Compression Beyond Pixels: Semantic Compression with Multimodal Foundation Models
作者: Ruiqi Shen, Haotian Wu, Wenjing Zhang, Jiangjing Hu, Deniz Gunduz
分类: cs.CV, cs.IT
发布日期: 2025-09-07
备注: Published as a conference paper at IEEE 35th Workshop on Machine Learning for Signal Processing (MLSP)
💡 一句话要点
提出基于多模态大模型的语义压缩方法,超越像素级重建。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义压缩 多模态学习 CLIP模型 零样本学习 图像表征
📋 核心要点
- 传统图像压缩侧重像素级重建,忽略了新兴应用对语义保持的需求以及跨域鲁棒性。
- 利用CLIP模型的强大表征能力,直接压缩图像的CLIP特征嵌入,而非原始像素。
- 实验表明,该方法在极低比特率下仍能保持语义完整性,并展现出优异的零样本泛化能力。
📝 摘要(中文)
现有的基于深度学习的图像有损压缩方法通过大量的端到端训练和先进的架构实现了具有竞争力的率失真性能。然而,新兴应用越来越重视语义信息的保持而非像素级的重建,并要求在不同的数据分布和下游任务中具有鲁棒的性能。这些挑战需要更先进的语义压缩范式。受多模态基础模型的零样本和表征能力的启发,我们提出了一种基于对比语言-图像预训练(CLIP)模型的新型语义压缩方法。我们没有压缩用于重建的图像,而是提出将CLIP特征嵌入压缩成最小的比特,同时保持不同任务中的语义信息。实验表明,我们的方法在基准数据集上保持了语义完整性,实现了大约2-3*10(-3)比特/像素的平均比特率。这不到主流图像压缩方法在类似性能下所需比特率的5%。值得注意的是,即使在极端压缩下,所提出的方法也表现出跨不同数据分布和下游任务的零样本鲁棒性。
🔬 方法详解
问题定义:现有图像压缩方法主要关注像素级别的重建,而忽略了图像的语义信息。在许多实际应用中,例如图像检索、图像分类等,语义信息的保持比像素级别的精确重建更为重要。此外,现有方法通常需要针对特定数据集进行训练,泛化能力较差。因此,如何设计一种能够有效压缩图像语义信息,并且具有良好泛化能力的压缩方法是一个重要的挑战。
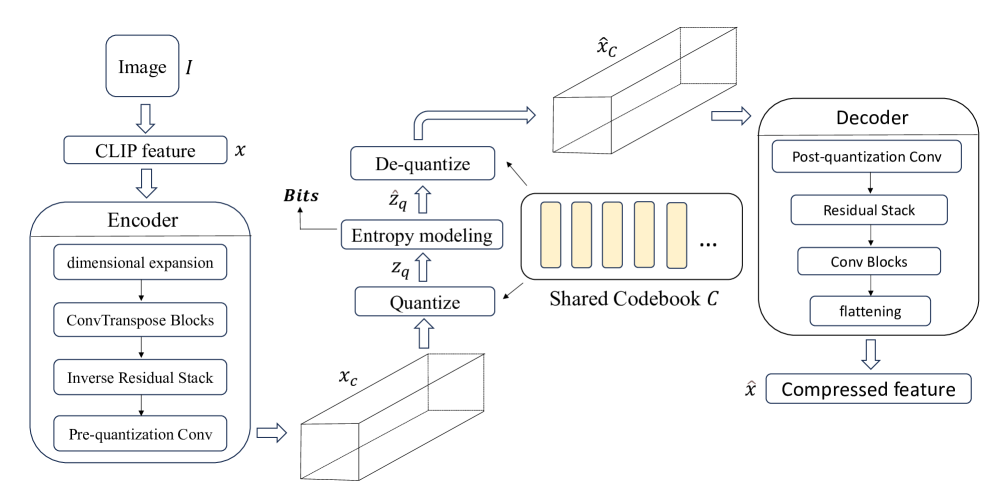
核心思路:该论文的核心思路是利用多模态预训练模型(CLIP)强大的语义表征能力,将图像压缩问题转化为对CLIP特征向量的压缩问题。通过压缩CLIP特征,可以在保证语义信息的前提下,大幅降低比特率。同时,由于CLIP模型本身具有良好的泛化能力,因此该方法也能够实现跨数据集的零样本压缩。
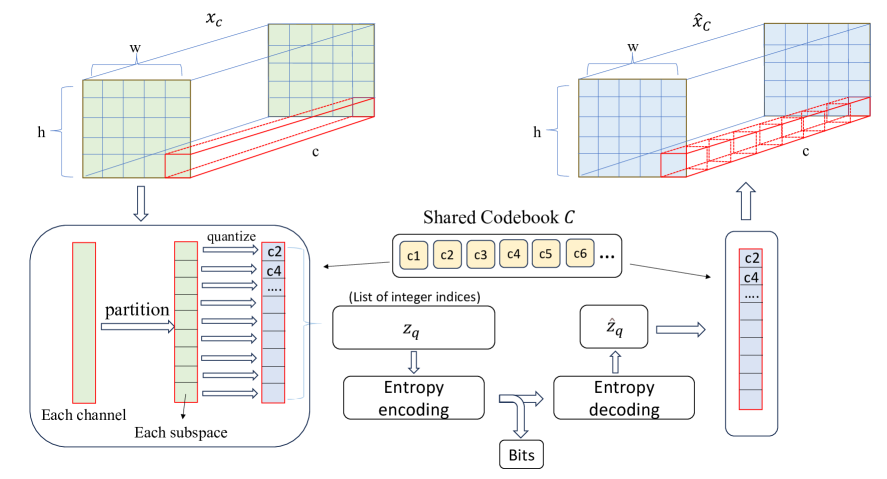
技术框架:该方法主要包含两个阶段:特征提取和特征压缩。首先,使用CLIP模型提取图像的特征向量。然后,使用一种压缩算法(具体算法未详细说明,但暗示是某种量化或编码方法)对CLIP特征向量进行压缩。在解码端,只需要解压缩CLIP特征向量,然后就可以直接用于各种下游任务,而无需进行像素级别的图像重建。
关键创新:该方法最重要的创新点在于将多模态预训练模型引入到图像压缩领域,并且将压缩目标从像素级别转换到语义级别。这种方法能够有效利用预训练模型的知识,从而在极低的比特率下实现良好的语义保持能力。
关键设计:论文中没有详细说明具体的压缩算法和网络结构,但可以推测,关键设计可能包括:1)如何选择合适的CLIP模型;2)如何设计高效的特征压缩算法,例如量化、熵编码等;3)如何评估压缩后的特征向量的语义保持能力。
🖼️ 关键图片

📊 实验亮点
该方法在基准数据集上实现了平均2-3*10(-3)比特/像素的比特率,仅为主流图像压缩方法所需比特率的5%。即使在极端压缩条件下,该方法仍然表现出良好的零样本鲁棒性,能够在不同的数据分布和下游任务中保持语义完整性。这些结果表明,该方法在语义压缩方面具有显著的优势。
🎯 应用场景
该研究成果可应用于对存储空间或传输带宽有严格限制的场景,例如移动设备上的图像存储、无线传感器网络中的图像传输、以及大规模图像数据库的压缩存储。通过在极低比特率下保持图像的语义信息,可以有效降低存储成本和传输延迟,同时保证下游任务的性能。该方法还有潜力应用于视频压缩领域,实现更高效的视频语义压缩。
📄 摘要(原文)
Recent deep learning-based methods for lossy image compression achieve competitive rate-distortion performance through extensive end-to-end training and advanced architectures. However, emerging applications increasingly prioritize semantic preservation over pixel-level reconstruction and demand robust performance across diverse data distributions and downstream tasks. These challenges call for advanced semantic compression paradigms. Motivated by the zero-shot and representational capabilities of multimodal foundation models, we propose a novel semantic compression method based on the contrastive language-image pretraining (CLIP) model. Rather than compressing images for reconstruction, we propose compressing the CLIP feature embeddings into minimal bits while preserving semantic information across different tasks. Experiments show that our method maintains semantic integrity across benchmark datasets, achieving an average bit rate of approximately 2-3* 10(-3) bits per pixel. This is less than 5% of the bitrate required by mainstream image compression approaches for comparable performance. Remarkably, even under extreme compression, the proposed approach exhibits zero-shot robustness across diverse data distributions and downstream tasks.