RewardDance: Reward Scaling in Visual Generation
作者: Jie Wu, Yu Gao, Zilyu Ye, Ming Li, Liang Li, Hanzhong Guo, Jie Liu, Zeyue Xue, Xiaoxia Hou, Wei Liu, Yan Zeng, Weilin Huang
分类: cs.CV
发布日期: 2025-09-10
备注: Bytedance Seed Technical Report
💡 一句话要点
RewardDance:通过生成式奖励建模解决视觉生成中的奖励缩放和奖励利用问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉生成 奖励模型 强化学习 奖励缩放 奖励利用 视觉语言模型 生成式奖励建模
📋 核心要点
- 现有基于CLIP的奖励模型存在架构和输入模态限制,Bradley-Terry损失与VLM不匹配,阻碍了视觉生成模型有效缩放。
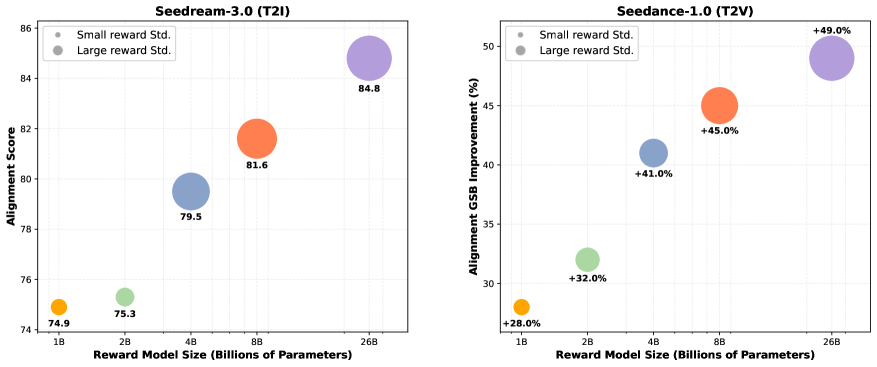
- RewardDance将奖励分数定义为模型预测“是”token的概率,从而将奖励目标与VLM架构对齐,实现模型和上下文的缩放。
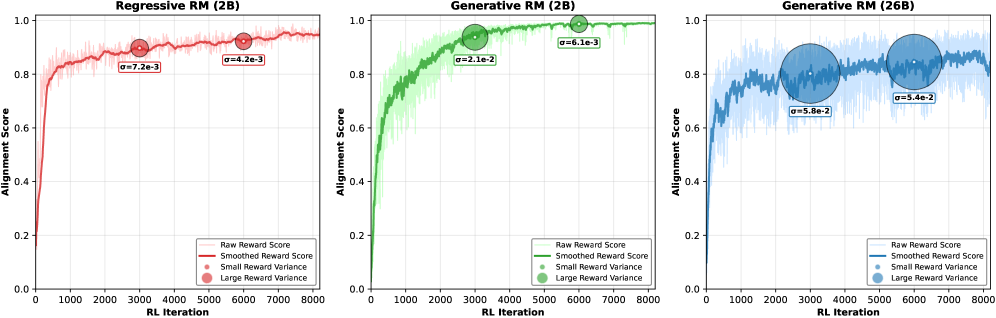
- 实验表明,RewardDance在多种视觉生成任务中超越SOTA方法,并有效缓解了奖励利用问题和模式崩溃现象。
📝 摘要(中文)
奖励模型(RM)对于通过强化学习(RL)改进生成模型至关重要,但视觉生成中的RM缩放范式仍未被充分探索。这主要是由于现有方法的根本局限性:基于CLIP的RM受到架构和输入模态的约束,而流行的Bradley-Terry损失与视觉语言模型(VLM)的下一个token预测机制存在根本上的不一致,阻碍了有效的缩放。更重要的是,RLHF优化过程受到奖励利用问题的困扰,模型利用奖励信号中的缺陷而没有提高真正的质量。为了应对这些挑战,我们引入了RewardDance,这是一个可扩展的奖励建模框架,通过一种新的生成式奖励范式克服了这些障碍。通过将奖励分数重新定义为模型预测“是”token的概率,表明生成的图像在特定标准下优于参考图像,RewardDance从本质上将奖励目标与VLM架构对齐。这种对齐解锁了两个维度的缩放:(1)模型缩放:系统地将RM扩展到260亿参数;(2)上下文缩放:集成特定于任务的指令、参考示例和思维链(CoT)推理。大量实验表明,RewardDance在文本到图像、文本到视频和图像到视频生成方面显著超越了最先进的方法。至关重要的是,我们解决了持续存在的“奖励利用”挑战:我们的大规模RM在RL微调期间表现出并保持了高奖励方差,证明了它们对利用的抵抗能力以及产生多样化、高质量输出的能力。这大大缓解了困扰较小模型的模式崩溃问题。
🔬 方法详解
问题定义:现有视觉生成模型依赖的奖励模型存在缩放性问题,具体体现在两个方面:一是CLIP等模型的架构限制,二是Bradley-Terry损失与VLM的训练方式不匹配。此外,奖励利用(Reward Hacking)问题导致模型利用奖励信号的漏洞,而非真正提升生成质量。
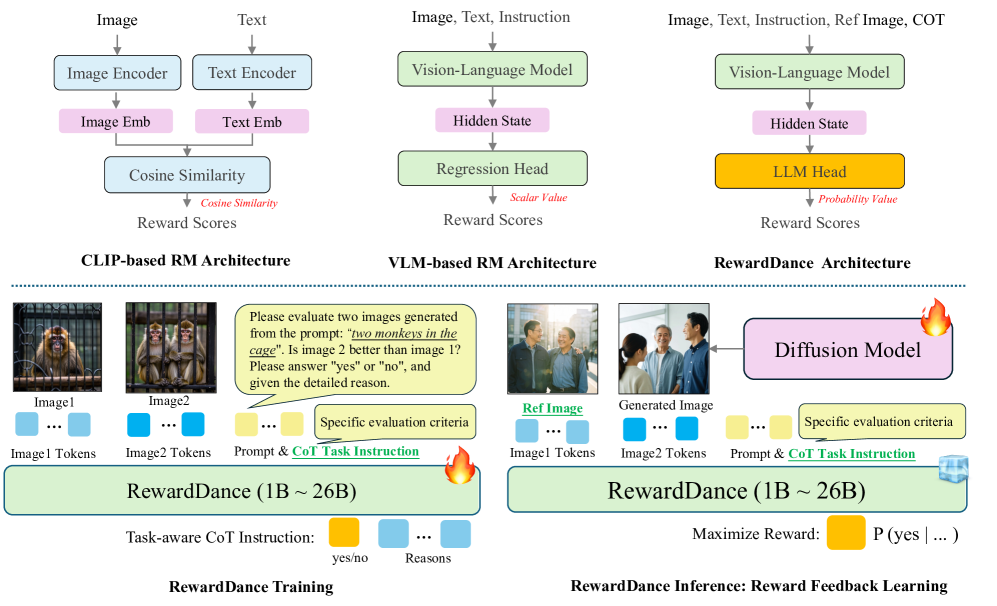
核心思路:RewardDance的核心在于将奖励建模问题转化为一个生成问题。不再直接预测奖励分数,而是训练模型预测一个“是/否”token,表示生成结果是否优于参考结果。这种方式将奖励目标与VLM的next-token预测机制对齐,从而更容易进行模型缩放和上下文信息的集成。
技术框架:RewardDance框架包含以下几个主要步骤:1)构建训练数据集,包含生成结果、参考结果以及“是/否”标签;2)训练一个VLM作为奖励模型,目标是预测给定生成结果和参考结果的情况下,模型输出“是”token的概率;3)使用训练好的奖励模型,通过强化学习微调生成模型,优化生成结果,使其获得更高的奖励。
关键创新:RewardDance最重要的创新在于其生成式奖励建模范式。与传统的奖励模型直接预测奖励分数不同,RewardDance将奖励建模转化为一个二分类问题,更符合VLM的训练方式,从而更容易进行模型缩放和上下文信息的集成。这种方法也更有效地缓解了奖励利用问题。
关键设计:RewardDance的关键设计包括:1)使用大规模VLM作为奖励模型,例如参数量高达260亿的模型;2)在训练数据中引入任务相关的指令、参考示例和思维链(CoT)推理,以提高奖励模型的准确性和泛化能力;3)使用合适的损失函数,例如交叉熵损失,来训练奖励模型,使其能够准确预测“是/否”token的概率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RewardDance在文本到图像、文本到视频和图像到视频生成任务中显著超越了SOTA方法。更重要的是,RewardDance有效解决了奖励利用问题,使得大规模奖励模型在RL微调期间能够保持高奖励方差,从而生成更多样化、更高质量的输出。这表明RewardDance具有很强的实用性和可扩展性。
🎯 应用场景
RewardDance框架可广泛应用于各种视觉生成任务,例如文本到图像生成、文本到视频生成和图像到视频生成。通过解决奖励缩放和奖励利用问题,该研究有助于提升生成模型的质量、多样性和可控性,从而在内容创作、虚拟现实、游戏开发等领域具有重要的应用价值。
📄 摘要(原文)
Reward Models (RMs) are critical for improving generation models via Reinforcement Learning (RL), yet the RM scaling paradigm in visual generation remains largely unexplored. It primarily due to fundamental limitations in existing approaches: CLIP-based RMs suffer from architectural and input modality constraints, while prevalent Bradley-Terry losses are fundamentally misaligned with the next-token prediction mechanism of Vision-Language Models (VLMs), hindering effective scaling. More critically, the RLHF optimization process is plagued by Reward Hacking issue, where models exploit flaws in the reward signal without improving true quality. To address these challenges, we introduce RewardDance, a scalable reward modeling framework that overcomes these barriers through a novel generative reward paradigm. By reformulating the reward score as the model's probability of predicting a "yes" token, indicating that the generated image outperforms a reference image according to specific criteria, RewardDance intrinsically aligns reward objectives with VLM architectures. This alignment unlocks scaling across two dimensions: (1) Model Scaling: Systematic scaling of RMs up to 26 billion parameters; (2) Context Scaling: Integration of task-specific instructions, reference examples, and chain-of-thought (CoT) reasoning. Extensive experiments demonstrate that RewardDance significantly surpasses state-of-the-art methods in text-to-image, text-to-video, and image-to-video generation. Crucially, we resolve the persistent challenge of "reward hacking": Our large-scale RMs exhibit and maintain high reward variance during RL fine-tuning, proving their resistance to hacking and ability to produce diverse, high-quality outputs. It greatly relieves the mode collapse problem that plagues smaller models.