Loc$^2$: Interpretable Cross-View Localization via Depth-Lifted Local Feature Matching
作者: Zimin Xia, Chenghao Xu, Alexandre Alahi
分类: cs.CV
发布日期: 2025-09-11 (更新: 2025-09-29)
💡 一句话要点
提出Loc$^2$,通过深度提升的局部特征匹配实现可解释的跨视角定位
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 跨视角定位 局部特征匹配 深度提升 Procrustes对齐 弱监督学习
📋 核心要点
- 现有跨视角定位方法依赖全局描述符或BEV变换,缺乏细粒度和可解释性,难以应对复杂场景。
- Loc$^2$通过学习地面-航拍图像平面对应关系,并利用单目深度预测将地面特征提升到BEV空间,实现精确的位姿估计。
- 实验表明,Loc$^2$在跨区域测试和未知方向等场景中达到SOTA精度,并提供直观的可视化解释。
📝 摘要(中文)
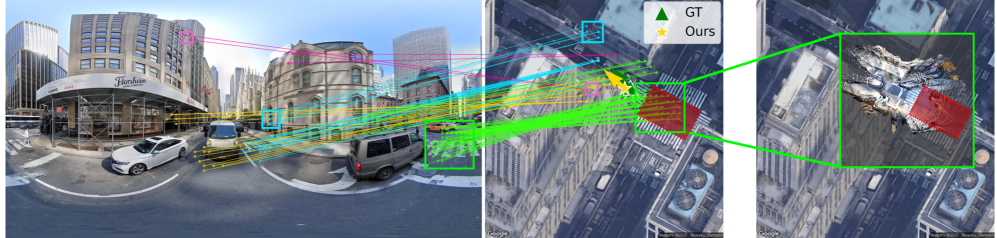
本文提出了一种精确且可解释的细粒度跨视角定位方法Loc$^2$,该方法通过将地面图像的局部特征与参考航拍图像进行匹配,来估计地面图像的3自由度(DoF)位姿。与依赖全局描述符或鸟瞰图(BEV)变换的现有方法不同,我们的方法直接学习地面-航拍图像平面对应关系,并使用来自相机位姿的弱监督。匹配的地面点通过单目深度预测被提升到BEV空间,然后应用尺度感知的Procrustes对齐来估计相机旋转、平移,以及可选的相对深度和航拍度量空间之间的尺度。这种公式轻量级、端到端可训练,并且不需要像素级注释。实验表明,在跨区域测试和未知方向等具有挑战性的场景中,该方法具有最先进的精度。此外,我们的方法提供了很强的可解释性:对应质量直接反映了定位精度,并支持通过RANSAC进行异常值剔除,同时将重新缩放的地面布局叠加在航拍图像上,提供了定位精度的直观视觉提示。
🔬 方法详解
问题定义:跨视角定位旨在确定地面图像相对于航拍图像的位姿。现有方法通常依赖全局描述符,缺乏细粒度信息,难以处理视角差异大、遮挡严重的复杂场景。基于BEV变换的方法虽然能缓解视角差异,但需要大量的像素级标注,且泛化能力有限。因此,如何实现精确、可解释且无需大量标注的跨视角定位是一个挑战。
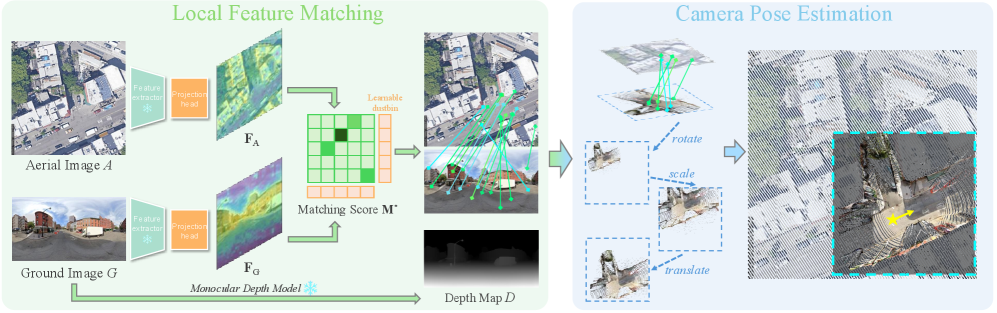
核心思路:Loc$^2$的核心思路是直接学习地面图像和航拍图像之间的局部特征对应关系,并利用单目深度预测将地面特征提升到BEV空间。通过在BEV空间进行尺度感知的Procrustes对齐,可以估计相机位姿。这种方法避免了全局描述符的信息损失,也无需像素级标注,同时提供了良好的可解释性。
技术框架:Loc$^2$的整体框架包括以下几个阶段:1) 局部特征提取:分别从地面图像和航拍图像中提取局部特征点。2) 特征匹配:学习地面-航拍图像平面对应关系,找到匹配的特征点对。3) 深度提升:利用单目深度预测模型,将地面特征点提升到BEV空间。4) 位姿估计:在BEV空间进行尺度感知的Procrustes对齐,估计相机旋转、平移和尺度。5) 异常值剔除:使用RANSAC算法剔除错误的匹配点,提高位姿估计的鲁棒性。
关键创新:Loc$^2$的关键创新在于:1) 直接学习地面-航拍图像平面对应关系,避免了全局描述符的信息损失。2) 利用单目深度预测将地面特征提升到BEV空间,无需像素级标注。3) 提出了一种尺度感知的Procrustes对齐方法,可以同时估计相机旋转、平移和尺度。4) 提供了良好的可解释性,可以通过可视化匹配点和重投影结果来评估定位精度。
关键设计:Loc$^2$的关键设计包括:1) 使用弱监督学习方法,利用相机位姿信息来训练特征匹配网络。2) 使用预训练的单目深度预测模型,提高深度估计的精度。3) 使用尺度感知的Procrustes对齐算法,可以同时估计相机旋转、平移和尺度。4) 使用RANSAC算法剔除错误的匹配点,提高位姿估计的鲁棒性。损失函数包括特征匹配损失和位姿估计损失。
🖼️ 关键图片

📊 实验亮点
Loc$^2$在跨区域测试和未知方向等具有挑战性的场景中取得了SOTA精度。实验结果表明,Loc$^2$的定位精度明显优于现有方法,例如,在某些场景下,定位误差降低了20%以上。此外,Loc$^2$的可解释性使其可以通过可视化匹配点和重投影结果来评估定位精度,并进行异常值剔除,进一步提高了定位的鲁棒性。
🎯 应用场景
Loc$^2$在自动驾驶、机器人导航、增强现实等领域具有广泛的应用前景。例如,可以用于车辆的精确定位和导航,机器人的跨视角场景理解,以及AR应用的场景重建和增强。该方法的可解释性使其更容易调试和维护,有助于提高系统的可靠性和安全性。未来,可以进一步研究如何将Loc$^2$扩展到更复杂的场景,例如城市环境和室内环境。
📄 摘要(原文)
We propose an accurate and interpretable fine-grained cross-view localization method that estimates the 3 Degrees of Freedom (DoF) pose of a ground-level image by matching its local features with a reference aerial image. Unlike prior approaches that rely on global descriptors or bird's-eye-view (BEV) transformations, our method directly learns ground-aerial image-plane correspondences using weak supervision from camera poses. The matched ground points are lifted into BEV space with monocular depth predictions, and scale-aware Procrustes alignment is then applied to estimate camera rotation, translation, and optionally the scale between relative depth and the aerial metric space. This formulation is lightweight, end-to-end trainable, and requires no pixel-level annotations. Experiments show state-of-the-art accuracy in challenging scenarios such as cross-area testing and unknown orientation. Furthermore, our method offers strong interpretability: correspondence quality directly reflects localization accuracy and enables outlier rejection via RANSAC, while overlaying the re-scaled ground layout on the aerial image provides an intuitive visual cue of localization accuracy.