Motion Aware ViT-based Framework for Monocular 6-DoF Spacecraft Pose Estimation
作者: Jose Sosa, Dan Pineau, Arunkumar Rathinam, Abdelrahman Shabayek, Djamila Aouada
分类: cs.CV
发布日期: 2025-09-07
💡 一句话要点
提出一种基于运动感知的ViT框架,用于单目6自由度航天器姿态估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 航天器姿态估计 单目视觉 Vision Transformer 光流估计 运动感知 深度学习 6自由度姿态估计
📋 核心要点
- 现有航天器姿态估计方法依赖单帧图像,忽略了时序信息,限制了在动态环境下的性能。
- 该论文提出一种基于ViT的运动感知框架,利用光流信息增强特征提取,提升关键点定位精度。
- 实验表明,该方法在SPADES-RGB数据集上优于单帧基线,并在SPARK-2024数据集上展现出良好的泛化能力。
📝 摘要(中文)
单目6自由度姿态估计在多种航天器任务中扮演重要角色。现有姿态估计方法主要依赖于静态关键点定位的单张图像,未能利用航天操作中固有的宝贵时序信息。本文将一种源于人体姿态估计的深度学习框架适配到航天器姿态估计领域,该框架集成了运动感知热图和光流以捕获运动动态。我们的方法结合了Vision Transformer (ViT)编码器的图像特征和预训练光流模型的运动线索,以定位2D关键点。利用这些估计值,透视n点(PnP)求解器从已知的2D-3D对应关系中恢复6自由度姿态。我们在SPADES-RGB数据集上训练和评估了我们的方法,并在SPARK-2024数据集的真实和合成数据上进一步评估了其泛化能力。总体而言,我们的方法在2D关键点定位和6自由度姿态估计方面都表现出优于单图像基线的性能。此外,在不同数据分布上进行测试时,它显示出有希望的泛化能力。
🔬 方法详解
问题定义:论文旨在解决单目视觉下航天器6自由度姿态估计问题。现有方法主要依赖单张图像的静态关键点定位,忽略了连续帧之间的运动信息,导致在复杂或快速运动场景下精度下降。
核心思路:核心思路是将时序运动信息融入到特征提取过程中,利用光流估计来捕捉帧间运动,并将其与ViT提取的图像特征相结合,从而更准确地定位关键点。这种方法旨在克服静态图像方法的局限性,提高在动态环境下的姿态估计精度。
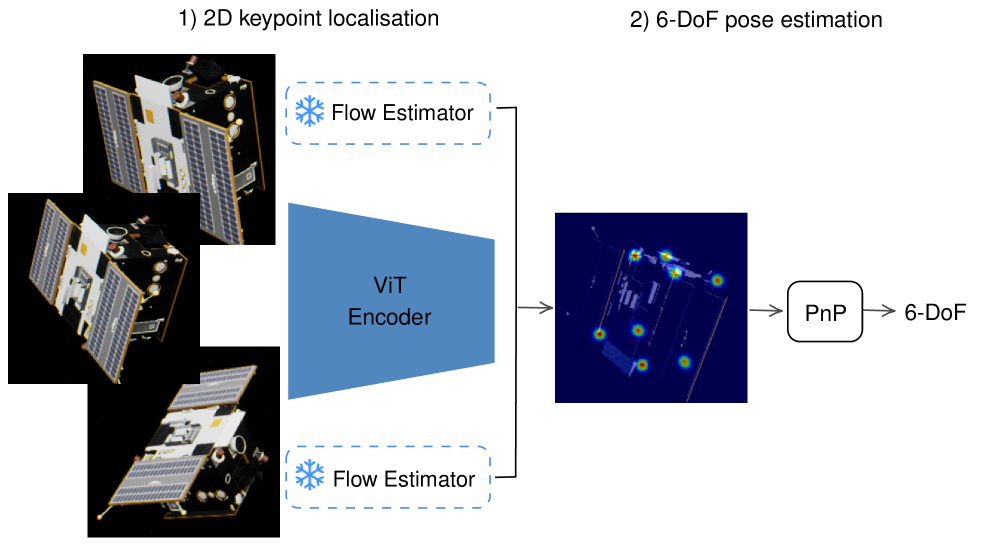
技术框架:整体框架包括以下几个主要模块:1) ViT编码器:用于提取图像的视觉特征。2) 预训练光流模型:用于估计连续帧之间的光流信息,提供运动线索。3) 运动感知热图:将光流信息融入到关键点定位的热图中。4) PnP求解器:利用2D关键点和3D模型之间的对应关系,恢复6自由度姿态。流程是首先利用ViT提取图像特征,然后利用光流模型估计运动信息,将两者融合后预测关键点位置,最后使用PnP算法求解姿态。
关键创新:最关键的创新在于将运动信息显式地融入到深度学习框架中,通过结合光流和ViT特征,实现了运动感知的关键点定位。与传统的单图像方法相比,该方法能够更好地利用时序信息,提高在动态场景下的鲁棒性和精度。
关键设计:论文使用了预训练的光流模型来提取运动信息,避免了从头训练光流模型的复杂性。ViT的选择是因为其在图像特征提取方面的强大能力。损失函数的设计可能包括关键点定位的损失和姿态估计的损失。具体的网络结构和参数设置需要在论文中查找。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在SPADES-RGB数据集上优于单图像基线方法,在2D关键点定位和6自由度姿态估计方面均有提升。此外,在SPARK-2024数据集上的测试表明,该方法具有良好的泛化能力,能够适应不同的数据分布和场景。
🎯 应用场景
该研究成果可应用于航天器自主导航、空间操作、在轨服务等领域。通过提高姿态估计的精度和鲁棒性,可以提升航天器在复杂环境下的自主能力,降低对地面控制的依赖,并为未来的空间探索任务提供更可靠的技术支持。
📄 摘要(原文)
Monocular 6-DoF pose estimation plays an important role in multiple spacecraft missions. Most existing pose estimation approaches rely on single images with static keypoint localisation, failing to exploit valuable temporal information inherent to space operations. In this work, we adapt a deep learning framework from human pose estimation to the spacecraft pose estimation domain that integrates motion-aware heatmaps and optical flow to capture motion dynamics. Our approach combines image features from a Vision Transformer (ViT) encoder with motion cues from a pre-trained optical flow model to localise 2D keypoints. Using the estimates, a Perspective-n-Point (PnP) solver recovers 6-DoF poses from known 2D-3D correspondences. We train and evaluate our method on the SPADES-RGB dataset and further assess its generalisation on real and synthetic data from the SPARK-2024 dataset. Overall, our approach demonstrates improved performance over single-image baselines in both 2D keypoint localisation and 6-DoF pose estimation. Furthermore, it shows promising generalisation capabilities when testing on different data distributions.