Unleashing Hierarchical Reasoning: An LLM-Driven Framework for Training-Free Referring Video Object Segmentation
作者: Bingrui Zhao, Lin Yuanbo Wu, Xiangtian Fan, Deyin Liu, Lu Zhang, Ruyi He, Jialie Shen, Ximing Li
分类: cs.CV, cs.AI
发布日期: 2025-09-06
💡 一句话要点
提出PARSE-VOS以解决视频物体分割中的语言与视觉对齐问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 引用视频物体分割 大型语言模型 时空定位 分层推理 无训练框架 语义解析 动态场景理解
📋 核心要点
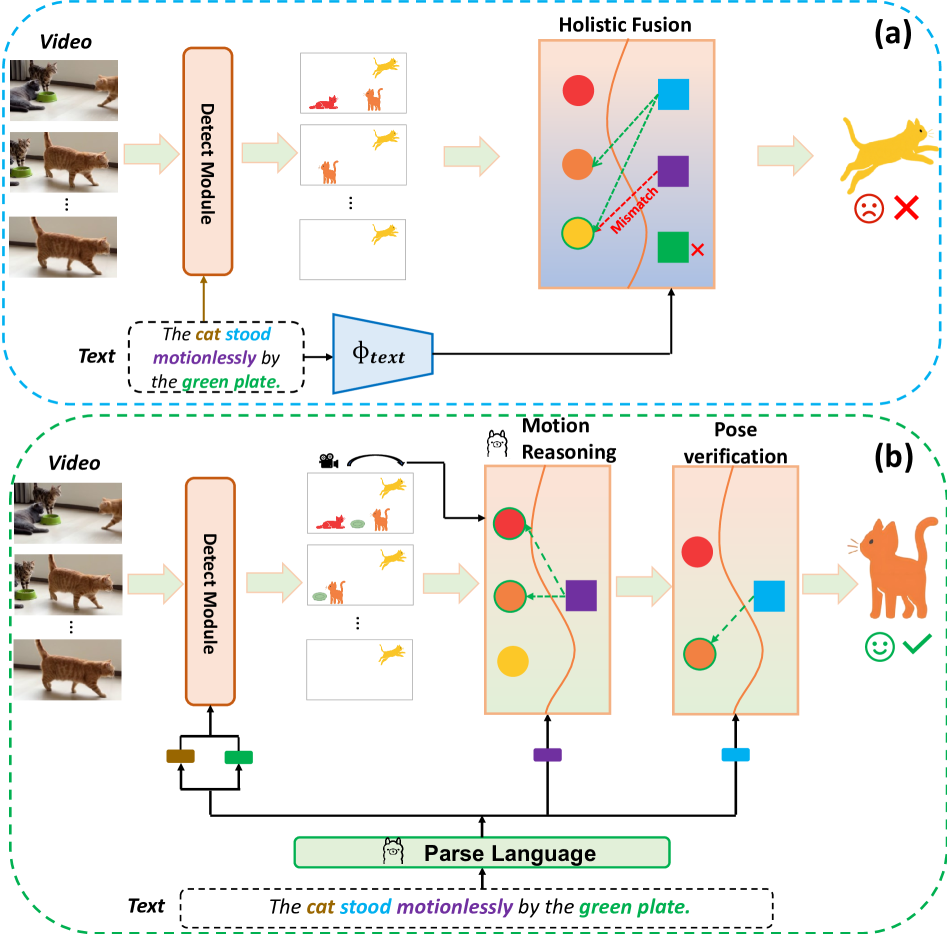
- 现有的引用视频物体分割方法在处理复杂的语言描述与动态视觉内容对齐时存在显著不足。
- 本文提出的PARSE-VOS框架通过解析自然语言查询并结合时空信息,实现了分层的粗到细推理。
- PARSE-VOS在多个基准测试中表现优异,达到了最先进的性能,展示了其有效性和实用性。
📝 摘要(中文)
引用视频物体分割(RVOS)旨在根据语言描述对视频中的目标对象进行分割。主要挑战在于将静态文本与动态视觉内容对齐,尤其是在对象外观相似但运动和姿态不一致的情况下。现有方法通常依赖于整体的视觉-语言融合,难以处理复杂的组合描述。本文提出了一种新颖的无训练框架PARSE-VOS,利用大型语言模型(LLMs)实现跨文本和视频领域的分层粗到细推理。该方法首先将自然语言查询解析为结构化的语义命令,接着引入时空定位模块生成所有潜在目标对象的候选轨迹,最后通过分层识别模块进行两阶段推理,最终输出目标对象的准确分割掩膜。PARSE-VOS在Ref-YouTube-VOS、Ref-DAVIS17和MeViS三个主要基准上取得了最先进的性能。
🔬 方法详解
问题定义:本文旨在解决引用视频物体分割中的语言与视觉内容对齐问题。现有方法在处理复杂的组合描述时,往往依赖于整体的视觉-语言融合,导致性能不足。
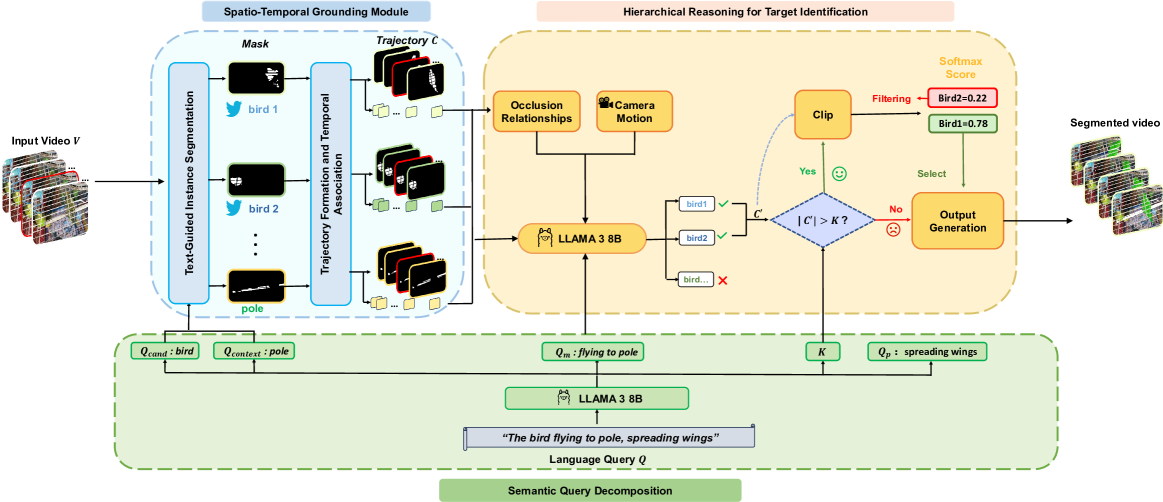
核心思路:PARSE-VOS框架的核心思路是利用大型语言模型进行分层推理,首先将语言查询解析为结构化语义命令,然后通过时空定位模块生成候选轨迹,最后进行目标识别。
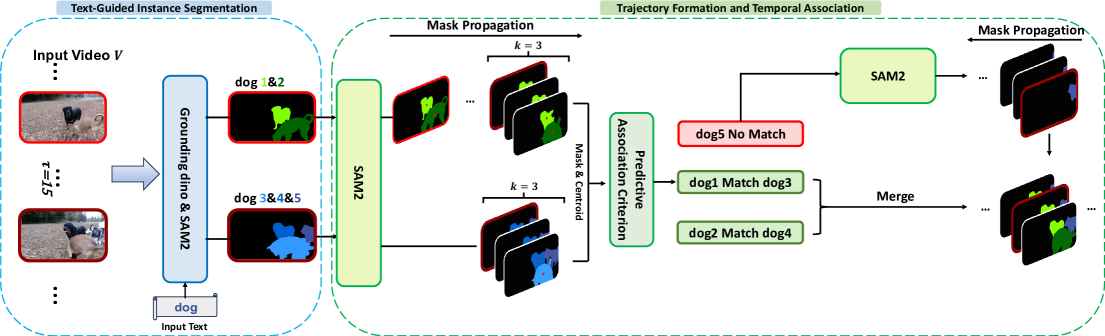
技术框架:该框架主要包括三个模块:1) 语义解析模块,将自然语言查询转化为结构化命令;2) 时空定位模块,生成所有潜在目标对象的候选轨迹;3) 分层识别模块,通过粗粒度和细粒度推理来选择正确的目标。
关键创新:PARSE-VOS的创新之处在于其无训练的特性和分层推理机制,能够有效处理复杂的语言描述,克服了现有方法的局限性。
关键设计:该方法在语义解析和时空定位中采用了特定的参数设置,确保生成的候选轨迹与解析的语义一致,同时在细粒度验证阶段引入条件触发机制,以提高识别的准确性。
🖼️ 关键图片
📊 实验亮点
PARSE-VOS在Ref-YouTube-VOS、Ref-DAVIS17和MeViS三个基准上均取得了最先进的性能,显示出其在复杂场景下的有效性。具体而言,该方法在多个任务上相较于现有基线提升了显著的分割精度,验证了其创新设计的优越性。
🎯 应用场景
PARSE-VOS框架在视频监控、自动驾驶、智能家居等领域具有广泛的应用潜力。通过精准的目标分割,能够提升系统对动态场景的理解能力,进而增强人机交互的智能化水平。未来,该技术还可能推动视频分析和理解的进一步发展。
📄 摘要(原文)
Referring Video Object Segmentation (RVOS) aims to segment an object of interest throughout a video based on a language description. The prominent challenge lies in aligning static text with dynamic visual content, particularly when objects exhibiting similar appearances with inconsistent motion and poses. However, current methods often rely on a holistic visual-language fusion that struggles with complex, compositional descriptions. In this paper, we propose \textbf{PARSE-VOS}, a novel, training-free framework powered by Large Language Models (LLMs), for a hierarchical, coarse-to-fine reasoning across text and video domains. Our approach begins by parsing the natural language query into structured semantic commands. Next, we introduce a spatio-temporal grounding module that generates all candidate trajectories for all potential target objects, guided by the parsed semantics. Finally, a hierarchical identification module select the correct target through a two-stage reasoning process: it first performs coarse-grained motion reasoning with an LLM to narrow down candidates; if ambiguity remains, a fine-grained pose verification stage is conditionally triggered to disambiguate. The final output is an accurate segmentation mask for the target object. \textbf{PARSE-VOS} achieved state-of-the-art performance on three major benchmarks: Ref-YouTube-VOS, Ref-DAVIS17, and MeViS.