Spatial Reasoning with Vision-Language Models in Ego-Centric Multi-View Scenes
作者: Mohsen Gholami, Ahmad Rezaei, Zhou Weimin, Sitong Mao, Shunbo Zhou, Yong Zhang, Mohammad Akbari
分类: cs.CV
发布日期: 2025-09-08 (更新: 2025-09-30)
💡 一句话要点
提出Ego3D-Bench与Ego3D-VLM,提升VLM在第一视角多视图场景下的空间推理能力。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 空间推理 第一视角 多视图 认知地图
📋 核心要点
- 现有VLM在3D空间关系理解方面存在不足,尤其是在第一视角多视图场景下,缺乏高质量的评测基准。
- 提出Ego3D-VLM,通过构建认知地图增强VLM的3D空间推理能力,该方法可与现有VLM模型结合。
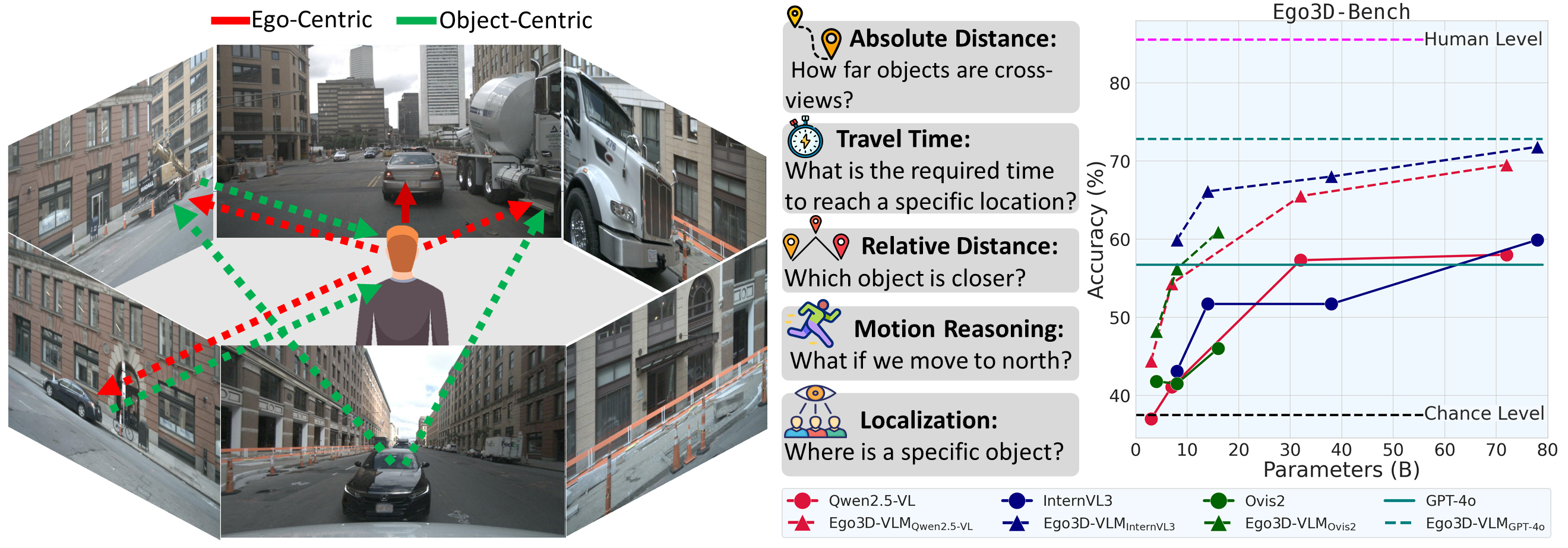
- 实验结果表明,Ego3D-VLM在多项选择QA和绝对距离估计任务上分别取得了12%和56%的显著提升。
📝 摘要(中文)
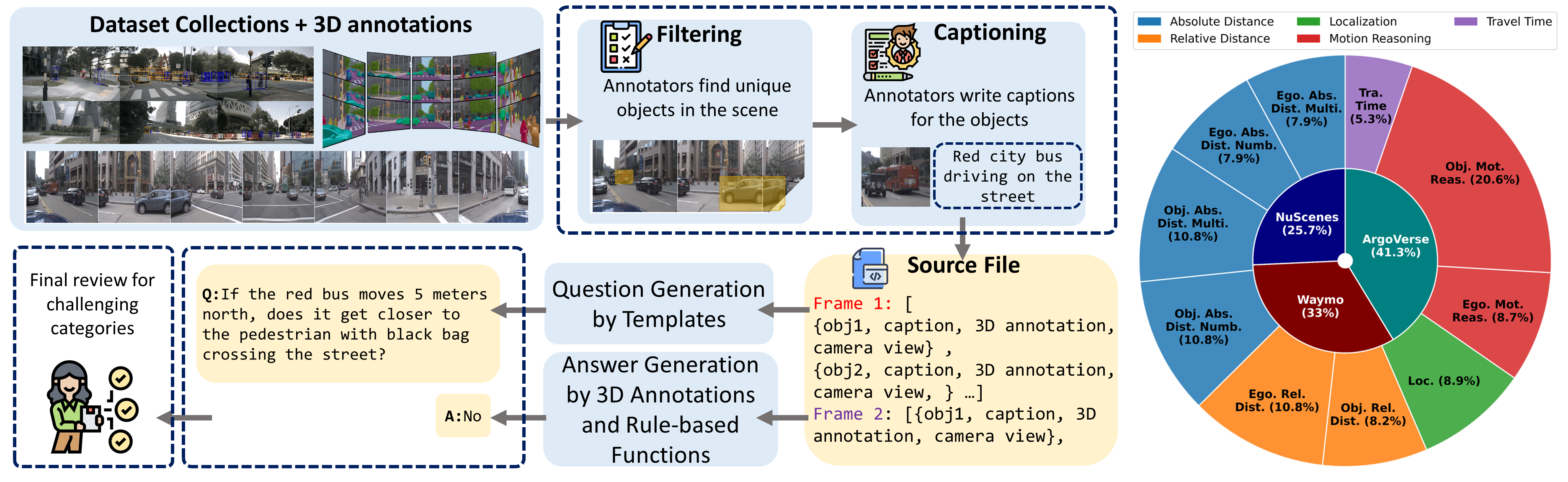
当前视觉-语言模型(VLM)在理解3D空间关系方面存在局限性。现有工作主要基于单张图像或室内视频构建空间问答(QA)数据集。然而,现实世界中的具身智能体,如机器人和自动驾驶汽车,通常依赖于第一视角、多视图的观测数据。为此,我们提出了Ego3D-Bench,一个新的基准,旨在评估VLM在第一视角、多视图户外数据上的空间推理能力。Ego3D-Bench包含超过8600个QA对,由人工标注员参与创建,以确保质量和多样性。我们对包括GPT-4o、Gemini1.5-Pro、InternVL3和Qwen2.5-VL在内的16个SOTA VLM进行了基准测试。结果表明,VLM的性能与人类水平之间存在显著差距,表明当前的VLM在空间理解方面仍有不足。为了弥合这一差距,我们提出了Ego3D-VLM,一个后训练框架,用于增强VLM的3D空间推理能力。Ego3D-VLM基于估计的全局3D坐标生成认知地图,在多项选择QA上平均提升12%,在绝对距离估计上平均提升56%。Ego3D-VLM是模块化的,可以与任何现有的VLM集成。Ego3D-Bench和Ego3D-VLM共同为在真实世界、多视图环境中实现人类水平的空间理解提供了有价值的工具。
🔬 方法详解
问题定义:现有视觉-语言模型在理解3D空间关系方面存在局限性,尤其是在第一视角、多视图的户外场景中。现有的空间问答数据集主要集中在单张图像或室内视频,无法有效评估VLM在真实世界具身智能体应用中的空间推理能力。因此,需要一个专门针对第一视角多视图场景的评测基准,并设计有效的方法来提升VLM在此类场景下的空间理解能力。
核心思路:论文的核心思路是利用多视图信息构建认知地图,从而增强VLM的3D空间推理能力。通过估计场景中物体的全局3D坐标,并将这些坐标信息融入到VLM的输入中,使得VLM能够更好地理解物体之间的空间关系。这种方法模拟了人类在探索环境时构建心理地图的过程,有助于提高VLM的空间推理能力。
技术框架:Ego3D-VLM框架主要包含以下几个模块:1) 多视图图像特征提取模块,用于提取每张图像的视觉特征;2) 3D坐标估计模块,用于估计场景中物体的全局3D坐标;3) 认知地图构建模块,用于将3D坐标信息整合到认知地图中;4) VLM推理模块,用于根据认知地图和问题进行推理,并生成答案。整个流程是先利用多视图图像估计3D坐标,构建认知地图,然后将认知地图作为VLM的输入,进行空间问答。
关键创新:论文的关键创新在于提出了Ego3D-VLM,一个基于认知地图的后训练框架,用于增强VLM的3D空间推理能力。与现有方法相比,Ego3D-VLM能够有效地利用多视图信息,构建场景的全局3D表示,从而提高VLM的空间理解能力。此外,Ego3D-VLM是模块化的,可以与任何现有的VLM集成,具有良好的通用性。
关键设计:在3D坐标估计模块中,可以使用现有的3D重建算法或深度估计模型。认知地图的构建方式可以采用不同的策略,例如,可以将3D坐标信息编码成图像或文本的形式,然后将其与原始图像或文本输入拼接在一起。在VLM推理模块中,可以使用现有的VLM模型,并根据具体任务进行微调。损失函数的设计可以根据具体任务进行调整,例如,可以使用交叉熵损失函数进行多项选择QA,使用L1损失函数进行绝对距离估计。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Ego3D-VLM在Ego3D-Bench基准测试上取得了显著的性能提升。在多项选择QA任务上,Ego3D-VLM平均提升了12%,在绝对距离估计任务上,Ego3D-VLM平均提升了56%。这些结果表明,Ego3D-VLM能够有效地增强VLM的3D空间推理能力,使其更接近人类水平。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、增强现实等领域。通过提升VLM在第一视角多视图场景下的空间推理能力,可以使机器人和自动驾驶汽车更好地理解周围环境,从而实现更安全、更智能的导航和决策。此外,该技术还可以应用于增强现实应用中,例如,可以根据用户的视角和位置,提供更准确、更自然的虚拟物体交互。
📄 摘要(原文)
Understanding 3D spatial relationships remains a major limitation of current Vision-Language Models (VLMs). Prior work has addressed this issue by creating spatial question-answering (QA) datasets based on single images or indoor videos. However, real-world embodied AI agents such as robots and self-driving cars typically rely on ego-centric, multi-view observations. To this end, we introduce Ego3D-Bench, a new benchmark designed to evaluate the spatial reasoning abilities of VLMs using ego-centric, multi-view outdoor data. Ego3D-Bench comprises over 8,600 QA pairs, created with significant involvement from human annotators to ensure quality and diversity. We benchmark 16 SOTA VLMs, including GPT-4o, Gemini1.5-Pro, InternVL3, and Qwen2.5-VL. Our results reveal a notable performance gap between human level scores and VLM performance, highlighting that current VLMs still fall short of human level spatial understanding. To bridge this gap, we propose Ego3D-VLM, a post-training framework that enhances 3D spatial reasoning of VLMs. Ego3D-VLM generates cognitive map based on estimated global 3D coordinates, resulting in 12% average improvement on multi-choice QA and 56% average improvement on absolute distance estimation. Ego3D-VLM is modular and can be integrated with any existing VLM. Together, Ego3D-Bench and Ego3D-VLM offer valuable tools for advancing toward human level spatial understanding in real-world, multi-view environments.