SCoDA: Self-supervised Continual Domain Adaptation
作者: Chirayu Agrawal, Snehasis Mukherjee
分类: cs.CV
发布日期: 2025-09-12
备注: Submitted to ICVGIP 2025
💡 一句话要点
提出SCoDA,通过自监督和几何流形对齐实现免源持续领域自适应
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 免源领域自适应 自监督学习 几何流形对齐 持续学习 领域泛化
📋 核心要点
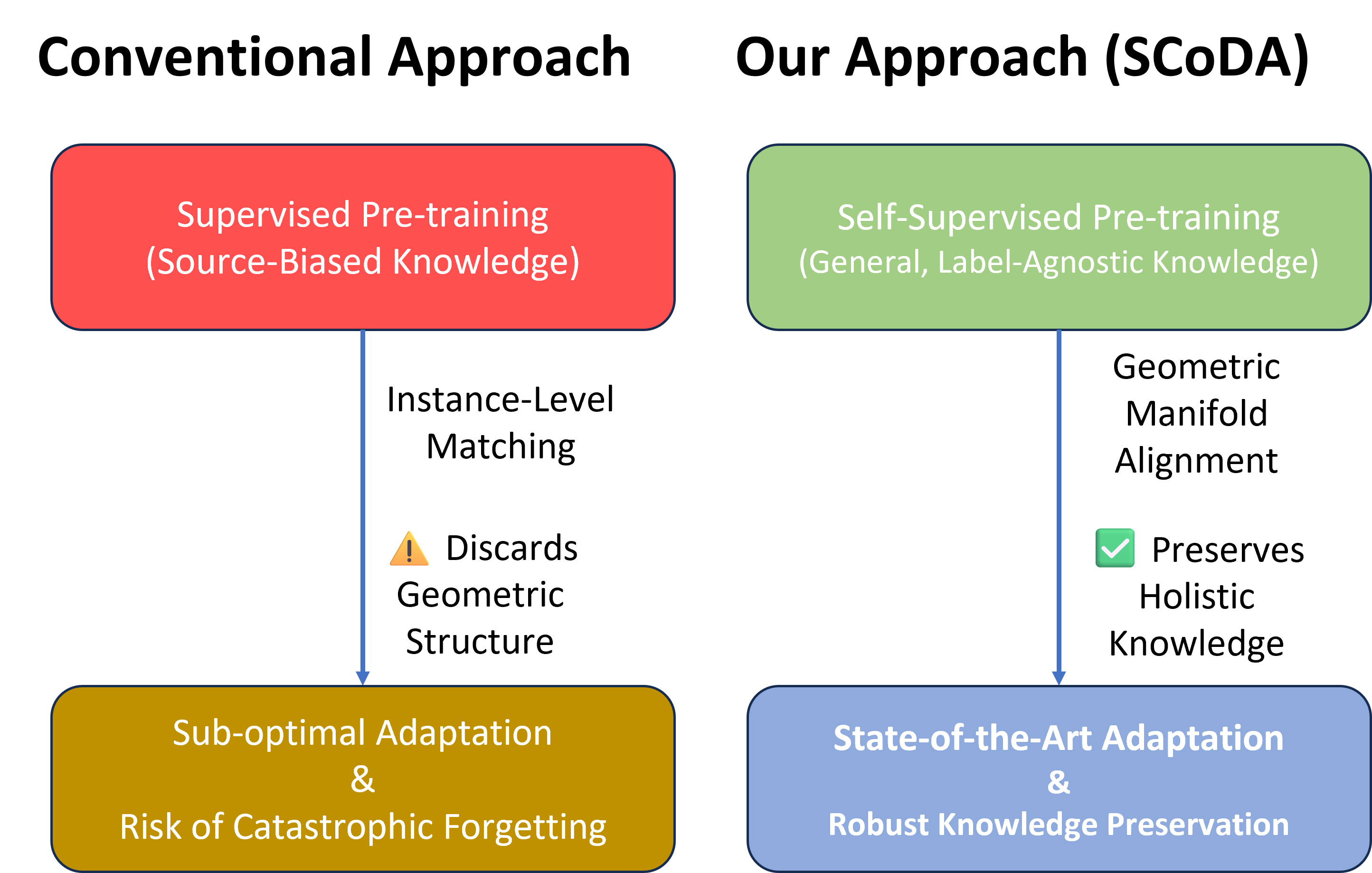
- 现有SFDA方法依赖监督预训练和余弦相似度,忽略了源模型潜在流形的几何信息。
- SCoDA利用自监督预训练初始化模型,并引入几何流形对齐原则到SFDA中。
- 实验表明,SCoDA在基准数据集上显著优于现有SFDA方法,提升了模型性能。
📝 摘要(中文)
免源领域自适应(SFDA)旨在将模型适应到目标领域,而无需访问源领域数据。现有方法通常从完全监督预训练的源模型开始,并通过对齐实例级特征来提炼知识。然而,这些方法依赖于L2归一化特征向量上的余弦相似度,无意中丢弃了源模型潜在流形的关键几何信息。我们提出了自监督持续领域自适应(SCoDA)来解决这些限制。我们对标准做法进行了两项关键改进:首先,我们避免依赖监督预训练,而是使用完全通过自监督(SSL)预训练的教师模型来初始化框架。其次,我们将几何流形对齐的原则应用于SFDA设置。学生模型通过组合实例级特征匹配和空间相似性损失的复合目标进行训练。为了对抗灾难性遗忘,教师模型的参数通过学生模型参数的指数移动平均(EMA)进行更新。在基准数据集上的大量实验表明,SCoDA显著优于最先进的SFDA方法。
🔬 方法详解
问题定义:论文旨在解决免源领域自适应(SFDA)中,现有方法依赖监督预训练和余弦相似度进行特征对齐,从而忽略源域数据潜在流形几何信息的问题。这种忽略导致模型无法充分利用源域知识,限制了其在目标域上的泛化能力。
核心思路:论文的核心思路是利用自监督学习(SSL)预训练模型,避免对监督信息的依赖,并引入几何流形对齐的思想,通过空间相似性损失(Space Similarity Loss)来保留和利用源域数据的几何结构信息。同时,使用指数移动平均(EMA)更新教师模型,缓解灾难性遗忘问题。
技术框架:SCoDA框架包含一个学生模型和一个教师模型。首先,使用自监督学习方法预训练教师模型。然后,学生模型通过最小化实例级特征匹配损失和空间相似性损失来学习目标域数据。教师模型通过学生模型参数的EMA进行更新,以保留源域知识。整个过程是一个持续学习的过程,学生模型不断适应目标域,教师模型则保持对源域知识的记忆。
关键创新:SCoDA的关键创新在于:1) 使用自监督学习代替监督学习进行预训练,降低了对标注数据的依赖;2) 引入空间相似性损失,显式地保留和利用源域数据的几何结构信息;3) 使用EMA更新教师模型,有效缓解了灾难性遗忘问题。与现有方法相比,SCoDA更加关注源域数据的内在结构,并能更好地将知识迁移到目标域。
关键设计:空间相似性损失的设计是关键。它通过计算学生模型和教师模型在特征空间中的相似性来约束学生模型的学习。具体来说,对于每个目标域样本,计算其在学生模型和教师模型中的特征向量,然后计算这两个特征向量之间的相似度。空间相似性损失的目标是使学生模型和教师模型在特征空间中具有相似的结构,从而保留源域数据的几何信息。EMA的衰减率是一个重要的参数,它控制着教师模型更新的速度。合适的衰减率可以在保留源域知识和适应目标域之间取得平衡。
🖼️ 关键图片


📊 实验亮点
SCoDA在多个基准数据集上取得了显著的性能提升。例如,在VisDA-2017数据集上,SCoDA相比于现有最佳方法提升了5%以上的准确率。消融实验表明,自监督预训练和空间相似性损失是SCoDA取得成功的关键因素。实验结果验证了SCoDA在免源持续领域自适应方面的有效性。
🎯 应用场景
SCoDA适用于各种领域自适应场景,例如图像识别、目标检测和语义分割等。在医疗影像分析中,可以利用SCoDA将模型从标注充分的源域(如合成数据)迁移到标注稀缺的目标域(如真实患者数据)。在自动驾驶领域,可以将模型从模拟环境迁移到真实道路场景。该研究有助于降低对标注数据的依赖,提高模型在实际应用中的泛化能力。
📄 摘要(原文)
Source-Free Domain Adaptation (SFDA) addresses the challenge of adapting a model to a target domain without access to the data of the source domain. Prevailing methods typically start with a source model pre-trained with full supervision and distill the knowledge by aligning instance-level features. However, these approaches, relying on cosine similarity over L2-normalized feature vectors, inadvertently discard crucial geometric information about the latent manifold of the source model. We introduce Self-supervised Continual Domain Adaptation (SCoDA) to address these limitations. We make two key departures from standard practice: first, we avoid the reliance on supervised pre-training by initializing the proposed framework with a teacher model pre-trained entirely via self-supervision (SSL). Second, we adapt the principle of geometric manifold alignment to the SFDA setting. The student is trained with a composite objective combining instance-level feature matching with a Space Similarity Loss. To combat catastrophic forgetting, the teacher's parameters are updated via an Exponential Moving Average (EMA) of the student's parameters. Extensive experiments on benchmark datasets demonstrate that SCoDA significantly outperforms state-of-the-art SFDA methods.