S-LAM3D: Segmentation-Guided Monocular 3D Object Detection via Feature Space Fusion
作者: Diana-Alexandra Sas, Florin Oniga
分类: cs.CV, cs.AI
发布日期: 2025-09-07
备注: 6 pages. Accepted to MMSP 2025
💡 一句话要点
S-LAM3D:通过特征空间融合的分割引导单目3D目标检测
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目3D目标检测 特征空间融合 分割引导 深度估计 KITTI数据集
📋 核心要点
- 单目3D目标检测缺乏深度信息,深度估计困难,现有方法依赖复杂的网络结构。
- 该论文提出将预计算的分割信息融入特征空间,引导检测,无需额外学习或扩展模型。
- 实验表明,该方法在小物体检测上优于仅使用RGB图像特征的方法,提升了检测性能。
📝 摘要(中文)
单目3D目标检测是一项具有挑战性的计算机视觉任务,因为其输入仅为单个2D图像,缺乏深度信息,导致深度估计成为一个病态问题。现有的解决方案通常利用卷积神经网络或Transformer架构作为特征提取骨干网络,然后使用特定的检测头来预测3D参数。本文提出了一种解耦策略,通过注入预先计算的分割信息先验,并将其直接融合到特征空间中来引导检测,而无需扩展检测模型或联合学习先验。重点在于评估额外的分割信息对现有检测流程的影响,而无需添加额外的预测分支。该方法在KITTI 3D目标检测基准上进行了评估,在场景中的小物体(行人和自行车)的检测方面优于仅依赖RGB图像特征的等效架构,证明了理解输入数据可以平衡对额外传感器或训练数据的需求。
🔬 方法详解
问题定义:单目3D目标检测任务中,仅使用2D图像作为输入,缺乏深度信息,导致深度估计不准确,严重影响3D目标检测的性能。现有方法通常依赖于复杂的卷积神经网络或Transformer架构来学习深度信息,但计算成本高昂,且对小目标的检测效果不佳。
核心思路:该论文的核心思路是将预先计算的分割信息作为先验知识,直接注入到特征空间中,从而引导3D目标检测。通过分割信息,模型可以更好地理解场景中的物体结构和位置关系,从而提高深度估计的准确性,尤其是在小目标检测方面。这种方法避免了联合学习分割信息和3D目标检测,降低了计算复杂度。
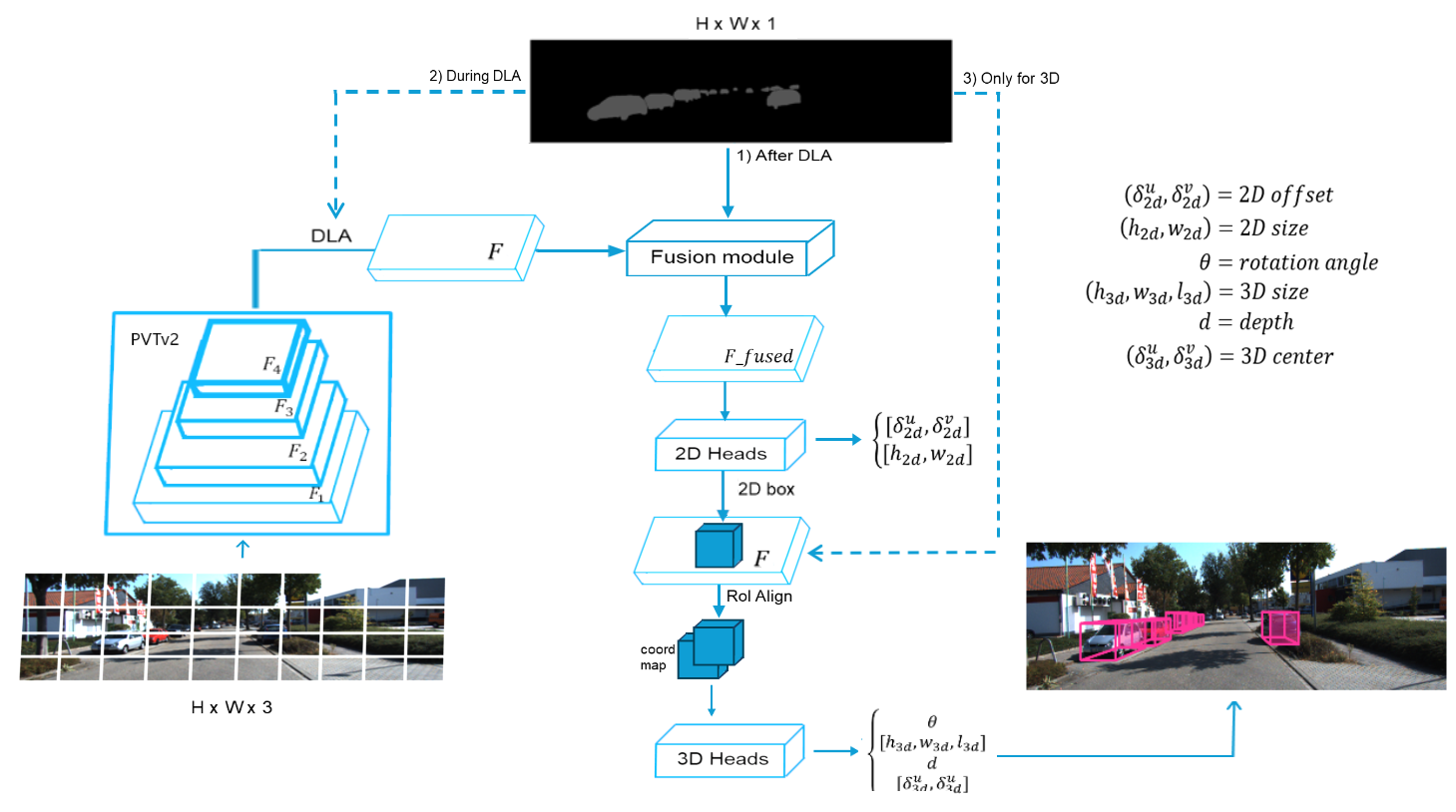
技术框架:S-LAM3D的整体框架包括以下几个主要步骤:1) 使用现有的分割模型(例如Mask R-CNN)对输入图像进行分割,得到分割掩码;2) 使用卷积神经网络或Transformer架构提取图像的特征;3) 将分割掩码编码成特征向量,并将其融合到图像特征空间中;4) 使用3D目标检测头对融合后的特征进行处理,预测3D目标的位置、大小和方向。
关键创新:该论文的关键创新在于将预计算的分割信息直接融合到特征空间中,从而引导3D目标检测。与现有方法相比,该方法不需要联合学习分割信息和3D目标检测,降低了计算复杂度,并且可以更好地利用分割信息来提高深度估计的准确性。此外,该方法可以很容易地集成到现有的3D目标检测框架中,具有良好的通用性。
关键设计:分割信息的融合方式是关键设计之一。论文中具体如何编码分割掩码为特征向量,以及如何将分割特征向量与图像特征进行融合(例如,使用concatenate或element-wise addition等操作)的具体细节未知。损失函数方面,论文沿用了原检测器的损失函数,没有针对分割信息进行特殊设计。
🖼️ 关键图片

📊 实验亮点
该方法在KITTI 3D目标检测基准上进行了评估,实验结果表明,该方法在小物体(行人和自行车)的检测方面优于仅依赖RGB图像特征的等效架构。具体的性能提升数据未知,但论文强调了分割信息对于小目标检测的积极作用,证明了理解输入数据的重要性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能监控等领域。在这些场景中,准确的3D目标检测至关重要。通过利用分割信息,可以提高单目视觉系统的感知能力,使其在复杂环境中更好地理解周围环境,从而提高系统的安全性和可靠性。未来,该方法可以进一步扩展到其他视觉任务中,例如场景理解、图像编辑等。
📄 摘要(原文)
Monocular 3D Object Detection represents a challenging Computer Vision task due to the nature of the input used, which is a single 2D image, lacking in any depth cues and placing the depth estimation problem as an ill-posed one. Existing solutions leverage the information extracted from the input by using Convolutional Neural Networks or Transformer architectures as feature extraction backbones, followed by specific detection heads for 3D parameters prediction. In this paper, we introduce a decoupled strategy based on injecting precomputed segmentation information priors and fusing them directly into the feature space for guiding the detection, without expanding the detection model or jointly learning the priors. The focus is on evaluating the impact of additional segmentation information on existing detection pipelines without adding additional prediction branches. The proposed method is evaluated on the KITTI 3D Object Detection Benchmark, outperforming the equivalent architecture that relies only on RGB image features for small objects in the scene: pedestrians and cyclists, and proving that understanding the input data can balance the need for additional sensors or training data.