Leveraging Vision-Language Large Models for Interpretable Video Action Recognition with Semantic Tokenization
作者: Jingwei Peng, Zhixuan Qiu, Boyu Jin, Surasakdi Siripong
分类: cs.CV
发布日期: 2025-09-06
💡 一句话要点
LVLM-VAR:利用视觉-语言大模型和语义Token化实现可解释的视频行为识别
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频行为识别 视觉-语言大模型 语义Token化 可解释性 行为理解
📋 核心要点
- 传统行为识别方法在处理深层语义理解、复杂上下文信息和细粒度区分方面存在局限性。
- LVLM-VAR将视频转换为语义Token,构建行为叙述,利用LVLM进行行为分类和语义推理。
- 实验表明,LVLM-VAR在多个基准测试中取得了显著的性能提升,并提高了模型的可解释性。
📝 摘要(中文)
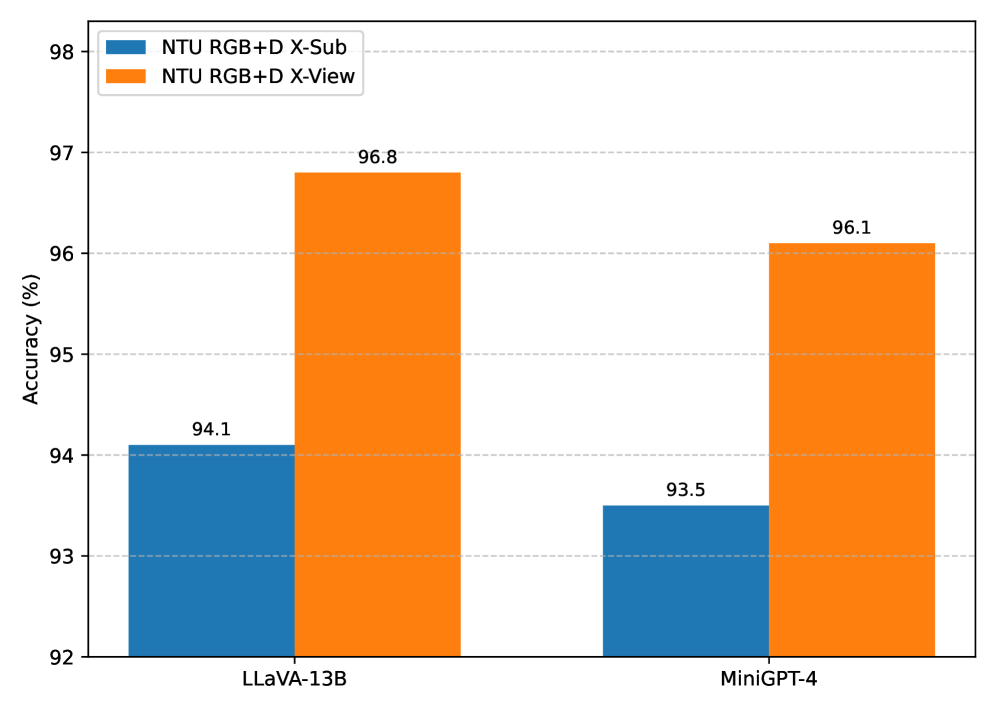
本文提出了一种名为LVLM-VAR的新框架,旨在利用预训练的视觉-语言大模型(LVLMs)进行视频行为识别,从而提高准确性和可解释性。该方法的核心是视频到语义Token(VST)模块,它将原始视频序列创新性地转换为离散的、在语义和时间上一致的“语义行为Token”,从而构建一个LVLM可以理解的“行为叙述”。这些Token与自然语言指令相结合,然后由LoRA微调的LVLM(例如LLaVA-13B)处理,以实现稳健的行为分类和语义推理。LVLM-VAR在NTU RGB+D和NTU RGB+D 120等具有挑战性的基准测试中取得了最先进或极具竞争力的性能,例如在NTU RGB+D X-Sub上达到94.1%,在NTU RGB+D 120 X-Set上达到90.0%,并且通过为其预测生成自然语言解释,显著提高了模型的可解释性。
🔬 方法详解
问题定义:现有视频行为识别方法难以有效捕捉视频中的深层语义信息,对复杂上下文的理解不足,并且在细粒度行为区分方面表现不佳。这些局限性导致模型在处理多样化视频数据时泛化能力受限。
核心思路:论文的核心思路是将视频转换为一系列具有语义信息的离散Token,类似于自然语言处理中的Tokenization。通过这种方式,可以将视频行为识别问题转化为一个视觉-语言联合理解的问题,从而利用预训练的视觉-语言大模型(LVLM)的强大能力。
技术框架:LVLM-VAR框架主要包含两个模块:视频到语义Token(VST)模块和LoRA微调的LVLM。VST模块负责将原始视频序列转换为语义行为Token。这些Token与自然语言指令一起输入到LoRA微调的LVLM(例如LLaVA-13B)中,进行行为分类和语义推理。整个流程实现了从视频到语义理解再到行为识别的端到端学习。
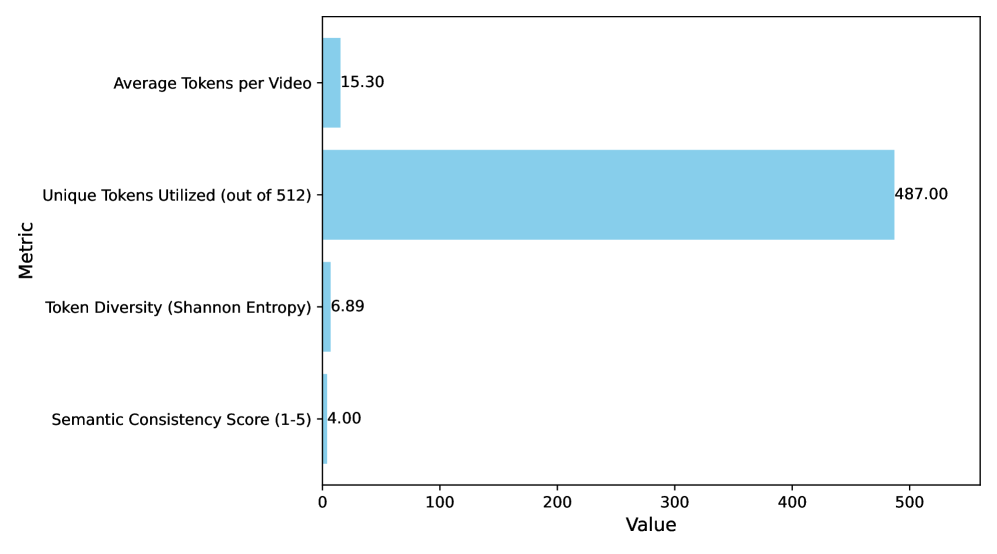
关键创新:该方法最重要的创新点在于提出了VST模块,该模块能够将原始视频转换为离散的、在语义和时间上一致的“语义行为Token”。这种转换使得LVLM能够更好地理解视频内容,并进行更准确的行为分类和语义推理。与传统的直接将视频帧输入到神经网络的方法相比,该方法更注重语义信息的提取和利用。
关键设计:VST模块的具体实现细节未知,论文中可能没有详细描述。LoRA微调LVLM时,可能需要仔细调整LoRA的参数,以平衡模型的性能和训练成本。损失函数的设计也至关重要,需要确保模型能够准确地进行行为分类,并生成合理的自然语言解释。具体参数设置和网络结构细节在论文中可能有所描述,但此处未知。
🖼️ 关键图片
📊 实验亮点
LVLM-VAR在NTU RGB+D和NTU RGB+D 120等具有挑战性的基准测试中取得了显著的性能提升。例如,在NTU RGB+D X-Sub上达到了94.1%的准确率,在NTU RGB+D 120 X-Set上达到了90.0%的准确率。这些结果表明,LVLM-VAR在视频行为识别方面具有很强的竞争力,并且能够显著提高模型的可解释性。
🎯 应用场景
该研究成果可应用于智能监控、人机交互、自动驾驶、视频内容分析等领域。通过提高视频行为识别的准确性和可解释性,可以实现更智能化的视频分析和理解,例如,在智能监控中自动识别异常行为,在人机交互中理解用户的意图,在自动驾驶中识别交通参与者的行为。
📄 摘要(原文)
Human action recognition often struggles with deep semantic understanding, complex contextual information, and fine-grained distinction, limitations that traditional methods frequently encounter when dealing with diverse video data. Inspired by the remarkable capabilities of large language models, this paper introduces LVLM-VAR, a novel framework that pioneers the application of pre-trained Vision-Language Large Models (LVLMs) to video action recognition, emphasizing enhanced accuracy and interpretability. Our method features a Video-to-Semantic-Tokens (VST) Module, which innovatively transforms raw video sequences into discrete, semantically and temporally consistent "semantic action tokens," effectively crafting an "action narrative" that is comprehensible to an LVLM. These tokens, combined with natural language instructions, are then processed by a LoRA-fine-tuned LVLM (e.g., LLaVA-13B) for robust action classification and semantic reasoning. LVLM-VAR not only achieves state-of-the-art or highly competitive performance on challenging benchmarks such as NTU RGB+D and NTU RGB+D 120, demonstrating significant improvements (e.g., 94.1% on NTU RGB+D X-Sub and 90.0% on NTU RGB+D 120 X-Set), but also substantially boosts model interpretability by generating natural language explanations for its predictions.