Video Understanding by Design: How Datasets Shape Architectures and Insights
作者: Lei Wang, Piotr Koniusz, Yongsheng Gao
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-09-11
备注: Research report
💡 一句话要点
从数据集视角解读视频理解:揭示数据集如何塑造模型架构与性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 数据集驱动 模型架构 归纳偏置 深度学习 计算机视觉
📋 核心要点
- 现有视频理解综述侧重模型分类,忽略了数据集对模型架构演变的关键影响。
- 本研究从数据集角度出发,分析数据集特性如何驱动模型设计,并提供模型设计的实用指导。
- 通过统一数据集、归纳偏置和架构,为通用视频理解提供全面的回顾和未来发展方向。
📝 摘要(中文)
视频理解领域发展迅速,这得益于日益复杂的数据集和强大的模型架构。然而,现有的综述大多按任务或模型家族对模型进行分类,忽略了数据集通过结构性压力引导架构演变的过程。本综述首次采用数据集驱动的视角,展示了运动复杂性、时间跨度、分层组成和多模态丰富性如何施加模型应编码的归纳偏置。我们将从双流网络和3D CNN到序列模型、Transformer和多模态基础模型的里程碑式进展,重新解释为对这些数据集驱动压力的具体响应。在此基础上,我们为模型设计与数据集不变性对齐,同时平衡可扩展性和任务需求,提供了实用的指导。通过将数据集、归纳偏置和架构统一到一个连贯的框架中,本综述为推进通用视频理解提供了全面的回顾和规范性的路线图。
🔬 方法详解
问题定义:现有视频理解研究通常孤立地看待数据集和模型架构,缺乏对数据集如何影响模型设计的系统性分析。现有综述主要关注模型本身,忽略了数据集的特性(如运动复杂性、时间跨度等)对模型架构选择的隐性约束。这导致研究人员在选择或设计模型时,难以充分利用数据集的内在信息,从而限制了模型的性能和泛化能力。
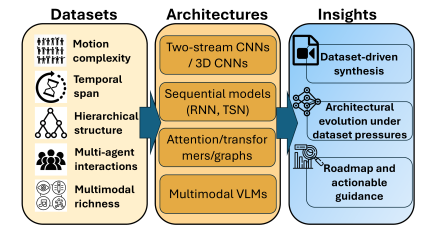
核心思路:本论文的核心思路是从数据集的角度出发,分析数据集的特性如何影响模型架构的设计。作者认为,数据集的特性(如运动复杂性、时间跨度、分层组成和多模态丰富性)会施加一定的归纳偏置,模型需要编码这些归纳偏置才能有效地理解视频内容。通过分析不同数据集的特性,可以指导模型架构的选择和设计,从而提高模型的性能和泛化能力。
技术框架:本论文构建了一个统一的框架,将数据集、归纳偏置和架构联系起来。该框架首先分析数据集的特性,然后确定相应的归纳偏置,最后选择或设计能够编码这些归纳偏置的模型架构。该框架涵盖了从双流网络和3D CNN到序列模型、Transformer和多模态基础模型的各种里程碑式进展,并将这些进展重新解释为对数据集驱动压力的具体响应。
关键创新:本论文最重要的创新点在于提出了数据集驱动的视频理解视角。与传统的模型驱动视角不同,本论文强调数据集的特性对模型设计的重要性。通过分析数据集的特性,可以更好地理解模型架构的选择和设计,从而提高模型的性能和泛化能力。此外,本论文还构建了一个统一的框架,将数据集、归纳偏置和架构联系起来,为视频理解研究提供了一个新的视角。
关键设计:论文的关键设计在于对数据集特性的分析和归纳偏置的提取。作者详细分析了运动复杂性、时间跨度、分层组成和多模态丰富性等数据集特性,并提出了相应的归纳偏置。例如,对于具有复杂运动的数据集,作者建议使用能够捕捉运动信息的模型,如3D CNN或光流网络。对于具有长时序依赖的数据集,作者建议使用能够建模长时序关系的序列模型或Transformer。
🖼️ 关键图片

📊 实验亮点
本论文是一篇综述性文章,没有提供具体的实验结果。其亮点在于提出了数据集驱动的视频理解视角,并构建了一个统一的框架,将数据集、归纳偏置和架构联系起来。该框架为视频理解研究提供了一个新的视角,并为模型设计提供了指导。
🎯 应用场景
该研究成果可应用于视频监控、自动驾驶、智能安防、人机交互等多个领域。通过理解数据集特性并选择合适的模型架构,可以提高视频理解系统的性能和鲁棒性,从而实现更智能化的应用。此外,该研究还为未来视频理解模型的设计提供了指导,有助于推动通用视频理解技术的发展。
📄 摘要(原文)
Video understanding has advanced rapidly, fueled by increasingly complex datasets and powerful architectures. Yet existing surveys largely classify models by task or family, overlooking the structural pressures through which datasets guide architectural evolution. This survey is the first to adopt a dataset-driven perspective, showing how motion complexity, temporal span, hierarchical composition, and multimodal richness impose inductive biases that models should encode. We reinterpret milestones, from two-stream and 3D CNNs to sequential, transformer, and multimodal foundation models, as concrete responses to these dataset-driven pressures. Building on this synthesis, we offer practical guidance for aligning model design with dataset invariances while balancing scalability and task demands. By unifying datasets, inductive biases, and architectures into a coherent framework, this survey provides both a comprehensive retrospective and a prescriptive roadmap for advancing general-purpose video understanding.