Unified Multimodal Model as Auto-Encoder
作者: Zhiyuan Yan, Kaiqing Lin, Zongjian Li, Junyan Ye, Hui Han, Zhendong Wang, Hao Liu, Bin Lin, Hao Li, Xue Xu, Xinyan Xiao, Jingdong Wang, Haifeng Wang, Li Yuan
分类: cs.CV
发布日期: 2025-09-11 (更新: 2025-10-10)
💡 一句话要点
提出基于自编码器的统一多模态模型UAE,实现理解与生成的双向提升。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 统一多模态模型 自编码器 多模态理解 多模态生成 强化学习 图像描述 文本到图像
📋 核心要点
- 现有统一多模态模型通常将理解和生成视为独立任务,忽略了两者之间的内在联系和互益关系。
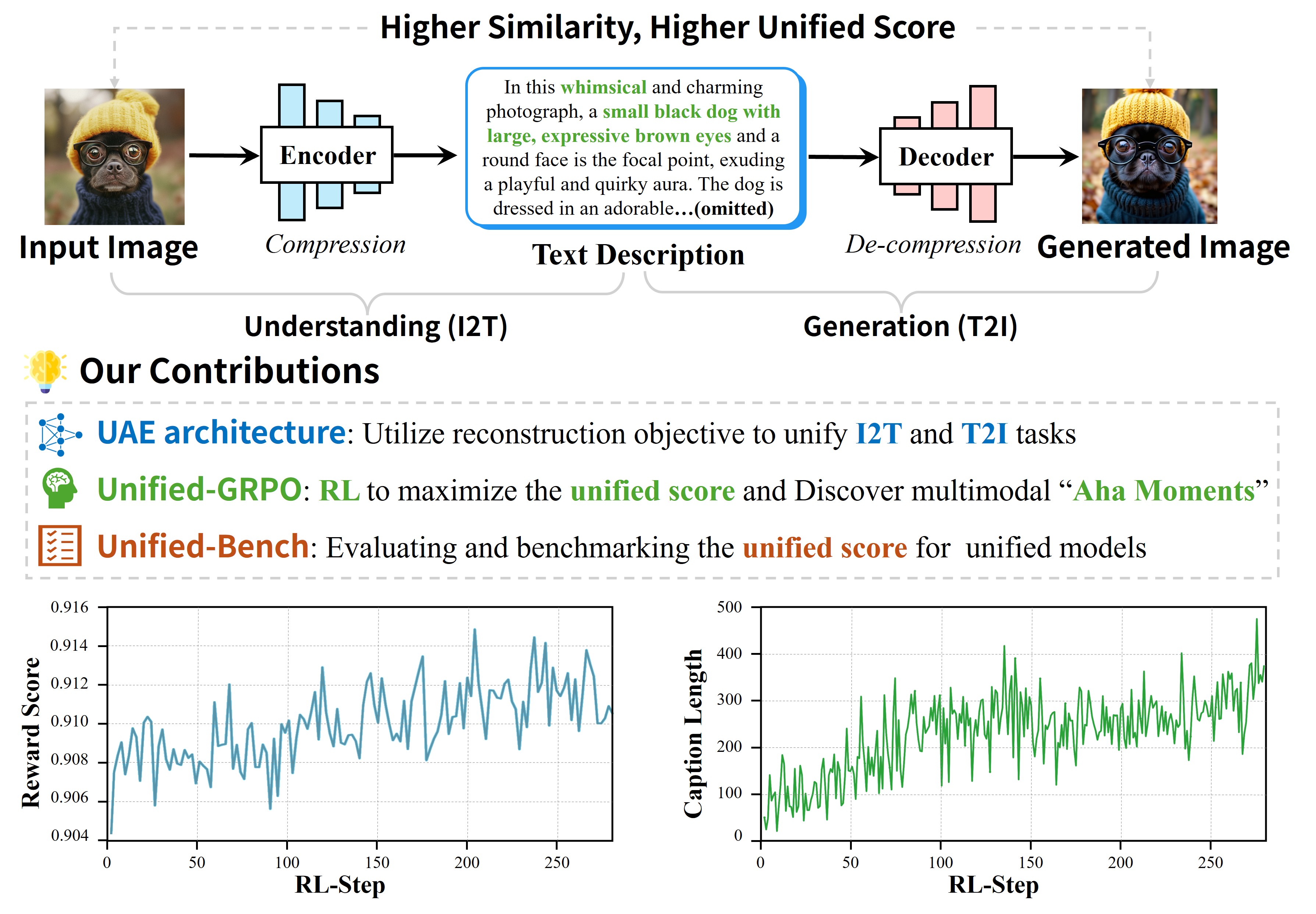
- 论文提出基于自编码器的统一框架UAE,将理解视为编码,生成视为解码,通过重建目标连接两者。
- 实验表明,该方法能够实现理解和生成的双向提升,尤其在细粒度视觉感知和长文本生成方面。
📝 摘要(中文)
统一多模态模型(UMMs)的构建长期以来受限于多模态理解和生成之间的根本分歧。现有方法通常将两者分离,视为具有不相交目标的不同任务,忽略了它们之间的互益关系。本文认为,真正的统一不仅仅是合并两个任务,更需要一个统一的基础目标,将它们内在联系起来。本文通过自编码器的视角,提出了一个富有洞察力的范例,即将理解视为编码器(I2T),将图像压缩成文本,将生成视为解码器(T2I),从文本重建图像。为此,我们提出了UAE,首先使用提出的70万长上下文图像-标题对预训练解码器,引导其“理解”文本中的细粒度和复杂语义。然后,我们通过强化学习(RL)提出Unified-GRPO来统一两者,涵盖两个互补阶段:(1)生成促进理解,训练编码器生成信息丰富的标题,以最大限度地提高解码器的重建质量,从而增强其视觉感知;(2)理解促进生成,改进解码器以从这些标题重建,迫使其利用每个细节,并提高其长上下文指令跟随和生成保真度。实验结果表明,理解可以极大地增强生成(在GenEval上验证),而生成反过来显着加强了细粒度的视觉感知,例如小物体和颜色识别(在MMT-Bench上验证)。这种双向改进揭示了一种深刻的协同作用:在统一的重建目标下,生成和理解可以相互受益,从而更接近真正统一的多模态智能。
🔬 方法详解
问题定义:现有统一多模态模型通常将多模态理解(如图像到文本)和多模态生成(如文本到图像)视为两个独立的任务,使用不同的目标函数和训练策略。这种分离忽略了理解和生成之间的内在联系,无法充分利用它们之间的互补性。现有方法的痛点在于缺乏一个统一的框架,能够同时优化理解和生成能力,从而实现真正意义上的多模态智能。
核心思路:论文的核心思路是将多模态理解和生成统一到一个自编码器的框架中。具体来说,将图像到文本的过程视为编码器,将文本到图像的过程视为解码器。通过训练模型重建输入图像,可以同时优化编码器(理解能力)和解码器(生成能力)。这种设计基于一个假设:高质量的理解能够产生更好的生成结果,反之亦然。
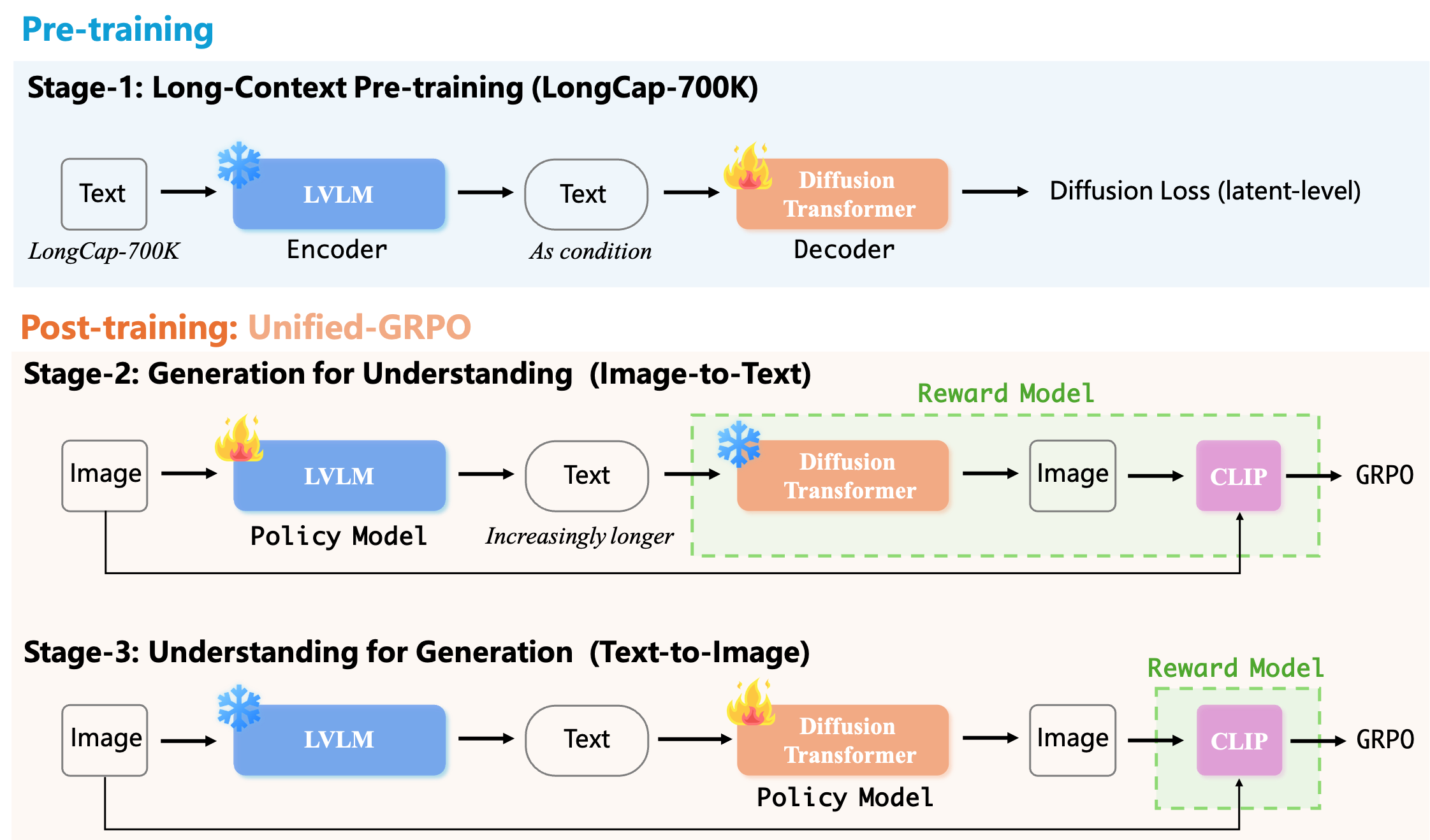
技术框架:整体框架包含两个主要阶段:预训练和联合训练。 1. 预训练阶段:使用大规模图像-文本对数据集预训练解码器(文本到图像生成模型),使其具备从文本中生成高质量图像的能力。 2. 联合训练阶段:使用强化学习方法Unified-GRPO,交替优化编码器和解码器。该阶段包含两个子阶段: - 生成促进理解:训练编码器生成信息丰富的文本描述,以最大化解码器重建图像的质量。 - 理解促进生成:训练解码器从编码器生成的文本描述中重建图像,迫使其利用文本中的所有细节。
关键创新:论文最重要的技术创新点在于提出了基于自编码器的统一多模态模型UAE,以及相应的联合训练策略Unified-GRPO。与现有方法相比,UAE将理解和生成统一到一个框架中,通过重建目标实现双向优化。Unified-GRPO则通过强化学习方法,有效地平衡了理解和生成之间的关系,实现了更好的性能。
关键设计: 1. 长上下文预训练:使用70万长上下文图像-文本对预训练解码器,使其具备处理复杂语义信息的能力。 2. 强化学习Unified-GRPO:使用强化学习方法优化编码器和解码器,奖励函数基于重建图像的质量。 3. 损失函数:使用重建损失(例如像素级别的均方误差)作为主要损失函数,同时可能结合其他辅助损失函数,例如文本描述的语言模型损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在GenEval和MMT-Bench等基准测试中取得了显著提升。具体来说,理解能力增强了生成质量,生成能力反过来又提高了细粒度视觉感知能力,例如小物体和颜色识别。这些结果验证了该方法在统一多模态理解和生成方面的有效性。
🎯 应用场景
该研究成果可应用于多种多模态任务,例如图像描述生成、文本到图像生成、视觉问答、跨模态检索等。其潜在应用领域包括智能客服、内容创作、教育娱乐等。通过提升多模态理解和生成能力,可以实现更智能、更自然的交互体验,并为人工智能的发展奠定基础。
📄 摘要(原文)
The pursuit of unified multimodal models (UMMs) has long been hindered by a fundamental schism between multimodal understanding and generation. Current approaches typically disentangle the two and treat them as separate endeavors with disjoint objectives, missing the mutual benefits. We argue that true unification requires more than just merging two tasks. It requires a unified, foundational objective that intrinsically links them. In this paper, we introduce an insightful paradigm through the Auto-Encoder lens, i.e., regarding understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. To implement this, we propose UAE, where we begin by pre-training the decoder with the proposed 700k long-context image-caption pairs to direct it to "understand" the fine-grained and complex semantics from the text. We then propose Unified-GRPO via reinforcement learning (RL) to unify the two, which covers two complementary stages: (1) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual perception; (2) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. Our empirical results suggest that understanding can largely enhance generation (verified on GenEval), while generation, in turn, notably strengthens fine-grained visual perception like small object and color recognition (verified on MMT-Bench). This bidirectional improvement reveals a deep synergy: under the unified reconstruction objective, generation and understanding can mutually benefit each other, moving closer to truly unified multimodal intelligence.