Towards Understanding Visual Grounding in Visual Language Models
作者: Georgios Pantazopoulos, Eda B. Özyiğit
分类: cs.CV, cs.AI
发布日期: 2025-09-12 (更新: 2025-09-15)
💡 一句话要点
综述视觉语言模型中的视觉定位技术,分析挑战与未来方向。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 视觉语言模型 多模态学习 指代表达式理解 视觉问答 多模态推理 深度学习 综述
📋 核心要点
- 现有视觉语言模型在精确关联文本描述与图像区域方面仍面临挑战,尤其是在复杂场景和细粒度定位任务中。
- 本文通过系统性地回顾视觉定位的研究进展,旨在梳理现有方法、分析关键技术,并为未来的研究方向提供指导。
- 该综述涵盖了视觉定位的核心组件、应用场景、评估指标以及与多模态推理的联系,为研究人员提供了全面的参考。
📝 摘要(中文)
视觉定位是指模型识别视觉输入中与文本描述相匹配区域的能力。具备视觉定位能力的模型可以应用于各种领域,包括指代表达式理解、回答图像或视频中细粒度细节相关的问题、通过显式引用实体来描述视觉上下文,以及模拟和真实环境中的低级和高级控制。本文综述了现代通用视觉语言模型(VLM)关键研究领域的代表性工作。首先概述了定位在VLM中的重要性,然后描述了开发定位模型的当代范式的核心组成部分,并考察了它们的实际应用,包括用于定位多模态生成的基准和评估指标。还讨论了视觉定位、多模态思维链和VLM中的推理之间多方面的相互关系。最后,分析了视觉定位固有的挑战,并为未来的研究提出了有希望的方向。
🔬 方法详解
问题定义:视觉定位旨在建立文本描述与图像区域之间的对应关系。现有方法在处理复杂场景、细粒度定位以及长文本描述时,往往存在定位不准确、效率低下的问题。此外,如何有效利用上下文信息进行推理也是一个挑战。
核心思路:本文的核心思路是对现有视觉定位方法进行系统性的梳理和分析,从模型架构、训练策略、评估指标等多个维度进行剖析,从而揭示不同方法的优缺点,并为未来的研究提供指导。通过分析视觉定位与多模态推理之间的联系,探讨如何利用推理能力提升定位性能。
技术框架:本文的综述框架主要包括以下几个部分:首先,介绍视觉定位的基本概念和重要性;其次,详细描述视觉定位模型的核心组成部分,包括视觉编码器、文本编码器、多模态融合模块和定位模块;然后,考察视觉定位的实际应用,包括指代表达式理解、视觉问答等;接着,讨论视觉定位与多模态思维链和推理之间的关系;最后,分析视觉定位面临的挑战,并提出未来的研究方向。
关键创新:本文的主要创新在于对视觉定位领域进行了全面的综述,并深入分析了现有方法的优缺点。通过对视觉定位与多模态推理之间关系的探讨,为未来的研究提供了新的思路。此外,本文还对视觉定位面临的挑战进行了总结,并提出了有希望的研究方向。
关键设计:本文主要关注现有视觉定位方法的设计,包括视觉编码器的选择(如卷积神经网络、Transformer)、文本编码器的选择(如循环神经网络、Transformer)、多模态融合模块的设计(如注意力机制、跨模态Transformer)以及定位模块的设计(如回归、分类)。此外,本文还关注训练策略的选择(如对比学习、生成式学习)和损失函数的设计(如交叉熵损失、IoU损失)。
🖼️ 关键图片

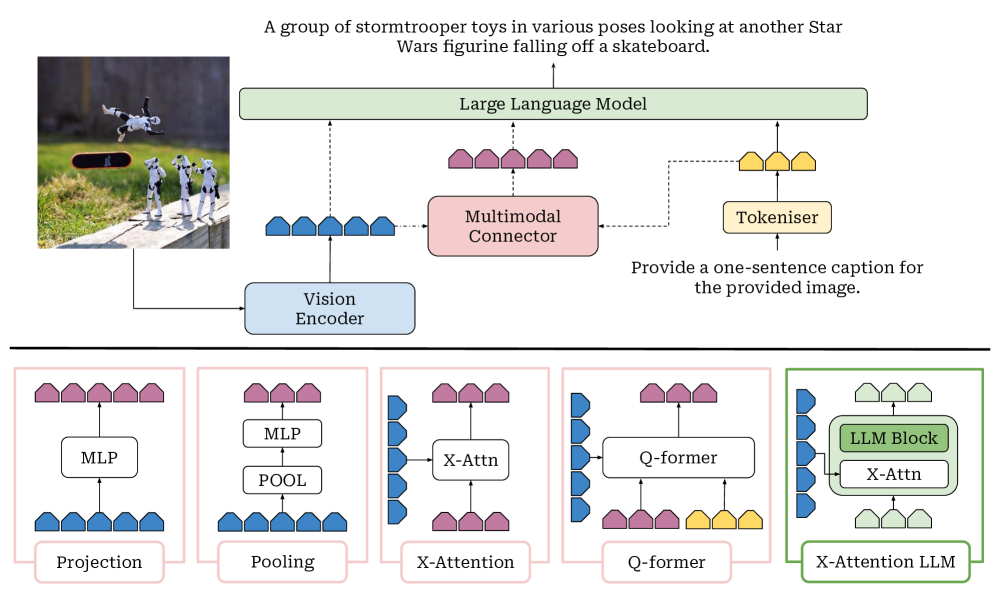
📊 实验亮点
本文是一篇综述性文章,因此没有具体的实验结果。但是,它总结了现有视觉定位方法在不同任务上的性能表现,并分析了不同方法的优缺点。通过对现有方法的对比分析,为研究人员提供了选择合适方法的参考依据。此外,本文还指出了现有方法存在的不足,并为未来的研究方向提供了指导。
🎯 应用场景
视觉定位技术在多个领域具有广泛的应用前景,包括:智能交互(例如,用户可以通过语音或文本指令控制机器人执行特定任务)、图像编辑(例如,根据文本描述修改图像中的特定区域)、自动驾驶(例如,识别交通标志和行人)以及医疗诊断(例如,定位医学图像中的病灶)。该技术的发展将极大地提升人机交互的效率和智能化水平。
📄 摘要(原文)
Visual grounding refers to the ability of a model to identify a region within some visual input that matches a textual description. Consequently, a model equipped with visual grounding capabilities can target a wide range of applications in various domains, including referring expression comprehension, answering questions pertinent to fine-grained details in images or videos, caption visual context by explicitly referring to entities, as well as low and high-level control in simulated and real environments. In this survey paper, we review representative works across the key areas of research on modern general-purpose vision language models (VLMs). We first outline the importance of grounding in VLMs, then delineate the core components of the contemporary paradigm for developing grounded models, and examine their practical applications, including benchmarks and evaluation metrics for grounded multimodal generation. We also discuss the multifaceted interrelations among visual grounding, multimodal chain-of-thought, and reasoning in VLMs. Finally, we analyse the challenges inherent to visual grounding and suggest promising directions for future research.