Detecting Text Manipulation in Images using Vision Language Models
作者: Vidit Vidit, Pavel Korshunov, Amir Mohammadi, Christophe Ecabert, Ketan Kotwal, Sébastien Marcel
分类: cs.CV
发布日期: 2025-09-12
备注: Accepted in Synthetic Realities and Biometric Security Workshop BMVC-2025. For paper page see https://www.idiap.ch/paper/textvlmdet/
💡 一句话要点
利用视觉语言模型检测图像中的文本篡改
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 文本篡改检测 视觉语言模型 图像篡改检测 多模态学习 深度学习
📋 核心要点
- 现有图像篡改检测研究较少关注图像中文本的篡改,存在明显的知识缺口。
- 本文利用视觉语言模型(VLMs)进行文本篡改检测,并对比分析了不同类型VLMs的性能。
- 实验结果表明,开源VLMs在文本篡改检测方面与闭源VLMs存在差距,且图像篡改检测专用VLMs泛化能力不足。
📝 摘要(中文)
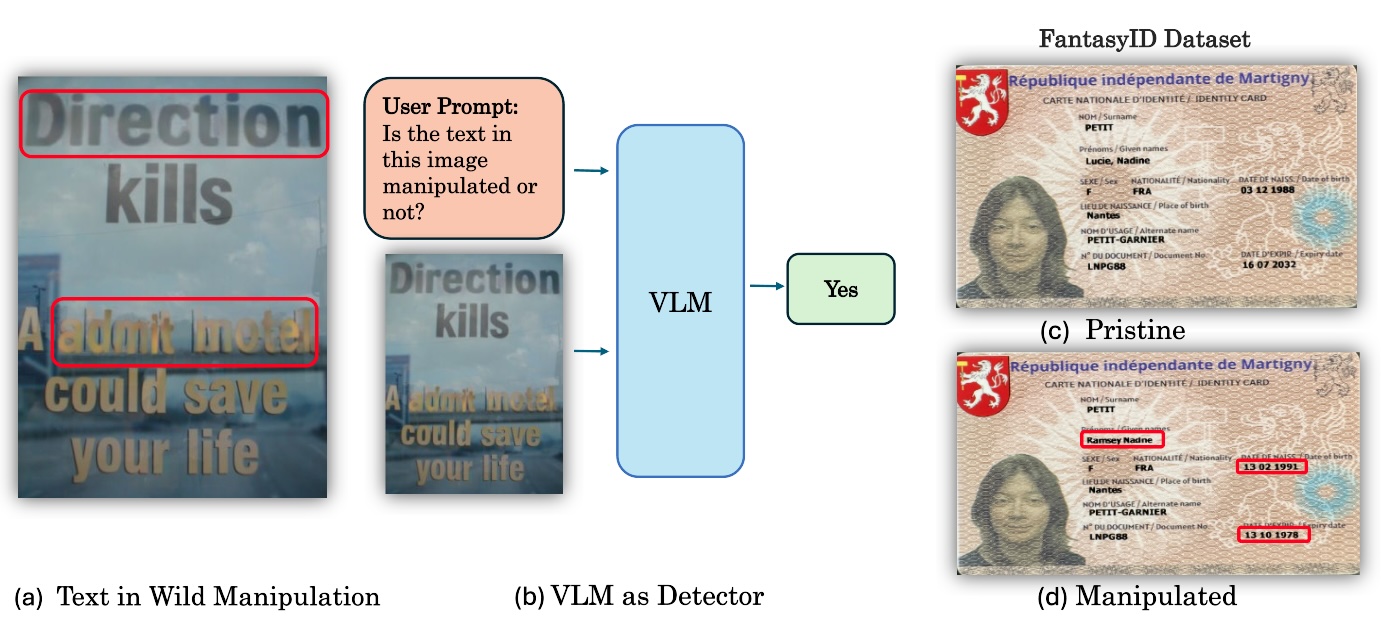
近年来,大型视觉语言模型(VLMs或LVLMs)在图像篡改检测方面展现出有效性。然而,这些研究在很大程度上忽略了文本篡改检测。本文通过分析闭源和开源的VLMs在不同的文本篡改数据集上的表现,弥补了这一知识空白。结果表明,开源模型正逐渐接近闭源模型(如GPT-4o),但仍有差距。此外,本文还对专门用于图像篡改检测的VLMs进行了文本篡改检测的基准测试,结果表明它们存在泛化问题。本文还对在真实场景文本和虚构身份证上进行的篡改进行了基准测试,后者模拟了具有挑战性的现实滥用场景。
🔬 方法详解
问题定义:论文旨在解决图像中文本篡改的检测问题。现有方法,特别是图像篡改检测方法,在文本篡改检测任务上的表现不佳,缺乏对文本语义和视觉信息的综合理解。此外,现有研究对文本篡改的关注度不足,缺乏系统的基准测试和分析。
核心思路:论文的核心思路是利用视觉语言模型(VLMs)强大的多模态理解能力,同时分析闭源和开源VLMs在文本篡改检测任务上的表现,从而填补现有研究的空白。通过对比不同VLMs的性能,揭示其在文本篡改检测方面的优势和不足。
技术框架:论文采用的框架主要包括以下几个步骤:1)收集或构建包含文本篡改的图像数据集;2)选择不同的VLMs,包括闭源模型(如GPT-4o)和开源模型;3)使用这些VLMs对数据集中的图像进行文本篡改检测;4)对VLMs的检测结果进行评估和比较,分析其性能差异。
关键创新:论文的关键创新在于:1)系统性地研究了VLMs在文本篡改检测任务上的表现,填补了现有研究的空白;2)对比分析了闭源和开源VLMs的性能差异,为选择合适的模型提供了参考;3)针对图像篡改检测专用VLMs的泛化问题进行了分析,揭示了其局限性。
关键设计:论文的关键设计包括:1)选择了具有代表性的闭源和开源VLMs;2)使用了不同的文本篡改数据集,包括真实场景文本和虚构身份证,以模拟不同的应用场景;3)采用了合适的评估指标,如准确率、召回率和F1值,来评估VLMs的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,开源VLMs在文本篡改检测方面正逐渐接近闭源模型,但仍存在差距。图像篡改检测专用VLMs在文本篡改检测任务中表现出泛化能力不足的问题。在虚构身份证数据集上,VLMs的检测性能相对较差,表明该任务具有挑战性,需要进一步研究。
🎯 应用场景
该研究成果可应用于数字取证、信息安全、身份验证等领域。例如,可以用于检测伪造的身份证件、篡改的新闻图片等,从而维护社会诚信和公共安全。未来,该技术有望集成到自动化内容审核系统中,提升网络内容的安全性和可信度。
📄 摘要(原文)
Recent works have shown the effectiveness of Large Vision Language Models (VLMs or LVLMs) in image manipulation detection. However, text manipulation detection is largely missing in these studies. We bridge this knowledge gap by analyzing closed- and open-source VLMs on different text manipulation datasets. Our results suggest that open-source models are getting closer, but still behind closed-source ones like GPT- 4o. Additionally, we benchmark image manipulation detection-specific VLMs for text manipulation detection and show that they suffer from the generalization problem. We benchmark VLMs for manipulations done on in-the-wild scene texts and on fantasy ID cards, where the latter mimic a challenging real-world misuse.