BcQLM: Efficient Vision-Language Understanding with Distilled Q-Gated Cross-Modal Fusion
作者: Sike Xiang, Shuang Chen, Amir Atapour-Abarghouei
分类: cs.CV
发布日期: 2025-09-10
🔗 代码/项目: GITHUB
💡 一句话要点
提出BcQLM:一种轻量级、高效的视觉-语言理解框架,适用于资源受限环境。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 多模态学习 轻量级模型 知识蒸馏 跨模态融合 BreezeCLIP Q-Gated
📋 核心要点
- 现有MLLM模型规模庞大,难以在资源受限的环境中部署,限制了其应用。
- 提出BcQLM框架,核心是使用轻量级的BreezeCLIP视觉-语言编码器,并结合Q-Gated跨模态融合机制。
- 实验表明,BcQLM在保持与大型MLLM相当性能的同时,显著降低了计算成本,实现了效率与准确性的平衡。
📝 摘要(中文)
随着多模态大型语言模型(MLLM)的发展,其大规模架构对资源受限环境中的部署提出了挑战。在大型模型时代,能源效率、计算可扩展性和环境可持续性至关重要,开发轻量级和高性能模型对于实际应用至关重要。因此,我们提出了一种用于端到端视觉问答的轻量级MLLM框架。我们提出的方法以BreezeCLIP为中心,这是一个紧凑而强大的视觉-语言编码器,针对高效的多模态理解进行了优化。我们的模型总共只有12亿个参数,显著降低了计算成本,同时实现了与标准尺寸MLLM相当的性能。在多个数据集上进行的实验进一步验证了其在平衡准确性和效率方面的有效性。模块化和可扩展的设计使得能够推广到更广泛的多模态任务。所提出的轻量级视觉-语言框架被称为BcQLM(BreezeCLIP增强的Q-Gated多模态语言模型)。它为在实际硬件约束下可部署的MLLM提供了一条有希望的途径。源代码可在https://github.com/thico0224/BcQLM获得。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在资源受限环境下部署困难的问题。现有MLLM模型参数量巨大,计算成本高昂,难以在边缘设备或算力不足的场景中应用。因此,需要一种轻量级且高性能的MLLM框架,以实现高效的视觉-语言理解。
核心思路:论文的核心思路是设计一个紧凑而强大的视觉-语言编码器BreezeCLIP,并结合Q-Gated跨模态融合机制,在保证模型性能的同时,显著降低参数量和计算复杂度。通过知识蒸馏等技术,将大型模型的知识迁移到小型模型,从而实现轻量化。
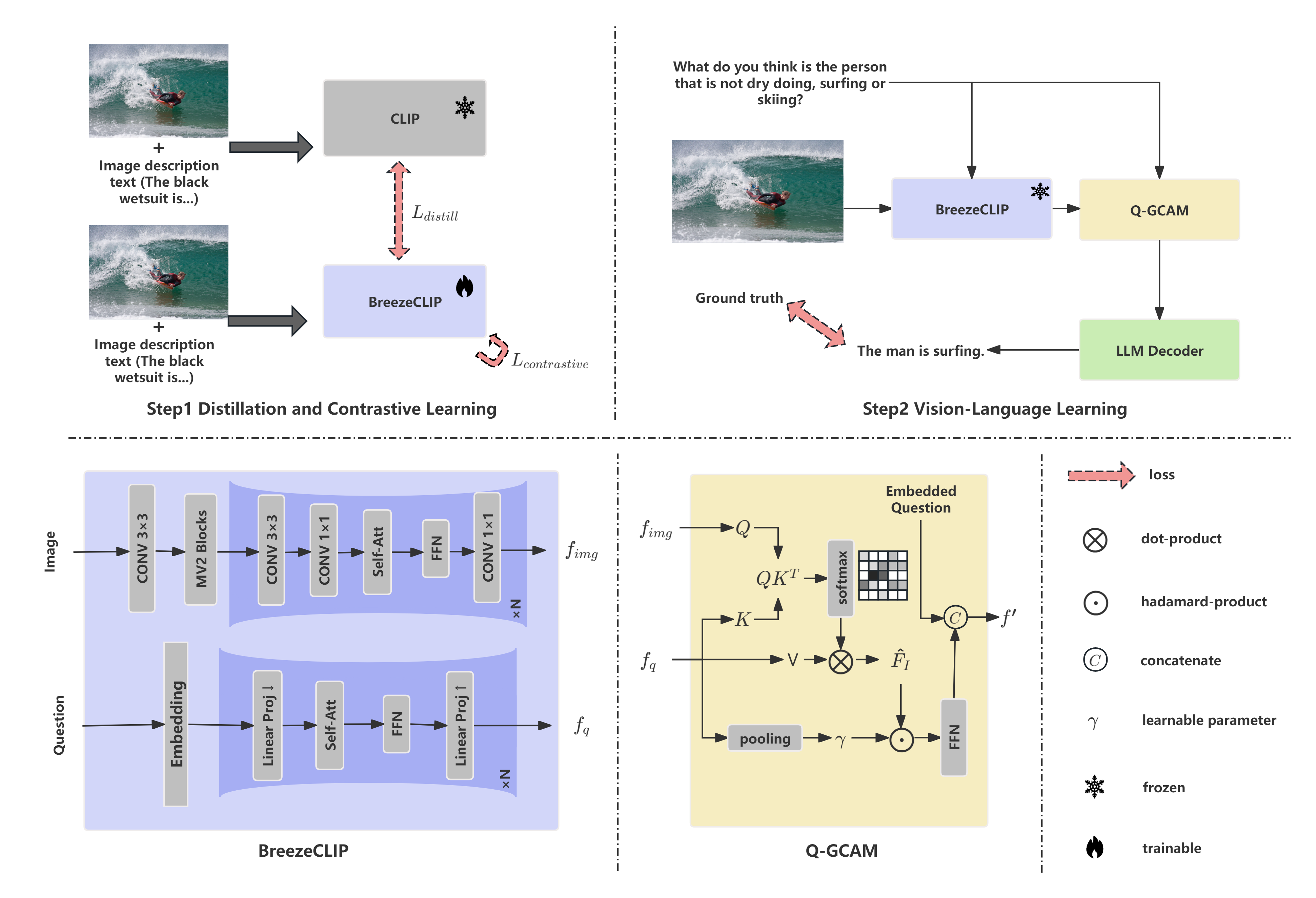
技术框架:BcQLM框架主要包含以下几个模块:1) BreezeCLIP视觉-语言编码器:用于提取图像和文本的特征表示。2) Q-Gated跨模态融合模块:用于融合视觉和语言特征,实现跨模态信息的交互。3) 语言模型:用于生成最终的答案或文本描述。整个流程是:输入图像和问题,BreezeCLIP提取视觉和语言特征,Q-Gated模块进行融合,最后由语言模型生成答案。
关键创新:论文的关键创新在于BreezeCLIP的设计和Q-Gated跨模态融合机制。BreezeCLIP通过优化网络结构和参数量,实现了轻量化和高性能的平衡。Q-Gated模块能够根据问题的相关性,动态地调整视觉和语言特征的融合权重,从而提高模型的理解能力。
关键设计:BreezeCLIP的具体网络结构未知,但强调了其轻量化设计。Q-Gated模块的具体实现细节未知,但推测可能使用了注意力机制或门控机制来控制特征融合的权重。损失函数方面,可能采用了交叉熵损失或对比学习损失来训练模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BcQLM模型在多个视觉问答数据集上取得了与标准尺寸MLLM相当的性能,同时显著降低了计算成本。该模型仅有12亿参数,在效率和准确性之间取得了良好的平衡,验证了其在资源受限环境下的有效性。
🎯 应用场景
BcQLM框架可应用于智能助手、移动设备、机器人等资源受限的场景中,实现高效的视觉问答、图像描述等任务。该研究有助于推动多模态人工智能技术在边缘计算和嵌入式系统中的应用,具有广阔的应用前景和实际价值。
📄 摘要(原文)
As multimodal large language models (MLLMs) advance, their large-scale architectures pose challenges for deployment in resource-constrained environments. In the age of large models, where energy efficiency, computational scalability and environmental sustainability are paramount, the development of lightweight and high-performance models is critical for real-world applications. As such, we propose a lightweight MLLM framework for end-to-end visual question answering. Our proposed approach centres on BreezeCLIP, a compact yet powerful vision-language encoder optimised for efficient multimodal understanding. With only 1.2 billion parameters overall, our model significantly reduces computational cost while achieving performance comparable to standard-size MLLMs. Experiments conducted on multiple datasets further validate its effectiveness in balancing accuracy and efficiency. The modular and extensible design enables generalisation to broader multimodal tasks. The proposed lightweight vision-language framework is denoted as BcQLM (BreezeCLIP-enhanced Q-Gated Multimodal Language Model). It offers a promising path toward deployable MLLMs under practical hardware constraints. The source code is available at https://github.com/thico0224/BcQLM.