MCL-AD: Multimodal Collaboration Learning for Zero-Shot 3D Anomaly Detection
作者: Gang Li, Tianjiao Chen, Mingle Zhou, Min Li, Delong Han, Jin Wan
分类: cs.CV, cs.LG
发布日期: 2025-09-12
备注: Page 14, 5 pictures
💡 一句话要点
MCL-AD:多模态协同学习用于零样本3D异常检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 3D异常检测 多模态融合 点云处理 图像处理
📋 核心要点
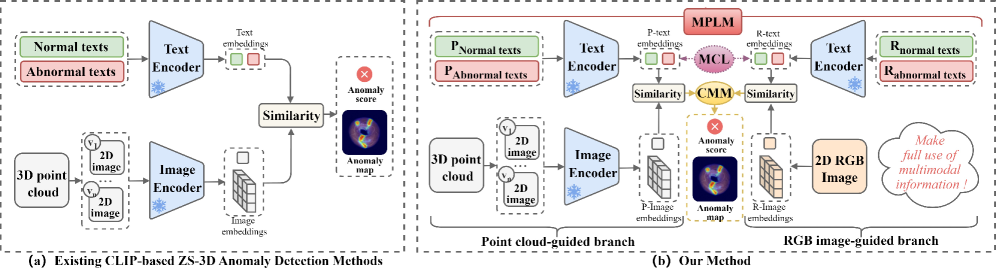
- 现有零样本3D异常检测方法主要依赖点云,忽略了RGB图像和文本等模态的丰富语义信息。
- MCL-AD框架通过多模态协同学习,融合点云、RGB图像和文本语义,提升零样本3D异常检测性能。
- 实验结果表明,MCL-AD框架在零样本3D异常检测任务上取得了state-of-the-art的性能。
📝 摘要(中文)
本文提出了一种名为MCL-AD的新框架,用于实现卓越的零样本3D异常检测,该框架利用点云、RGB图像和文本语义之间的多模态协同学习。具体而言,我们提出了一种多模态提示学习机制(MPLM),通过引入与对象无关的解耦文本提示和多模态对比损失,增强了模内表示能力和模间协同学习。此外,还提出了一种协同调制机制(CMM),通过联合调制RGB图像引导和点云引导的分支,充分利用点云和RGB图像的互补表示。大量实验表明,所提出的MCL-AD框架在零样本3D异常检测中实现了最先进的性能。
🔬 方法详解
问题定义:零样本3D异常检测旨在无需标注训练数据的情况下识别3D对象中的缺陷。现有方法主要依赖点云数据,忽略了其他模态(如RGB图像和文本)提供的互补信息,导致性能受限。这些方法难以有效利用多模态信息进行异常检测。
核心思路:MCL-AD的核心思路是利用多模态协同学习,将点云、RGB图像和文本语义信息融合,从而提升零样本3D异常检测的性能。通过设计多模态提示学习机制和协同调制机制,充分挖掘和利用不同模态之间的互补信息。
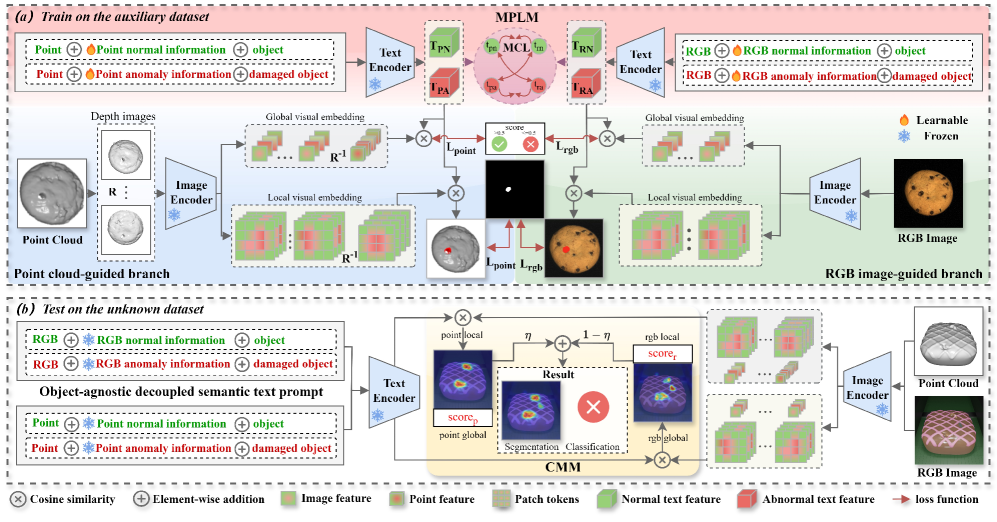
技术框架:MCL-AD框架主要包含两个核心模块:多模态提示学习机制(MPLM)和协同调制机制(CMM)。MPLM通过引入对象无关的解耦文本提示和多模态对比损失,增强模内表示能力和模间协同学习。CMM则通过联合调制RGB图像引导和点云引导的分支,充分利用点云和RGB图像的互补表示。整体流程是首先使用MPLM学习各模态的特征表示,然后通过CMM融合点云和RGB图像的特征,最后进行异常检测。
关键创新:MCL-AD的关键创新在于:1) 提出了多模态提示学习机制(MPLM),通过解耦文本提示和多模态对比损失,有效提升了模内表示和模间协同学习能力。2) 提出了协同调制机制(CMM),能够充分利用点云和RGB图像的互补信息,提升异常检测的准确性。与现有方法相比,MCL-AD能够更有效地利用多模态信息,从而在零样本场景下实现更好的异常检测性能。
关键设计:MPLM中,解耦文本提示的设计允许模型学习与对象无关的通用语义信息,从而提升模型的泛化能力。多模态对比损失则鼓励模型学习不同模态之间的对应关系,从而实现更好的模态融合。CMM中,RGB图像引导和点云引导的分支采用联合调制的方式,使得模型能够充分利用两种模态的互补信息。具体的损失函数设计和网络结构参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
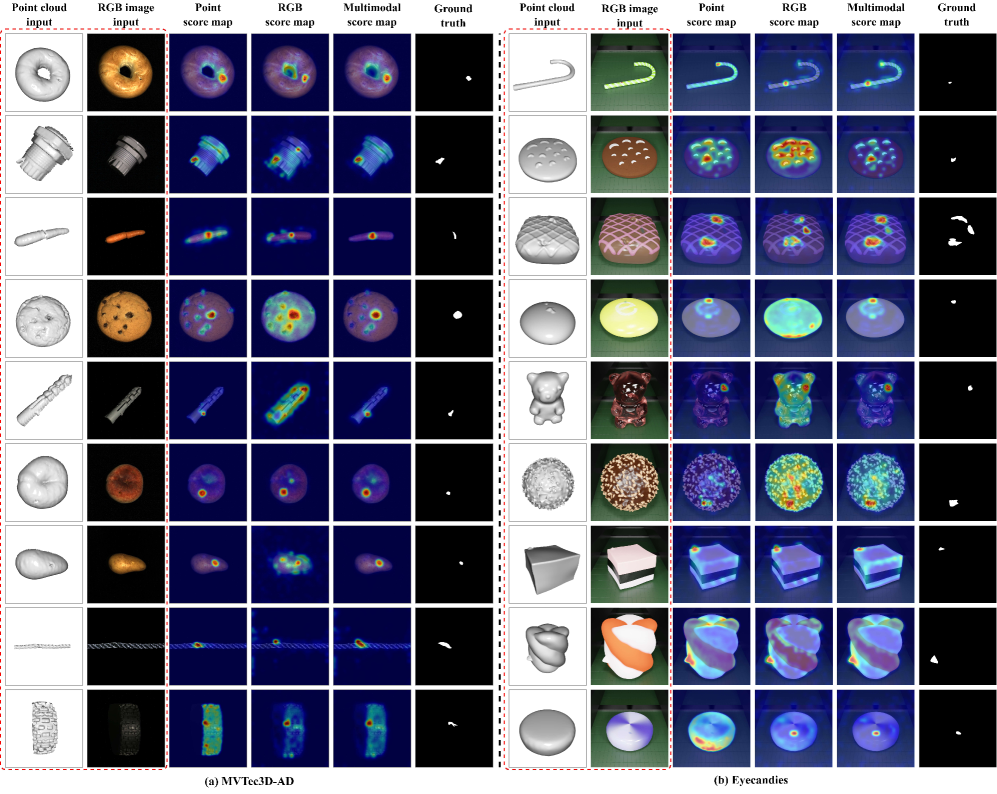
论文通过大量实验验证了MCL-AD框架的有效性,并在零样本3D异常检测任务上取得了state-of-the-art的性能。具体的性能数据和对比基线在论文中有详细展示,表明MCL-AD在多个数据集上均优于现有方法,证明了其在零样本3D异常检测领域的优越性。
🎯 应用场景
该研究成果可应用于多种工业场景,例如产品质量检测、智能制造、机器人视觉等。在这些场景中,获取带标签的3D异常数据成本高昂或难以实现,零样本异常检测技术具有重要的应用价值。MCL-AD框架能够有效提升零样本3D异常检测的性能,从而降低人工检测成本,提高生产效率,并为智能制造提供更可靠的技术支持。
📄 摘要(原文)
Zero-shot 3D (ZS-3D) anomaly detection aims to identify defects in 3D objects without relying on labeled training data, making it especially valuable in scenarios constrained by data scarcity, privacy, or high annotation cost. However, most existing methods focus exclusively on point clouds, neglecting the rich semantic cues available from complementary modalities such as RGB images and texts priors. This paper introduces MCL-AD, a novel framework that leverages multimodal collaboration learning across point clouds, RGB images, and texts semantics to achieve superior zero-shot 3D anomaly detection. Specifically, we propose a Multimodal Prompt Learning Mechanism (MPLM) that enhances the intra-modal representation capability and inter-modal collaborative learning by introducing an object-agnostic decoupled text prompt and a multimodal contrastive loss. In addition, a collaborative modulation mechanism (CMM) is proposed to fully leverage the complementary representations of point clouds and RGB images by jointly modulating the RGB image-guided and point cloud-guided branches. Extensive experiments demonstrate that the proposed MCL-AD framework achieves state-of-the-art performance in ZS-3D anomaly detection.