Calibrating MLLM-as-a-judge via Multimodal Bayesian Prompt Ensembles
作者: Eric Slyman, Mehrab Tanjim, Kushal Kafle, Stefan Lee
分类: cs.CV, cs.CL
发布日期: 2025-09-10
备注: 17 pages, 8 figures, Accepted at ICCV 2025
💡 一句话要点
提出MMB方法,通过多模态贝叶斯提示集成校准MLLM在文图生成评判中的偏差。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 文图生成 提示工程 贝叶斯优化
📋 核心要点
- 现有的MLLM评判模型在评估文图生成任务时,存在偏差、过度自信以及跨领域表现不一致等问题。
- MMB方法通过图像聚类增强贝叶斯提示集成,使模型能根据图像视觉特征动态调整提示权重,从而提升评判的准确性和校准性。
- 在HPSv2和MJBench基准测试中,MMB在与人类标注对齐和校准方面均优于现有基线,验证了其有效性。
📝 摘要(中文)
多模态大型语言模型(MLLM)越来越多地被用于评估文本到图像(TTI)生成系统,基于视觉和文本上下文提供自动判断。然而,这些“评判”模型通常存在偏差、过度自信以及在不同图像领域表现不一致的问题。虽然提示集成已显示出在单模态、纯文本设置中缓解这些问题的潜力,但我们的实验表明,标准集成方法无法有效地推广到TTI任务。为了解决这些局限性,我们提出了一种新的多模态感知方法,称为多模态混合贝叶斯提示集成(MMB)。我们的方法使用贝叶斯提示集成方法,并通过图像聚类进行增强,允许评判模型根据每个样本的视觉特征动态分配提示权重。我们表明,MMB提高了成对偏好判断的准确性,并大大增强了校准效果,从而更容易衡量评判模型的真实不确定性。在HPSv2和MJBench两个TTI基准上的评估中,MMB在与人类注释对齐和跨不同图像内容的校准方面优于现有基线。我们的研究结果强调了多模态特定策略对于评判模型校准的重要性,并为可靠的大规模TTI评估提出了一个有希望的未来方向。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在作为文图生成(TTI)系统评判者时存在的偏差、过度自信和领域泛化性差的问题。现有的提示集成方法在纯文本任务中表现良好,但在TTI任务中效果不佳,无法有效利用图像信息进行校准。
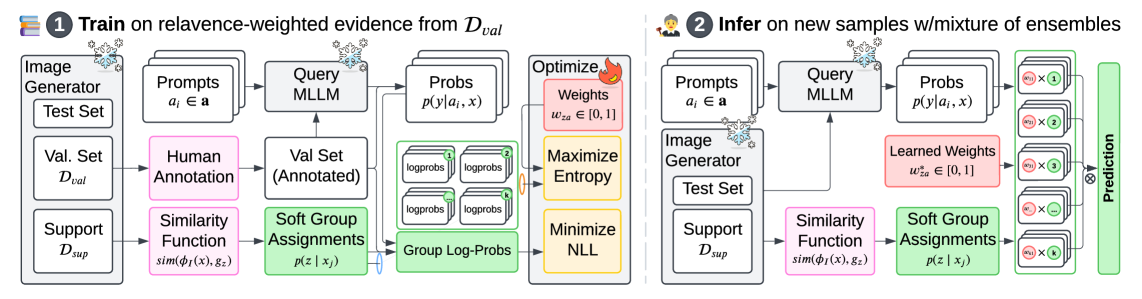
核心思路:论文的核心思路是利用图像的视觉特征来指导提示集成。通过对图像进行聚类,将相似的图像归为一类,并为每一类图像学习一组优化的提示权重。这样,评判模型可以根据输入图像的视觉特征动态调整提示权重,从而提高评判的准确性和校准性。
技术框架:MMB方法的技术框架主要包括以下几个阶段:1) 图像聚类:使用预训练的视觉模型对图像进行特征提取,然后使用聚类算法(如k-means)将图像划分为若干个簇。2) 贝叶斯提示集成:为每个图像簇构建一个贝叶斯提示集成模型,该模型包含多个不同的提示,并为每个提示分配一个权重。3) 提示权重优化:使用贝叶斯优化算法,针对每个图像簇,优化提示权重,使得评判模型在该簇上的表现最佳。4) 评判:对于新的输入图像,首先将其划分到最相似的图像簇中,然后使用该簇对应的贝叶斯提示集成模型进行评判。
关键创新:MMB方法的关键创新在于将图像聚类与贝叶斯提示集成相结合,实现了多模态信息的有效融合。与传统的提示集成方法相比,MMB方法能够根据图像的视觉特征动态调整提示权重,从而更好地适应不同的图像内容。此外,MMB方法使用贝叶斯优化算法来优化提示权重,能够更有效地探索提示空间,找到最优的提示组合。
关键设计:在图像聚类阶段,可以使用不同的视觉模型和聚类算法。在贝叶斯提示集成阶段,可以设计不同的提示模板,并使用不同的先验分布来约束提示权重。在贝叶斯优化阶段,需要选择合适的优化算法和目标函数。论文中具体使用的参数设置和网络结构等技术细节未明确给出,属于未知信息。
🖼️ 关键图片


📊 实验亮点
MMB方法在HPSv2和MJBench两个文图生成基准测试中取得了显著的性能提升。实验结果表明,MMB方法在与人类标注对齐和校准方面均优于现有基线,验证了其在多模态评判任务中的有效性。具体的性能数据和提升幅度未在摘要中明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于大规模文图生成模型的自动评估,减少人工标注成本,提高评估效率。同时,该方法也可用于提升其他多模态任务中模型的鲁棒性和可靠性,例如视觉问答、图像描述等。未来,该研究有望推动多模态人工智能系统的发展。
📄 摘要(原文)
Multimodal large language models (MLLMs) are increasingly used to evaluate text-to-image (TTI) generation systems, providing automated judgments based on visual and textual context. However, these "judge" models often suffer from biases, overconfidence, and inconsistent performance across diverse image domains. While prompt ensembling has shown promise for mitigating these issues in unimodal, text-only settings, our experiments reveal that standard ensembling methods fail to generalize effectively for TTI tasks. To address these limitations, we propose a new multimodal-aware method called Multimodal Mixture-of-Bayesian Prompt Ensembles (MMB). Our method uses a Bayesian prompt ensemble approach augmented by image clustering, allowing the judge to dynamically assign prompt weights based on the visual characteristics of each sample. We show that MMB improves accuracy in pairwise preference judgments and greatly enhances calibration, making it easier to gauge the judge's true uncertainty. In evaluations on two TTI benchmarks, HPSv2 and MJBench, MMB outperforms existing baselines in alignment with human annotations and calibration across varied image content. Our findings highlight the importance of multimodal-specific strategies for judge calibration and suggest a promising path forward for reliable large-scale TTI evaluation.