LayerLock: Non-collapsing Representation Learning with Progressive Freezing
作者: Goker Erdogan, Nikhil Parthasarathy, Catalin Ionescu, Drew A. Hudson, Alexander Lerchner, Andrew Zisserman, Mehdi S. M. Sajjadi, Joao Carreira
分类: cs.CV
发布日期: 2025-09-12 (更新: 2025-09-30)
备注: ICCV 2025
💡 一句话要点
LayerLock:通过渐进式冻结实现非坍塌的自监督表征学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 视觉表征学习 掩码自编码器 渐进式学习 视频理解
📋 核心要点
- 现有视频MAE模型训练效率低,且潜在空间预测易出现表征坍塌问题。
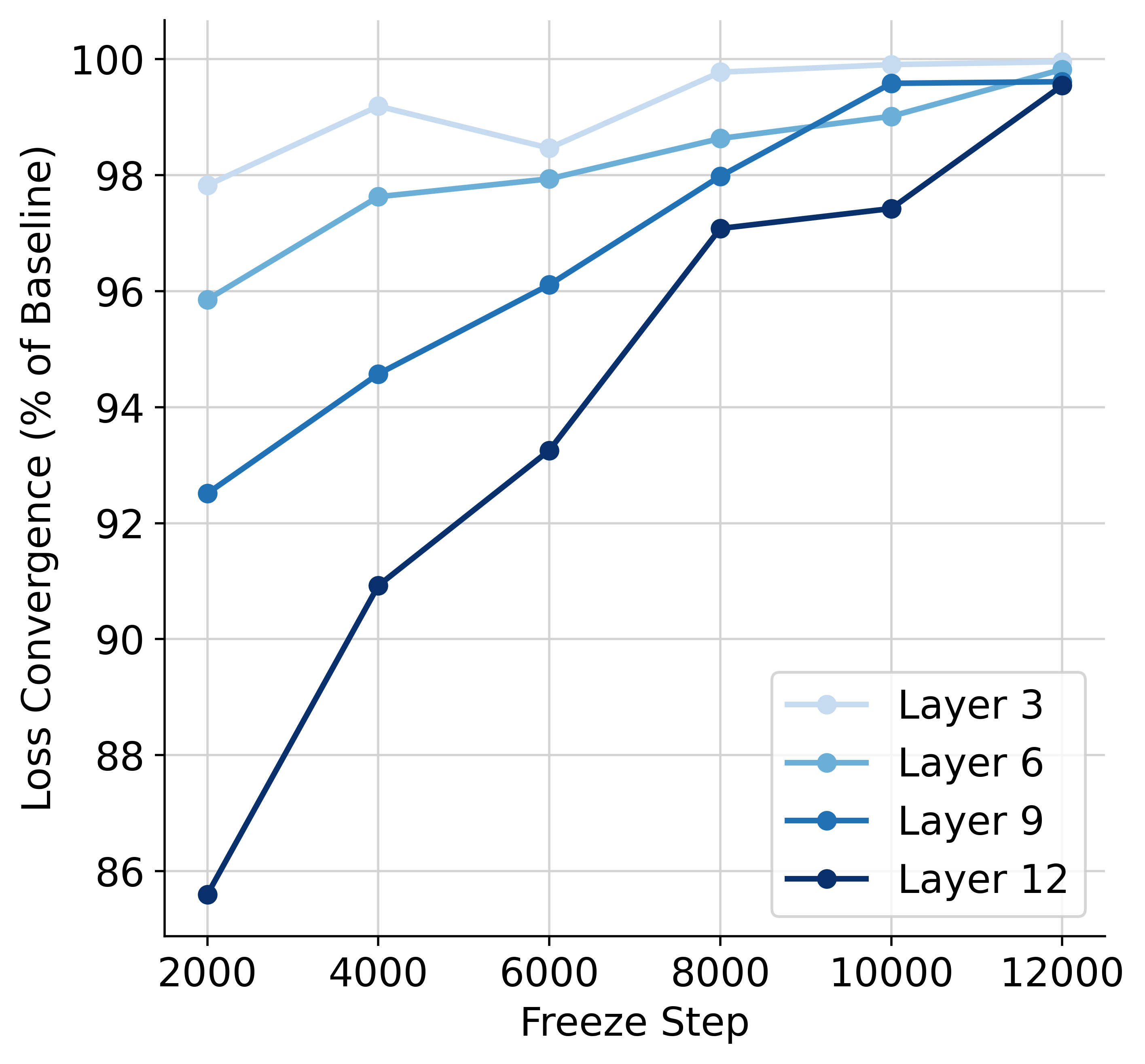
- LayerLock通过观察ViT层收敛速度差异,提出渐进式层冻结策略,加速训练并避免表征坍塌。
- 实验表明,LayerLock在大型模型上优于非潜在空间掩码预测,提升了4DS感知套件的性能。
📝 摘要(中文)
本文提出LayerLock,一种简单而有效的自监督视觉表征学习方法,通过渐进式层冻结,逐步从像素预测过渡到潜在空间预测。研究发现,在视频掩码自编码器(MAE)模型的训练过程中,ViT层的收敛速度与其深度相关:浅层收敛早,深层收敛晚。基于此,本文提出可以通过根据显式的时间表逐步冻结模型来加速标准MAE的训练。此外,该时间表可以应用于一种简单且可扩展的潜在空间预测方法,且不会遭受“表征坍塌”问题。本文将LayerLock应用于高达40亿参数的大型模型,在4DS感知套件上的结果超过了非潜在空间掩码预测。
🔬 方法详解
问题定义:现有的视频掩码自编码器(MAE)训练计算成本高昂,尤其是在处理大型模型时。此外,直接在潜在空间进行预测容易导致表征坍塌,即模型学习到的表征缺乏区分性,所有输入都映射到相似的输出。
核心思路:LayerLock的核心思想是利用ViT网络不同深度层收敛速度的差异。浅层网络收敛更快,因此可以更早地冻结,从而减少计算量。同时,通过逐步冻结,模型可以从像素级别的重建任务过渡到更抽象的潜在空间预测,避免表征坍塌。
技术框架:LayerLock的训练过程包括以下几个阶段:首先,使用标准的掩码自编码器进行预训练。然后,根据预先设定的时间表,逐步冻结ViT网络的浅层。在冻结部分层后,模型开始学习在潜在空间中进行预测。整个过程通过一个精心设计的损失函数进行优化,该损失函数结合了像素重建损失和潜在空间预测损失。
关键创新:LayerLock的关键创新在于渐进式层冻结策略。与传统的MAE方法相比,LayerLock能够显著加速训练过程,并避免表征坍塌。此外,LayerLock提供了一种简单且可扩展的潜在空间预测方法,可以应用于各种自监督学习任务。
关键设计:LayerLock的关键设计包括:1)一个明确的层冻结时间表,该时间表基于对ViT层收敛速度的观察。2)一个结合了像素重建损失和潜在空间预测损失的损失函数,用于优化模型。3)使用ViT作为主干网络,并针对视频数据进行了优化。具体参数设置(如掩码比例、冻结层数等)需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
LayerLock在4DS感知套件上取得了显著的性能提升,超越了非潜在空间掩码预测方法。实验结果表明,LayerLock能够有效地学习到高质量的视觉表征,并且能够避免表征坍塌。此外,LayerLock的训练速度比传统的MAE方法更快,尤其是在处理大型模型时。
🎯 应用场景
LayerLock可应用于视频理解、动作识别、视频生成等领域。通过学习高质量的视觉表征,可以提升下游任务的性能。此外,LayerLock的渐进式训练策略可以推广到其他深度学习模型,加速训练并提高模型的泛化能力。该方法在自动驾驶、机器人等需要高效表征学习的领域具有潜在的应用价值。
📄 摘要(原文)
We introduce LayerLock, a simple yet effective approach for self-supervised visual representation learning, that gradually transitions from pixel to latent prediction through progressive layer freezing. First, we make the observation that during training of video masked-autoencoding (MAE) models, ViT layers converge in the order of their depth: shallower layers converge early, deeper layers converge late. We then show that this observation can be exploited to accelerate standard MAE by progressively freezing the model according to an explicit schedule, throughout training. Furthermore, this same schedule can be used in a simple and scalable approach to latent prediction that does not suffer from "representation collapse". We apply our proposed approach, LayerLock, to large models of up to 4B parameters with results surpassing those of non-latent masked prediction on the 4DS perception suite.