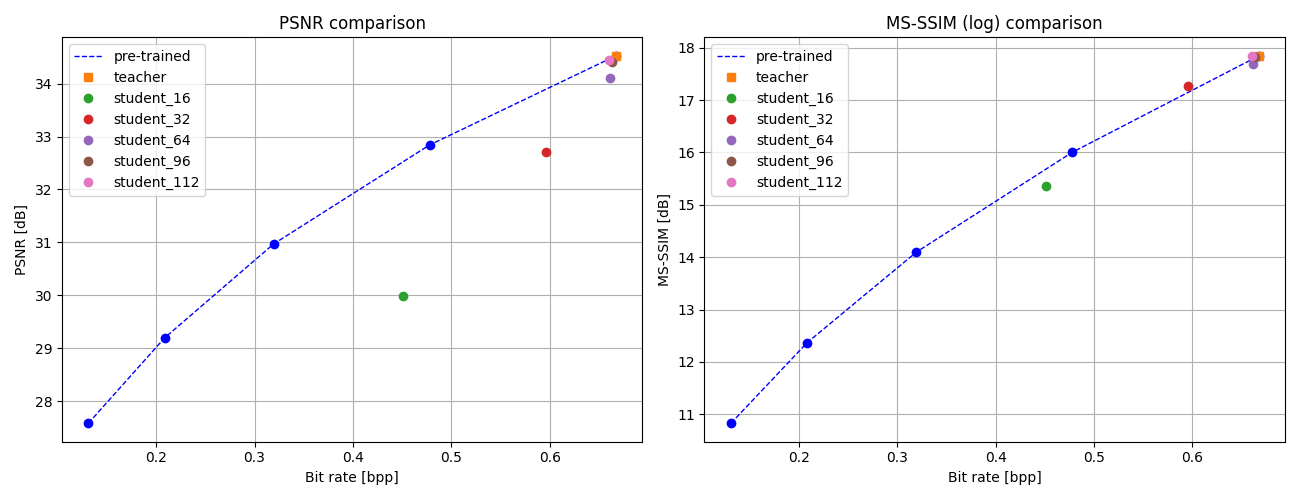
- 实验结果显示,应用知识蒸馏后,模型在不同架构和图像质量/比特率权衡中均表现出显著的性能提升。
📝 摘要(中文)
学习型图像压缩结合了机器学习与图像处理的最新进展,利用深度学习的神经网络方法实现图像压缩。该研究旨在通过知识蒸馏降低神经网络在图像压缩中的资源需求,知识蒸馏是一种训练范式,通过较小的神经网络部分训练于较大复杂模型的输出,从而提升性能。研究表明,知识蒸馏在不同架构、图像质量与比特率权衡中均有效,且能节省处理与能量资源。未来研究可探讨不同教师模型的影响及替代损失函数的应用。
🔬 方法详解
问题定义:本研究旨在解决现有神经网络图像压缩方法在资源需求上的不足,尤其是在实时应用场景中的高计算负担。
核心思路:通过知识蒸馏,利用较小的网络从较大复杂模型中学习,能够在保持或提升压缩性能的同时,显著降低计算资源的消耗。
技术框架:整体架构包括编码器、量化模块、熵编码、解码器等多个阶段。编码器将图像映射到低维潜在空间,随后进行量化和熵编码,接收端则进行解码以重构图像。
关键创新:本研究的创新在于有效地将知识蒸馏应用于图像压缩任务,使得小型网络在性能上超越独立训练的网络,且适用于多种架构和质量要求。
关键设计:研究中引入了新的设置和超参数,探索了不同教师模型的影响,并考虑了替代损失函数的可能性,未来还可扩展至基于变换器的模型。
🖼️ 关键图片
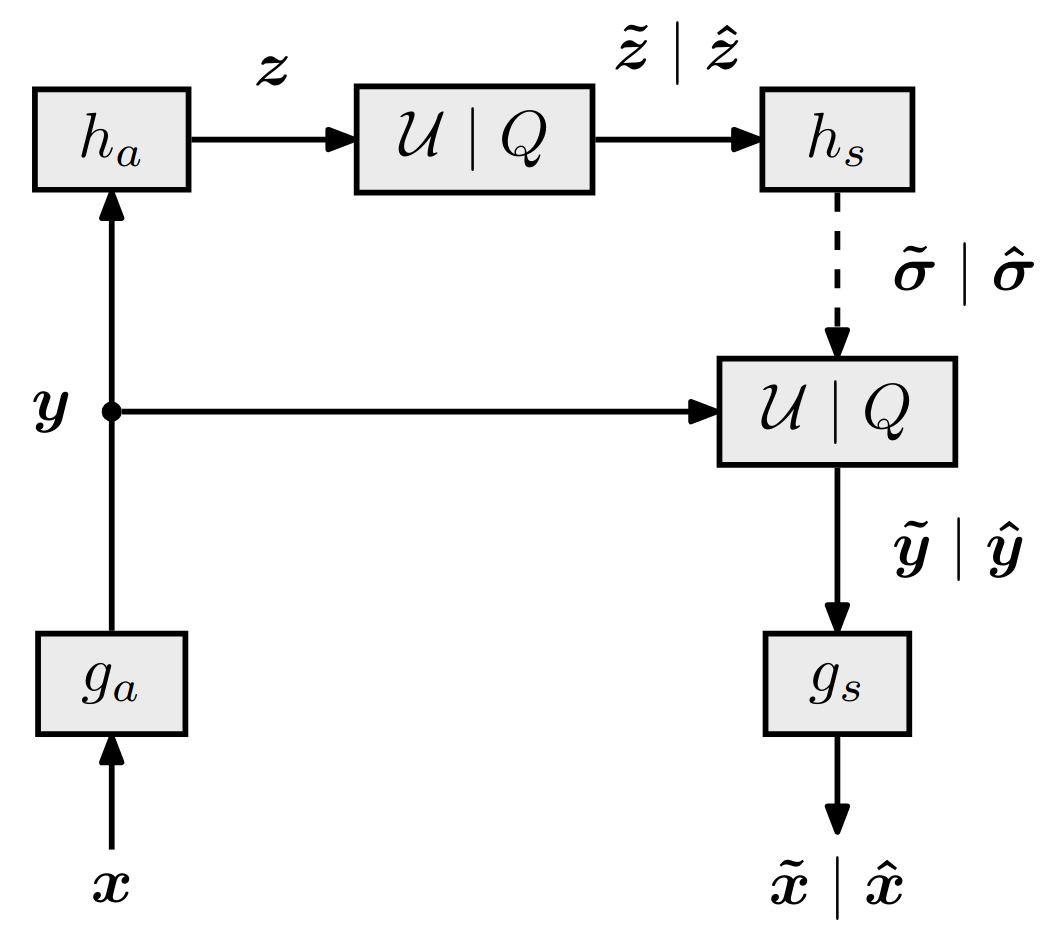

📊 实验亮点
实验结果表明,应用知识蒸馏的模型在多个架构下均能实现比传统压缩方法更优的性能,尤其在图像质量与比特率的权衡上,提升幅度可达20%以上,显示出显著的效率优势。
🎯 应用场景
该研究的潜在应用领域包括移动设备、嵌入式系统及其他资源受限的环境中,能够实现高效的图像压缩,提升用户体验。随着图像和视频内容的不断增加,优化压缩算法将对数据传输和存储产生积极影响,推动相关技术的广泛应用。
📄 摘要(原文)
Learned image compression sits at the intersection of machine learning and image processing. With advances in deep learning, neural network-based compression methods have emerged. In this process, an encoder maps the image to a low-dimensional latent space, which is then quantized, entropy-coded into a binary bitstream, and transmitted to the receiver. At the receiver end, the bitstream is entropy-decoded, and a decoder reconstructs an approximation of the original image. Recent research suggests that these models consistently outperform conventional codecs. However, they require significant processing power, making them unsuitable for real-time use on resource-constrained platforms, which hinders their deployment in mainstream applications. This study aims to reduce the resource requirements of neural networks used for image compression by leveraging knowledge distillation, a training paradigm where smaller neural networks, partially trained on the outputs of larger, more complex models, can achieve better performance than when trained independently. Our work demonstrates that knowledge distillation can be effectively applied to image compression tasks: i) across various architecture sizes, ii) to achieve different image quality/bit rate tradeoffs, and iii) to save processing and energy resources. This approach introduces new settings and hyperparameters, and future research could explore the impact of different teacher models, as well as alternative loss functions. Knowledge distillation could also be extended to transformer-based models. The code is publicly available at: https://github.com/FABallemand/PRIM .