GLEAM: Learning to Match and Explain in Cross-View Geo-Localization
作者: Xudong Lu, Zhi Zheng, Yi Wan, Yongxiang Yao, Annan Wang, Renrui Zhang, Panwang Xia, Qiong Wu, Qingyun Li, Weifeng Lin, Xiangyu Zhao, Peifeng Ma, Xue Yang, Hongsheng Li
分类: cs.CV, cs.CL
发布日期: 2025-09-09 (更新: 2026-01-31)
备注: 23 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出GLEAM,通过多模态对齐与可解释推理,提升跨视角地理定位性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨视角地理定位 多模态学习 可解释推理 多模态大语言模型 图像匹配
📋 核心要点
- 现有跨视角地理定位方法局限于单一视角或模态,缺乏解释性,无法解释图像匹配的原因。
- 提出GLEAM框架,通过将多视角、多模态数据与卫星图像对齐,并结合多模态大语言模型进行可解释推理。
- GLEAM在跨视角地理定位任务上取得了与现有方法相当的精度,并提供了可解释的匹配依据。
📝 摘要(中文)
跨视角地理定位(CVGL)旨在识别同一地理位置不同视角图像之间的对应关系。现有方法通常局限于单一视角或模态,且缺乏可解释性,仅判断图像是否对应,而无法解释匹配的原因。本文提出GLEAM-C,一个基础CVGL模型,通过将多视角和多模态数据与卫星图像对齐,统一了不同视角和模态。通过优化实现提升训练效率,并通过新颖的两阶段训练策略,实现了与现有模态特定CVGL模型相当的精度。为了解决可解释性问题,进一步提出了GLEAM-X,结合跨视角对应关系预测和多模态大语言模型(MLLM)支持的可解释推理。构建了一个双语基准,使用商业MLLM生成训练和测试数据,并通过严格的人工修订完善测试集,以系统评估可解释的跨视角推理。GLEAM-C和GLEAM-X共同构成了一个全面的CVGL流程,集成了多模态、多视角对齐与可解释的对应关系分析,统一了准确的跨视角匹配与可解释的推理,并通过使模型更好地解释和匹配来推进地理定位。
🔬 方法详解
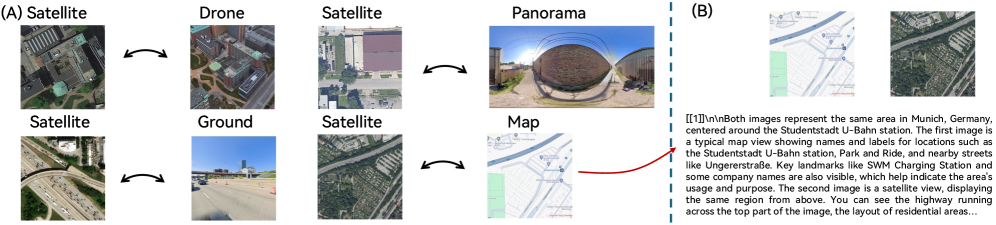
问题定义:跨视角地理定位(CVGL)旨在找到不同视角(例如街景和卫星图像)下,对应于同一地理位置的图像。现有方法的痛点在于:1) 往往针对特定视角或模态设计,通用性不足;2) 缺乏可解释性,只能判断两张图像是否匹配,无法给出匹配的原因。
核心思路:GLEAM的核心思路是将多视角、多模态的数据统一对齐到卫星图像上,构建一个通用的CVGL框架。同时,利用多模态大语言模型(MLLM)进行可解释推理,为匹配结果提供解释,增强模型的可信度。
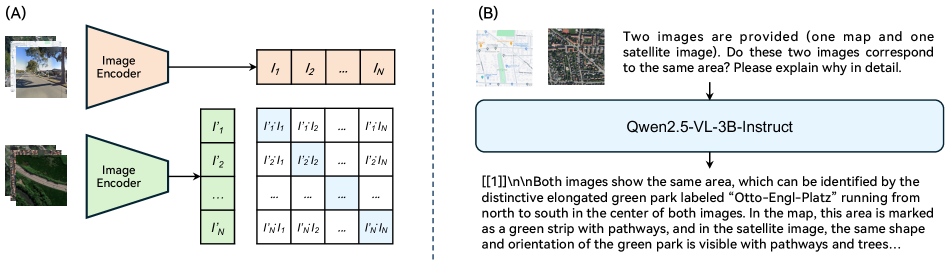
技术框架:GLEAM框架包含两个主要部分:GLEAM-C和GLEAM-X。GLEAM-C负责跨视角图像的匹配,通过将不同视角的图像与卫星图像对齐来实现。GLEAM-X则负责可解释推理,利用MLLM生成匹配的解释,并进行评估。整体流程是先用GLEAM-C进行匹配,然后用GLEAM-X生成解释。
关键创新:GLEAM的关键创新在于:1) 统一了多视角、多模态的CVGL问题,提出了一个通用的框架;2) 引入了可解释推理,利用MLLM为匹配结果提供解释,增强了模型的可信度;3) 构建了一个双语基准,用于评估可解释的跨视角推理。
关键设计:GLEAM-C采用了两阶段训练策略,首先进行预训练,然后进行微调。GLEAM-X使用了商业MLLM生成训练和测试数据,并通过人工修订完善测试集。损失函数方面,可能使用了对比损失或三元组损失来学习图像之间的相似性。具体的网络结构细节在论文中应该有更详细的描述。
🖼️ 关键图片

📊 实验亮点
GLEAM-C在跨视角地理定位任务上取得了与现有模态特定模型相当的精度,同时具有更好的通用性。GLEAM-X通过引入可解释推理,为匹配结果提供了有意义的解释,增强了模型的可信度。论文构建的双语基准为评估可解释的跨视角推理提供了新的工具。
🎯 应用场景
GLEAM在自动驾驶、城市规划、灾害救援等领域具有广泛的应用前景。例如,可以利用GLEAM进行车辆定位、建筑物识别、灾情评估等。通过提供可解释的匹配结果,GLEAM可以增强用户对系统的信任,提高决策效率。未来,GLEAM可以进一步扩展到更多模态的数据,例如LiDAR、SAR等,以实现更精确、更可靠的地理定位。
📄 摘要(原文)
Cross-View Geo-Localization (CVGL) focuses on identifying correspondences between images captured from distinct perspectives of the same geographical location. However, existing CVGL approaches are typically restricted to a single view or modality, and their direct visual matching strategy lacks interpretability: they only determine whether two images correspond, without explaining the rationale behind the match. In this paper, we present GLEAM-C, a foundational CVGL model that unifies multiple views and modalities by aligning them exclusively with satellite imagery. Our framework improves training efficiency through optimized implementation and achieves accuracy comparable to prior modality-specific CVGL models via a novel two-phase training strategy. To address interpretability, we further propose GLEAM-X, a novel task that combines cross-view correspondence prediction with explainable reasoning enabled by multimodal large language models (MLLMs). We construct a bilingual benchmark using commercial MLLMs to generate training and testing data, and refine the test set through rigorous human revision for systematic evaluation of explainable cross-view reasoning. Together, GLEAM-C and GLEAM-X form a comprehensive CVGL pipeline that integrates multi-modal, multi-view alignment with interpretable correspondence analysis, unifying accurate cross-view matching with explainable reasoning and advancing Geo-Localization by enabling models to better Explain And Match. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/GLEAM.