Diffusion-Based Action Recognition Generalizes to Untrained Domains
作者: Rogerio Guimaraes, Frank Xiao, Pietro Perona, Markus Marks
分类: cs.CV
发布日期: 2025-09-10 (更新: 2025-09-22)
备注: Project page: https://www.vision.caltech.edu/actiondiff. Code: https://github.com/frankyaoxiao/ActionDiff
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于扩散模型的动作识别方法,提升模型在未训练域上的泛化能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 动作识别 扩散模型 泛化能力 Transformer 跨域学习
📋 核心要点
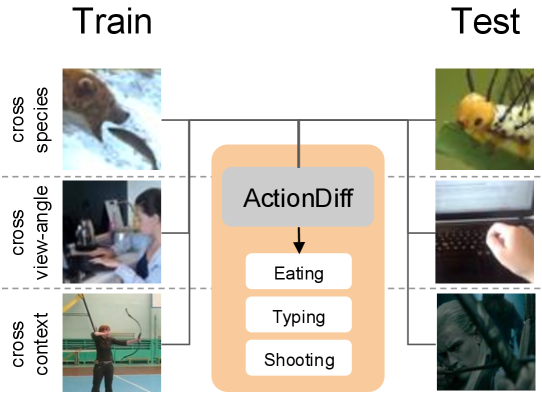
- 现有深度学习模型在动作识别中,难以泛化到具有显著上下文和视角差异的场景,如跨物种、视角和记录环境。
- 论文提出利用视觉扩散模型(VDM)提取特征,并使用Transformer进行聚合,从而提升模型在未训练域上的动作识别泛化能力。
- 实验结果表明,该方法在跨物种、跨视角和跨记录环境的动作识别任务中,均取得了state-of-the-art的性能。
📝 摘要(中文)
人类可以在上下文和视角发生巨大变化的情况下识别相同的动作,例如物种差异(蜘蛛与马的行走方式)、视角差异(第一人称与第三人称)以及上下文差异(现实生活与电影)。然而,当前的深度学习模型在泛化到这些具有挑战性的场景时表现不佳。本文提出了一种利用视觉扩散模型(VDM)生成的特征,并通过Transformer进行聚合的方法,以实现类似于人类的跨越这些挑战性条件的动作识别。研究发现,使用以扩散过程的早期时间步为条件的模型,可以突出提取特征中的语义信息而非像素级细节,从而增强泛化能力。通过实验,本文探索了该方法在跨动物物种、跨不同视角以及跨不同记录上下文的动作分类中的泛化性能。该模型在所有三个泛化基准测试中都达到了新的state-of-the-art水平,使机器动作识别更接近人类的鲁棒性。
🔬 方法详解
问题定义:现有动作识别模型在面对不同物种、视角和记录环境时,泛化能力较差。模型容易过拟合训练数据,难以适应未见过的场景。因此,需要一种能够提取更鲁棒、更具语义信息的特征表示,从而提升模型的泛化性能。
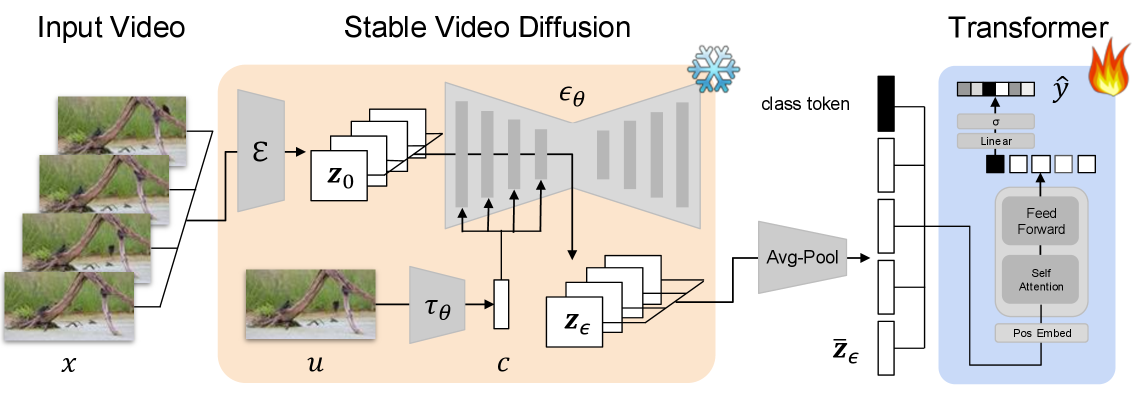
核心思路:论文的核心思路是利用视觉扩散模型(VDM)学习到的图像先验知识,提取对动作识别有用的特征。通过在扩散过程的早期时间步进行条件化,可以突出语义信息,抑制像素级别的细节,从而提高特征的鲁棒性。Transformer用于聚合这些特征,学习动作的全局表示。
技术框架:整体框架包括三个主要步骤:1) 使用预训练的视觉扩散模型(VDM)提取视频帧的特征。VDM在图像上进行训练,能够捕捉图像的底层结构和语义信息。2) 使用Transformer网络聚合从VDM提取的特征,学习视频的全局表示。Transformer能够捕捉长时依赖关系,对动作识别至关重要。3) 使用一个分类器,根据Transformer输出的全局表示,预测视频中的动作类别。
关键创新:最重要的创新点在于利用扩散模型提取特征,并使用扩散过程的早期时间步进行条件化。这种方法能够有效地提取语义信息,抑制像素级别的噪声,从而提高特征的鲁棒性。此外,将扩散模型与Transformer结合,能够充分利用两者的优势,进一步提升模型的性能。
关键设计:论文使用预训练的Stable Diffusion作为视觉扩散模型。在提取特征时,选择扩散过程的早期时间步(例如,t=50)进行条件化。Transformer的结构采用标准的Transformer Encoder,并使用交叉熵损失函数进行训练。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
该模型在跨物种、跨视角和跨记录环境的动作识别任务中均取得了state-of-the-art的性能。例如,在跨物种动作识别任务中,该模型相比现有方法有显著提升。实验结果表明,利用扩散模型提取的特征具有更强的鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于各种需要动作识别的场景,例如视频监控、人机交互、自动驾驶和机器人导航。通过提升模型在不同环境下的泛化能力,可以使这些应用更加可靠和实用。此外,该方法还可以推广到其他视觉任务,例如目标检测和图像分割。
📄 摘要(原文)
Humans can recognize the same actions despite large context and viewpoint variations, such as differences between species (walking in spiders vs. horses), viewpoints (egocentric vs. third-person), and contexts (real life vs movies). Current deep learning models struggle with such generalization. We propose using features generated by a Vision Diffusion Model (VDM), aggregated via a transformer, to achieve human-like action recognition across these challenging conditions. We find that generalization is enhanced by the use of a model conditioned on earlier timesteps of the diffusion process to highlight semantic information over pixel level details in the extracted features. We experimentally explore the generalization properties of our approach in classifying actions across animal species, across different viewing angles, and different recording contexts. Our model sets a new state-of-the-art across all three generalization benchmarks, bringing machine action recognition closer to human-like robustness. Project page: https://www.vision.caltech.edu/actiondiff. Code: https://github.com/frankyaoxiao/ActionDiff