EfficientIML: Efficient High-Resolution Image Manipulation Localization
作者: Jinhan Li, Haoyang He, Lei Xie, Jiangning Zhang
分类: cs.CV
发布日期: 2025-09-10
💡 一句话要点
提出EfficientIML模型,用于高效高分辨率图像篡改定位,并构建了高分辨率SIF数据集。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 图像篡改定位 高分辨率图像 扩散模型 EfficientRWKV 轻量级模型 多尺度监督 数字取证
📋 核心要点
- 现有图像篡改检测方法在高分辨率图像和扩散模型生成的新型篡改面前,面临计算资源限制和泛化性不足的挑战。
- EfficientIML模型采用轻量级EfficientRWKV骨干网络,结合状态空间和注意力机制,并行捕获全局上下文和局部细节。
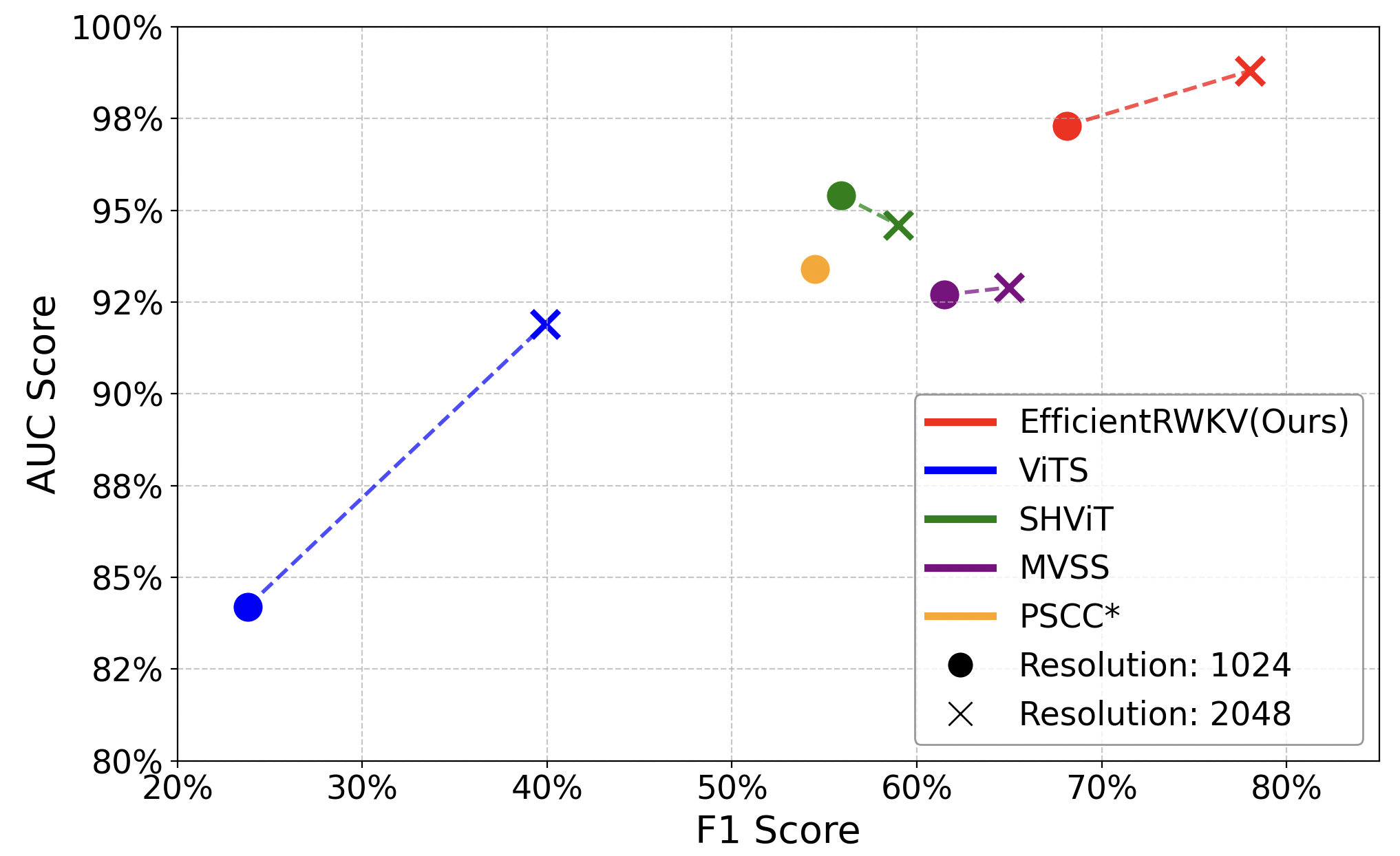
- 实验表明,EfficientIML在定位性能、计算效率和推理速度上优于现有方法,更适合实时取证应用。
📝 摘要(中文)
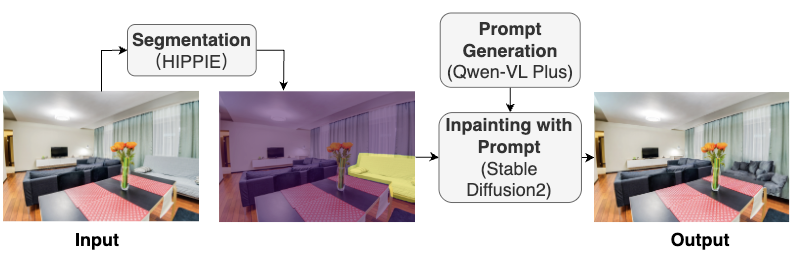
随着成像设备提供越来越高的分辨率以及新兴的基于扩散的伪造方法,当前仅在传统数据集(具有拼接、复制移动和对象移除伪造)上训练的检测器缺乏对这种新型操纵的暴露。为了解决这个问题,我们提出了一个新颖的高分辨率SIF数据集,包含1200多个扩散生成的操纵,并带有语义提取的掩码。然而,这也对现有方法提出了挑战,因为它们由于其过高的计算复杂度而面临着巨大的计算资源限制。因此,我们提出了一种新的EfficientIML模型,该模型具有轻量级的三阶段EfficientRWKV骨干网络。EfficientRWKV的混合状态空间和注意力网络并行捕获全局上下文和局部细节,而多尺度监督策略则强制执行跨层级预测的一致性。在我们数据集和标准基准上的广泛评估表明,我们的方法在定位性能、FLOPs和推理速度方面优于基于ViT的和其它SOTA轻量级基线,突显了其适用于实时取证应用。
🔬 方法详解
问题定义:现有图像篡改定位方法难以处理高分辨率图像,并且缺乏对扩散模型生成的新型篡改的适应性。传统方法计算复杂度高,难以满足实时性需求,并且在新的篡改类型上泛化能力较差。
核心思路:论文的核心思路是设计一个轻量级且高效的模型,能够同时捕获全局上下文和局部细节,并利用多尺度监督来提升定位精度。通过引入EfficientRWKV骨干网络,降低计算复杂度,并使其能够更好地适应高分辨率图像和新型篡改。
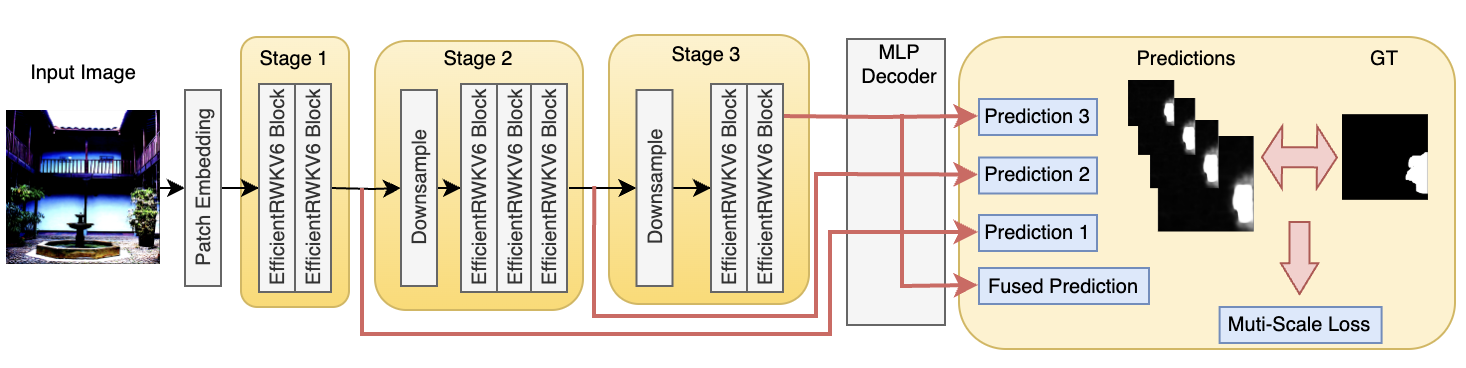
技术框架:EfficientIML模型采用三阶段架构,主要包括:1) EfficientRWKV骨干网络:用于提取图像特征,并行处理全局上下文和局部细节。2) 多尺度特征融合:将不同尺度的特征进行融合,以获得更全面的信息。3) 篡改定位模块:基于融合后的特征,预测篡改区域的掩码。
关键创新:EfficientRWKV骨干网络是关键创新点,它结合了状态空间模型和注意力机制的优点,在保证性能的同时显著降低了计算复杂度。此外,多尺度监督策略也提升了模型的定位精度。与现有方法相比,EfficientIML在计算效率和定位性能上都取得了显著提升。
关键设计:EfficientRWKV的具体结构未知,但强调了状态空间模型和注意力机制的并行使用。多尺度监督策略可能涉及在不同尺度的特征图上计算损失,并进行加权求和。损失函数的设计可能包括二元交叉熵损失或Dice损失,用于优化篡改区域的预测。
🖼️ 关键图片
📊 实验亮点
EfficientIML模型在作者提出的高分辨率SIF数据集和标准基准上进行了评估,结果表明其在定位性能、FLOPs和推理速度方面均优于基于ViT的和其它SOTA轻量级基线。具体性能数据未知,但强调了在计算效率和定位精度上的显著提升,使其更适用于实时取证应用。
🎯 应用场景
该研究成果可应用于数字取证、图像安全、新闻真实性验证等领域。通过快速准确地定位图像篡改区域,可以帮助识别虚假信息,维护网络安全,并为司法鉴定提供技术支持。未来,该技术有望集成到实时监控系统和图像编辑软件中,实现自动化篡改检测。
📄 摘要(原文)
With imaging devices delivering ever-higher resolutions and the emerging diffusion-based forgery methods, current detectors trained only on traditional datasets (with splicing, copy-moving and object removal forgeries) lack exposure to this new manipulation type. To address this, we propose a novel high-resolution SIF dataset of 1200+ diffusion-generated manipulations with semantically extracted masks. However, this also imposes a challenge on existing methods, as they face significant computational resource constraints due to their prohibitive computational complexities. Therefore, we propose a novel EfficientIML model with a lightweight, three-stage EfficientRWKV backbone. EfficientRWKV's hybrid state-space and attention network captures global context and local details in parallel, while a multi-scale supervision strategy enforces consistency across hierarchical predictions. Extensive evaluations on our dataset and standard benchmarks demonstrate that our approach outperforms ViT-based and other SOTA lightweight baselines in localization performance, FLOPs and inference speed, underscoring its suitability for real-time forensic applications.