SQAP-VLA: A Synergistic Quantization-Aware Pruning Framework for High-Performance Vision-Language-Action Models
作者: Hengyu Fang, Yijiang Liu, Yuan Du, Li Du, Huanrui Yang
分类: cs.CV, cs.AI
发布日期: 2025-09-11
备注: 12 pages, 9 figures
💡 一句话要点
提出SQAP-VLA框架,协同量化与剪枝加速高性能视觉-语言-动作模型推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 模型压缩 量化 剪枝 推理加速 具身智能
📋 核心要点
- VLA模型计算和内存开销巨大,阻碍了实际部署,而现有压缩方法难以同时有效利用量化和剪枝。
- SQAP-VLA通过协同设计量化和剪枝流程,提出量化感知的剪枝标准,并优化量化器设计,克服了二者不兼容的问题。
- 实验表明,SQAP-VLA在加速推理的同时,保持甚至提升了VLA模型的性能,实现了显著的效率提升。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在具身智能方面展现了前所未有的能力。然而,其巨大的计算和内存成本阻碍了它们的实际部署。现有的VLA压缩和加速方法通常以临时的方式进行量化或token剪枝,但由于观察到的不兼容性,无法同时实现两者的整体效率提升。本文介绍了SQAP-VLA,这是第一个结构化的、无需训练的VLA推理加速框架,它同时实现了最先进的量化和token剪枝。我们通过共同设计量化和token剪枝流程来克服不兼容性,提出了新的量化感知token剪枝标准,该标准适用于激进量化的模型,同时改进了量化器的设计以提高剪枝效果。当应用于标准VLA模型时,SQAP-VLA在计算效率和推理速度方面产生了显著的增益,同时成功地保持了核心模型性能,与原始模型相比,实现了1.93倍的加速,并提高了高达4.5%的平均成功率。
🔬 方法详解
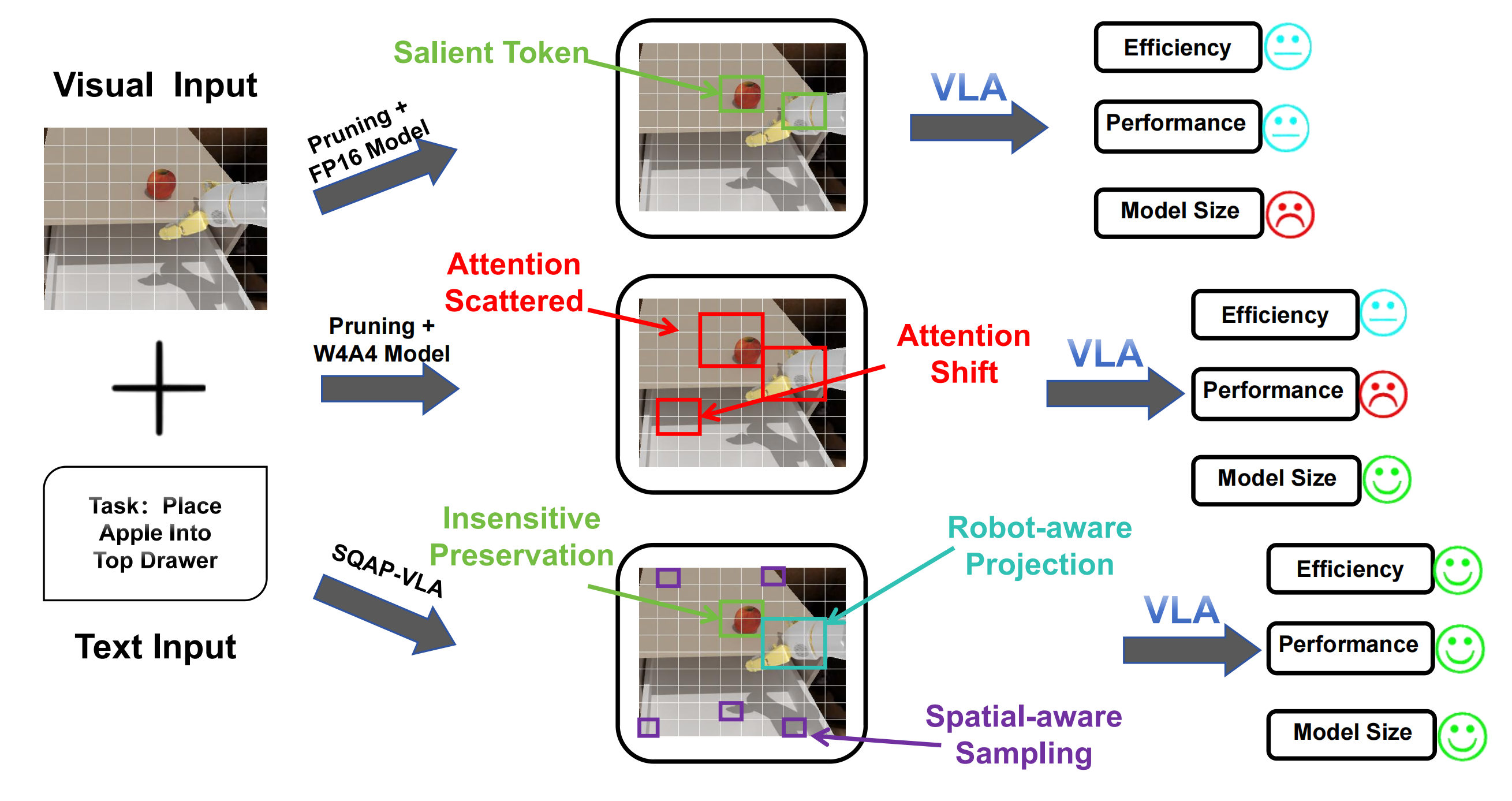
问题定义:VLA模型虽然在具身智能任务中表现出色,但其庞大的计算量和内存占用限制了其在实际场景中的部署。现有的模型压缩方法,如量化和token剪枝,通常独立进行,导致两者之间存在不兼容性,无法实现协同优化,从而限制了整体的加速效果。
核心思路:SQAP-VLA的核心思路是协同设计量化和token剪枝流程,打破两者之间的壁垒。通过提出量化感知的token剪枝标准,使得剪枝过程能够适应量化后的模型特性,同时优化量化器的设计,以提升剪枝的有效性。这种协同优化的方法旨在实现更高的压缩率和更低的性能损失。
技术框架:SQAP-VLA框架主要包含两个关键模块:量化模块和剪枝模块。首先,对模型进行量化,降低模型参数的精度。然后,利用量化感知的token剪枝标准,对模型中的冗余token进行剪枝。这两个模块协同工作,共同优化模型的计算效率和内存占用。整个过程无需额外的训练,降低了部署成本。
关键创新:SQAP-VLA的关键创新在于其量化感知的token剪枝标准。该标准考虑了量化对模型的影响,能够更准确地识别和去除对模型性能影响较小的token。此外,框架还优化了量化器的设计,使其更适合于剪枝后的模型,进一步提升了压缩效果。这种协同优化的方法是与现有方法的本质区别。
关键设计:量化模块采用了一种自适应的量化策略,根据不同层的特性选择不同的量化比特数。剪枝模块则基于量化后的模型参数,计算每个token的重要性得分,并根据得分进行剪枝。损失函数的设计目标是在剪枝的同时,尽可能地保持模型的性能。具体的参数设置需要根据不同的VLA模型进行调整。
🖼️ 关键图片


📊 实验亮点
SQAP-VLA框架在标准VLA模型上取得了显著的实验结果。与原始模型相比,SQAP-VLA实现了1.93倍的推理速度提升,并且平均成功率提高了高达4.5%。这些结果表明,SQAP-VLA能够在加速推理的同时,保持甚至提升VLA模型的性能。
🎯 应用场景
SQAP-VLA框架可应用于各种需要高性能和低延迟的具身智能应用场景,例如机器人导航、自动驾驶、智能家居等。通过降低VLA模型的计算和内存成本,该框架能够使这些模型在资源受限的设备上运行,从而推动具身智能技术的普及和应用。
📄 摘要(原文)
Vision-Language-Action (VLA) models exhibit unprecedented capabilities for embodied intelligence. However, their extensive computational and memory costs hinder their practical deployment. Existing VLA compression and acceleration approaches conduct quantization or token pruning in an ad-hoc manner but fail to enable both for a holistic efficiency improvement due to an observed incompatibility. This work introduces SQAP-VLA, the first structured, training-free VLA inference acceleration framework that simultaneously enables state-of-the-art quantization and token pruning. We overcome the incompatibility by co-designing the quantization and token pruning pipeline, where we propose new quantization-aware token pruning criteria that work on an aggressively quantized model while improving the quantizer design to enhance pruning effectiveness. When applied to standard VLA models, SQAP-VLA yields significant gains in computational efficiency and inference speed while successfully preserving core model performance, achieving a $\times$1.93 speedup and up to a 4.5\% average success rate enhancement compared to the original model.