DGFusion: Depth-Guided Sensor Fusion for Robust Semantic Perception
作者: Tim Broedermannn, Christos Sakaridis, Luigi Piccinelli, Wim Abbeloos, Luc Van Gool
分类: cs.CV, cs.LG, cs.RO
发布日期: 2025-09-11 (更新: 2026-01-26)
备注: Code and models are available at https://github.com/timbroed/DGFusion
🔗 代码/项目: GITHUB
💡 一句话要点
DGFusion:深度引导的传感器融合,提升语义感知鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 传感器融合 深度学习 语义分割 全景分割 自动驾驶 深度估计
📋 核心要点
- 现有传感器融合方法在处理自动驾驶场景时,未能充分考虑传感器在不同空间位置的可靠性差异,导致在恶劣条件下性能下降。
- DGFusion利用激光雷达深度信息,学习深度感知的特征表示,并将其编码为局部深度token,动态调节跨模态融合过程。
- 该方法在MUSES和DeLiVER数据集上取得了state-of-the-art的全景和语义分割结果,验证了其在复杂场景下的有效性。
📝 摘要(中文)
针对自动驾驶车辆的鲁棒语义感知依赖于有效融合具有互补优势和劣势的多种传感器。目前最先进的语义感知传感器融合方法通常在输入的整个空间范围内统一处理传感器数据,这在面临挑战性条件时会阻碍性能。与此相反,我们提出了一种新颖的深度引导多模态融合方法,通过整合深度信息来升级条件感知融合。我们的网络DGFusion将多模态分割作为一个多任务问题,利用激光雷达测量(通常在室外传感器套件中可用)作为模型的输入之一,并作为学习深度的ground truth。我们相应的辅助深度头有助于学习深度感知特征,这些特征被编码为空间变化的局部深度token,从而调节我们的注意力跨模态融合。与全局条件token一起,这些局部深度token动态地使传感器融合适应场景中每个传感器的空间变化可靠性,这很大程度上取决于深度。此外,我们为深度提出了一种鲁棒的损失函数,这对于从通常在不利条件下稀疏且嘈杂的激光雷达输入中学习至关重要。我们的方法在具有挑战性的MUSES和DeLiVER数据集上实现了最先进的全景和语义分割性能。
🔬 方法详解
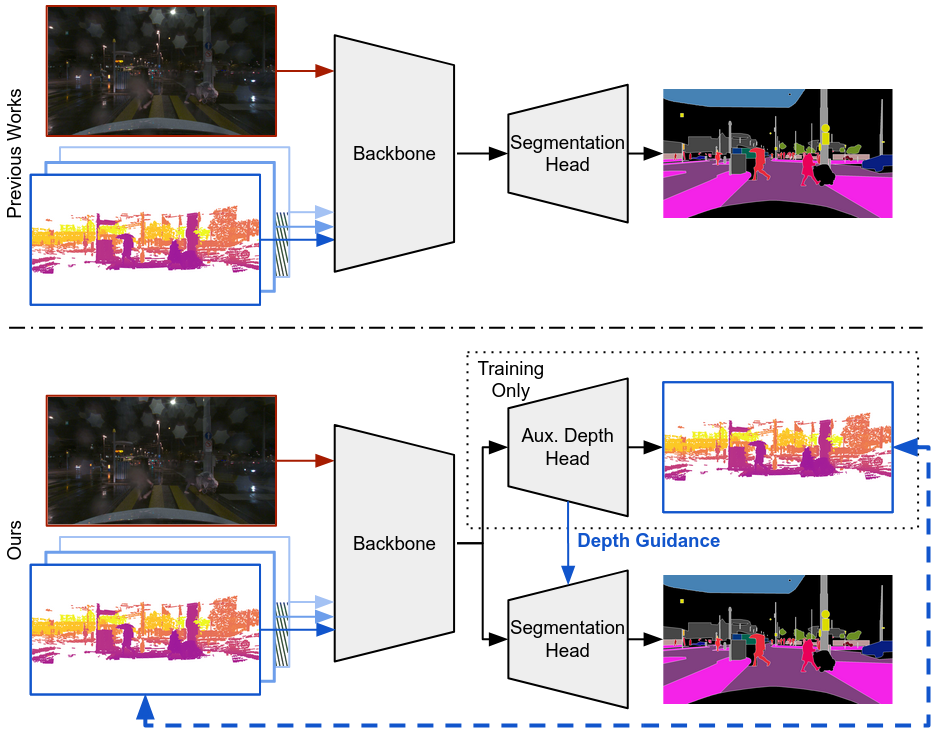
问题定义:论文旨在解决自动驾驶场景下,多传感器融合过程中,由于传感器自身特性和环境因素影响,导致不同传感器在不同区域的可靠性存在差异,进而影响语义感知鲁棒性的问题。现有方法通常对所有传感器数据进行统一处理,忽略了这种空间差异性,在恶劣天气或遮挡情况下表现不佳。
核心思路:论文的核心思路是利用深度信息(通常由激光雷达提供)作为指导,动态地调整不同传感器在不同区域的权重,从而实现更鲁棒的传感器融合。通过学习深度感知的特征表示,并将其编码为局部深度token,可以更好地捕捉场景中不同区域的深度信息,并根据深度信息调整跨模态融合策略。
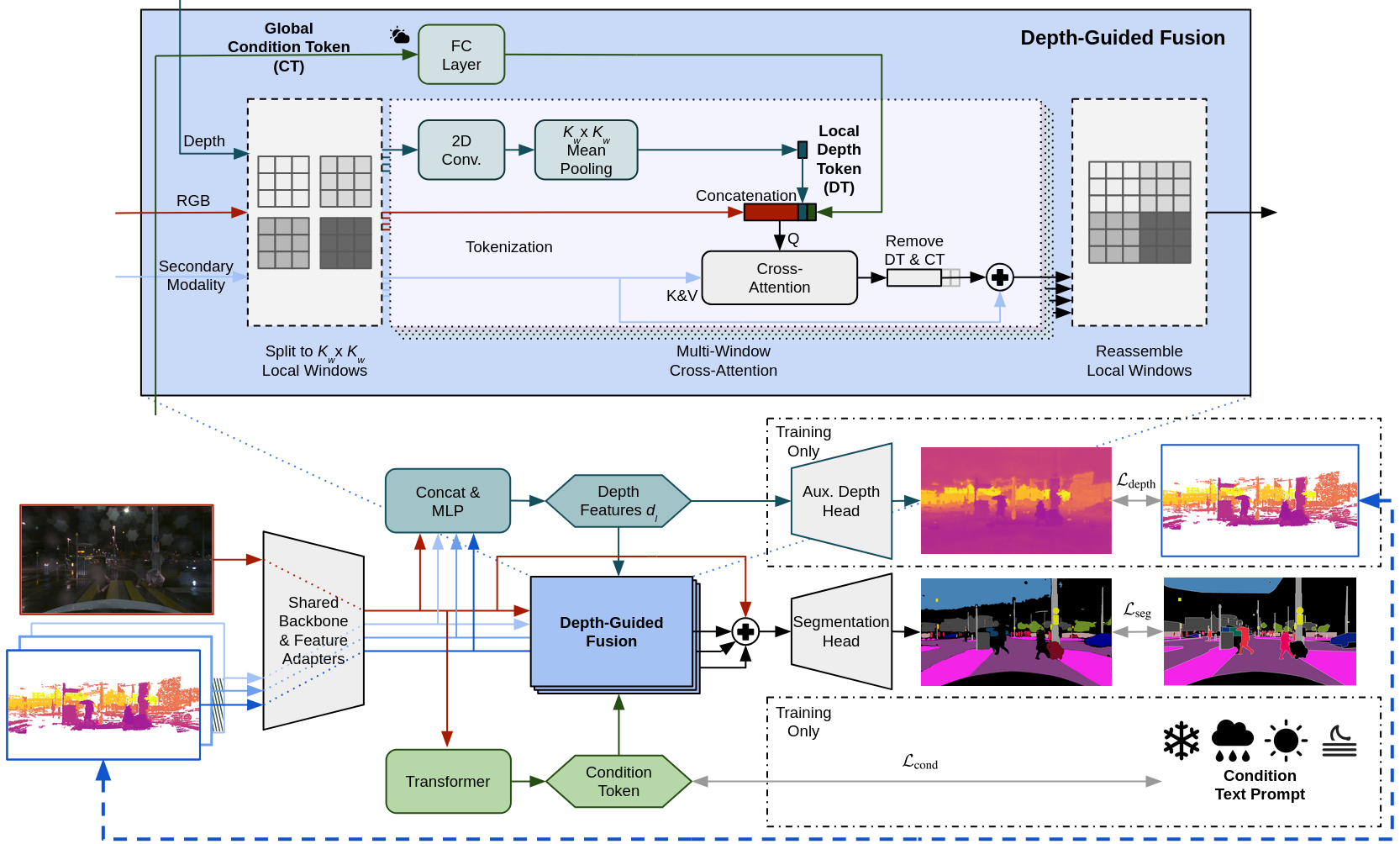
技术框架:DGFusion网络将多模态分割作为一个多任务问题来处理。整体架构包含以下几个主要模块:1) 多模态输入:接收来自不同传感器的输入数据,例如图像和激光雷达点云。2) 深度预测分支:利用激光雷达数据作为ground truth,学习深度预测。3) 特征提取:提取来自不同模态的特征。4) 深度token生成:将深度预测结果编码为空间变化的局部深度token。5) 注意力跨模态融合:利用深度token和全局条件token,动态调整不同模态特征的融合权重。6) 分割预测:输出语义分割和全景分割结果。
关键创新:论文的关键创新在于提出了深度引导的传感器融合机制。通过学习深度感知的特征表示,并将其编码为局部深度token,可以动态地调整不同传感器在不同区域的权重,从而实现更鲁棒的传感器融合。与现有方法相比,DGFusion能够更好地利用深度信息,并根据深度信息调整跨模态融合策略,从而在恶劣天气或遮挡情况下表现更好。
关键设计:论文的关键设计包括:1) 辅助深度头:用于学习深度感知的特征表示。2) 局部深度token:用于编码空间变化的深度信息。3) 注意力跨模态融合:利用深度token和全局条件token,动态调整不同模态特征的融合权重。4) 鲁棒的深度损失函数:用于从稀疏且嘈杂的激光雷达数据中学习深度信息。具体损失函数形式未知。
🖼️ 关键图片

📊 实验亮点
DGFusion在MUSES和DeLiVER数据集上实现了state-of-the-art的全景和语义分割性能。具体提升幅度未知,但结果表明该方法在复杂场景下具有显著优势。该方法通过深度引导的传感器融合,有效提升了在恶劣天气和遮挡条件下的感知鲁棒性。
🎯 应用场景
DGFusion技术可应用于自动驾驶、机器人导航、智能监控等领域。通过提升在复杂环境下的感知鲁棒性,可以提高自动驾驶车辆的安全性和可靠性,增强机器人在复杂环境中的适应能力,并改善智能监控系统的性能。该技术有望推动相关领域的智能化发展。
📄 摘要(原文)
Robust semantic perception for autonomous vehicles relies on effectively combining multiple sensors with complementary strengths and weaknesses. State-of-the-art sensor fusion approaches to semantic perception often treat sensor data uniformly across the spatial extent of the input, which hinders performance when faced with challenging conditions. By contrast, we propose a novel depth-guided multimodal fusion method that upgrades condition-aware fusion by integrating depth information. Our network, DGFusion, poses multimodal segmentation as a multi-task problem, utilizing the lidar measurements, which are typically available in outdoor sensor suites, both as one of the model's inputs and as ground truth for learning depth. Our corresponding auxiliary depth head helps to learn depth-aware features, which are encoded into spatially varying local depth tokens that condition our attentive cross-modal fusion. Together with a global condition token, these local depth tokens dynamically adapt sensor fusion to the spatially varying reliability of each sensor across the scene, which largely depends on depth. In addition, we propose a robust loss for our depth, which is essential for learning from lidar inputs that are typically sparse and noisy in adverse conditions. Our method achieves state-of-the-art panoptic and semantic segmentation performance on the challenging MUSES and DeLiVER datasets. Code and models are available at https://github.com/timbroed/DGFusion