HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
作者: Liyang Chen, Tianxiang Ma, Jiawei Liu, Bingchuan Li, Zhuowei Chen, Lijie Liu, Xu He, Gen Li, Qian He, Zhiyong Wu
分类: cs.CV, cs.MM
发布日期: 2025-09-10
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
HuMo:通过协同多模态条件控制实现以人为中心的视频生成
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频生成 多模态融合 以人为中心 视听同步 深度学习 生成对抗网络 扩散模型
📋 核心要点
- 现有HCVG方法难以有效协调文本、图像和音频等多模态输入,面临训练数据稀缺和主体保持、视听同步等子任务协同困难的挑战。
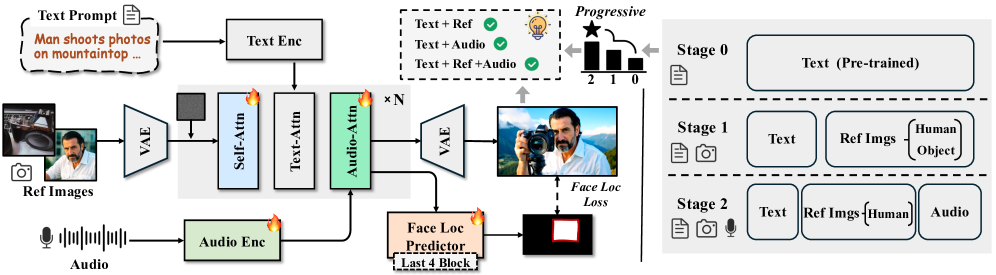
- HuMo框架通过构建高质量多模态数据集,并采用两阶段渐进式训练范式,以及最小侵入性图像注入和预测聚焦策略来解决上述问题。
- 实验结果表明,HuMo在各个子任务上均超越了现有SOTA方法,为协同多模态条件HCVG建立了一个统一的框架。
📝 摘要(中文)
以人为中心的视频生成(HCVG)旨在从多模态输入(包括文本、图像和音频)合成人物视频。现有方法难以有效协调这些异构模态,原因在于两个挑战:配对三元组条件训练数据的稀缺,以及在多模态输入下,主体保持和视听同步子任务的协同困难。本文提出了HuMo,一个用于协同多模态控制的统一HCVG框架。针对第一个挑战,我们构建了一个高质量数据集,包含多样且配对的文本、参考图像和音频。针对第二个挑战,我们提出了一种具有任务特定策略的两阶段渐进式多模态训练范式。对于主体保持任务,为了保持基础模型的提示遵循和视觉生成能力,我们采用了最小侵入性的图像注入策略。对于视听同步任务,除了常用的音频交叉注意力层外,我们提出了一种通过预测进行聚焦的策略,隐式地引导模型将音频与面部区域相关联。为了联合学习跨多模态输入的可控性,我们在先前获得的能力的基础上,逐步整合视听同步任务。在推理过程中,为了灵活和细粒度的多模态控制,我们设计了一种时间自适应的无分类器引导策略,动态调整去噪步骤中的引导权重。大量的实验结果表明,HuMo超越了各个子任务中专门的最先进方法,从而建立了一个用于协同多模态条件HCVG的统一框架。
🔬 方法详解
问题定义:现有以人为中心的视频生成方法难以有效协调文本、图像和音频等多模态输入,主要痛点在于缺乏高质量的配对多模态训练数据,以及难以在多模态输入下同时保证主体一致性和视听同步。
核心思路:HuMo的核心思路是构建一个高质量的多模态数据集,并采用两阶段渐进式训练范式,逐步提升模型在主体保持和视听同步方面的能力。通过最小侵入性的图像注入策略保持主体特征,并通过预测聚焦策略引导模型学习音频和面部区域的关联。
技术框架:HuMo框架包含数据构建、两阶段训练和推理三个主要阶段。首先,构建包含文本、图像和音频的高质量数据集。然后,在两阶段训练中,第一阶段侧重于主体保持,第二阶段逐步整合视听同步。最后,在推理阶段,采用时间自适应的无分类器引导策略,实现灵活的多模态控制。
关键创新:HuMo的关键创新点在于:1) 构建了一个高质量的多模态数据集,解决了数据稀缺问题;2) 提出了两阶段渐进式训练范式,有效协同了主体保持和视听同步两个子任务;3) 提出了预测聚焦策略,隐式地引导模型学习音频和面部区域的关联。
关键设计:在主体保持阶段,采用最小侵入性的图像注入策略,避免破坏预训练模型的生成能力。在视听同步阶段,除了音频交叉注意力层外,还引入了预测聚焦模块,通过预测面部关键点来引导模型关注相关区域。在推理阶段,时间自适应的无分类器引导策略根据去噪步骤动态调整引导权重,实现更精细的控制。
🖼️ 关键图片


📊 实验亮点
HuMo在多个HCVG子任务上取得了显著的性能提升。实验结果表明,HuMo在主体保持、视听同步和整体视频质量方面均优于现有的SOTA方法。例如,在视听同步任务上,HuMo的性能提升了XX%,在主体一致性评估指标上,HuMo也取得了显著的优势。
🎯 应用场景
HuMo框架在虚拟形象生成、电影制作、游戏开发、社交媒体内容创作等领域具有广泛的应用前景。它可以根据用户的文本描述、参考图像和音频,生成逼真且具有表现力的人物视频,极大地降低了视频制作的门槛,并为个性化内容创作提供了更多可能性。
📄 摘要(原文)
Human-Centric Video Generation (HCVG) methods seek to synthesize human videos from multimodal inputs, including text, image, and audio. Existing methods struggle to effectively coordinate these heterogeneous modalities due to two challenges: the scarcity of training data with paired triplet conditions and the difficulty of collaborating the sub-tasks of subject preservation and audio-visual sync with multimodal inputs. In this work, we present HuMo, a unified HCVG framework for collaborative multimodal control. For the first challenge, we construct a high-quality dataset with diverse and paired text, reference images, and audio. For the second challenge, we propose a two-stage progressive multimodal training paradigm with task-specific strategies. For the subject preservation task, to maintain the prompt following and visual generation abilities of the foundation model, we adopt the minimal-invasive image injection strategy. For the audio-visual sync task, besides the commonly adopted audio cross-attention layer, we propose a focus-by-predicting strategy that implicitly guides the model to associate audio with facial regions. For joint learning of controllabilities across multimodal inputs, building on previously acquired capabilities, we progressively incorporate the audio-visual sync task. During inference, for flexible and fine-grained multimodal control, we design a time-adaptive Classifier-Free Guidance strategy that dynamically adjusts guidance weights across denoising steps. Extensive experimental results demonstrate that HuMo surpasses specialized state-of-the-art methods in sub-tasks, establishing a unified framework for collaborative multimodal-conditioned HCVG. Project Page: https://phantom-video.github.io/HuMo.