Dynamic Sensitivity Filter Pruning using Multi-Agent Reinforcement Learning For DCNN's
作者: Iftekhar Haider Chowdhury, Zaed Ikbal Syed, Ahmed Faizul Haque Dhrubo, Mohammad Abdul Qayum
分类: cs.CV
发布日期: 2025-09-05
备注: This paper includes figures and two tables, and our work outperforms the existing research that has been published in a journal
💡 一句话要点
提出差分敏感度融合剪枝算法,用于高效压缩深度卷积神经网络
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度卷积神经网络 模型剪枝 滤波器剪枝 模型压缩 差分敏感度 边缘计算 单次剪枝
📋 核心要点
- 深度卷积网络虽然精度高,但计算和存储开销大,限制了其在资源受限设备上的部署。
- 提出差分敏感度融合剪枝,通过融合多种敏感度指标来评估滤波器的重要性,并进行单次剪枝。
- 实验表明,该方法在显著降低模型复杂度的同时,能够保持较高的准确率,优于传统启发式方法。
📝 摘要(中文)
深度卷积神经网络在各种计算机视觉任务中取得了最先进的性能,但其计算和内存开销限制了实际部署。本文提出了一种新颖的单次滤波器剪枝框架——差分敏感度融合剪枝(Differential Sensitivity Fusion Pruning)。该方法侧重于评估滤波器重要性评分在多个标准下的稳定性和冗余性。通过融合基于梯度的敏感度、一阶泰勒展开和激活分布的KL散度之间的差异,为每个滤波器计算差分敏感度评分。采用指数缩放机制来强调在不同指标下重要性不一致的滤波器,从而识别结构不稳定或对模型性能不太关键的候选滤波器。与迭代或基于强化学习的剪枝策略不同,差分敏感度融合剪枝是高效且确定性的,只需要一次前向-后向传播即可完成评分和剪枝。在50%到70%的不同剪枝率下进行的大量实验表明,差分敏感度融合剪枝显著降低了模型复杂度,实现了超过80%的每秒浮点运算次数(FLOPs)减少,同时保持了较高的准确率。例如,在70%的剪枝率下,该方法保留了高达98.23%的基线准确率,在压缩和泛化方面均优于传统启发式方法。该方法为可扩展和自适应的深度卷积神经网络压缩提供了一种有效的解决方案,为在边缘和移动平台上的高效部署铺平了道路。
🔬 方法详解
问题定义:论文旨在解决深度卷积神经网络(DCNN)模型体积大、计算复杂度高的问题,使其难以在边缘设备或移动平台上部署。现有剪枝方法,如基于迭代或强化学习的方法,计算成本高昂,效率较低。传统启发式方法在压缩率和精度保持方面存在局限性。
核心思路:论文的核心思路是通过融合多种滤波器敏感度评估指标,综合评估滤波器的重要性,并进行单次剪枝。通过关注不同指标下滤波器重要性的差异,识别出结构不稳定或对模型性能影响较小的滤波器,从而实现高效的模型压缩。
技术框架:该方法主要包含以下几个步骤:1) 计算基于梯度的敏感度;2) 计算基于一阶泰勒展开的敏感度;3) 计算激活分布的KL散度;4) 融合上述三种敏感度指标,计算差分敏感度评分;5) 应用指数缩放机制,突出不一致的滤波器;6) 根据差分敏感度评分进行滤波器剪枝。整个过程只需要一次前向-后向传播。
关键创新:该方法最重要的创新点在于提出了差分敏感度融合的概念,通过融合多种敏感度指标的差异来更准确地评估滤波器的重要性。与传统的单一指标评估方法相比,该方法能够更有效地识别冗余或不稳定的滤波器。此外,单次剪枝的设计也提高了剪枝效率。
关键设计:论文的关键设计包括:1) 差分敏感度评分的计算方式,即如何融合梯度、泰勒展开和KL散度;2) 指数缩放机制,用于放大不同指标下不一致的滤波器的重要性;3) 剪枝率的选择,需要在压缩率和精度之间进行权衡;4) 具体网络结构的选择,论文在多种经典网络上进行了实验。
🖼️ 关键图片

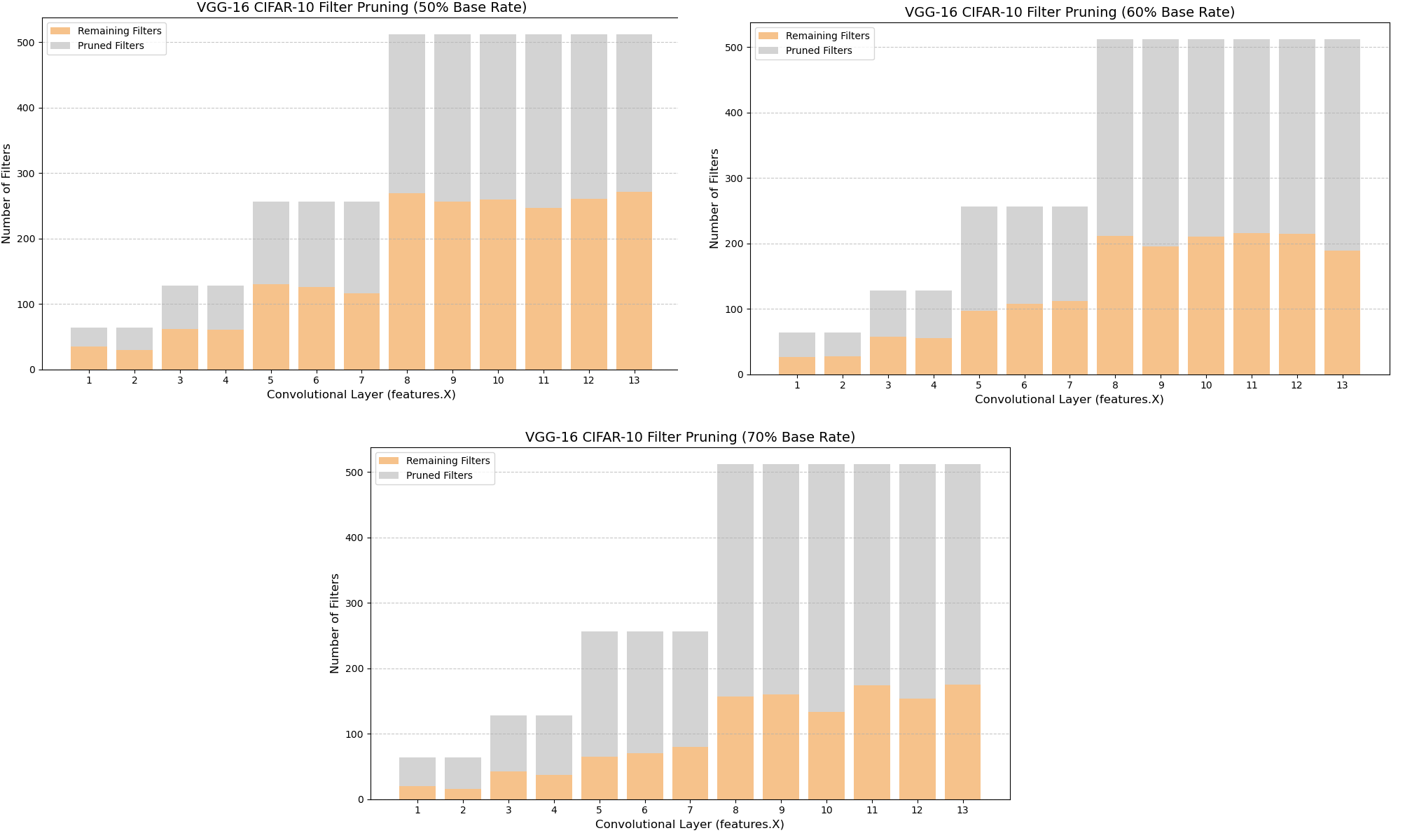
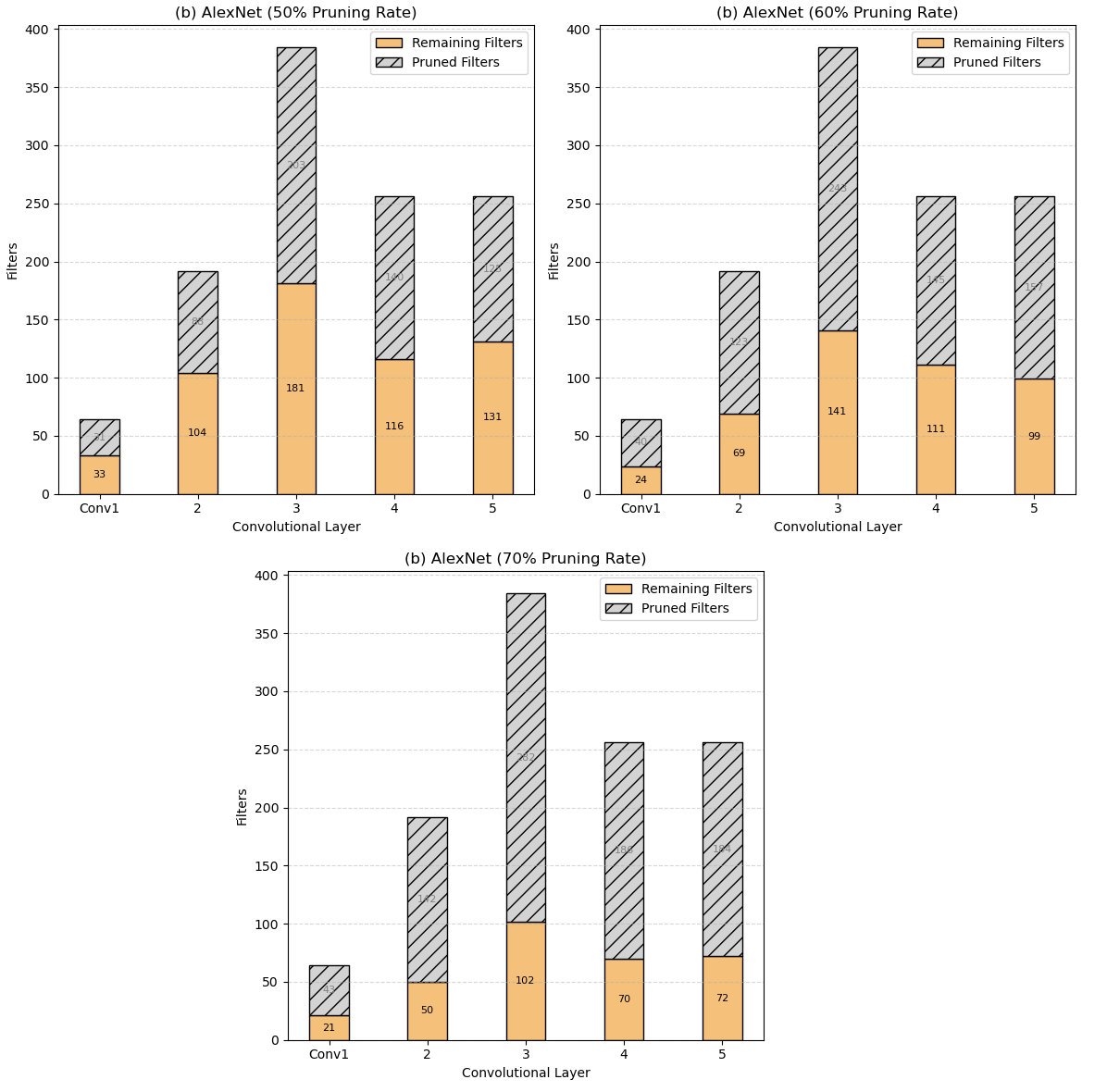
📊 实验亮点
实验结果表明,该方法在50%到70%的剪枝率下,能够实现超过80%的FLOPs减少,同时保持较高的准确率。例如,在70%的剪枝率下,该方法保留了高达98.23%的基线准确率,优于传统的启发式剪枝方法。这些结果表明,该方法在模型压缩和泛化能力方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要部署深度学习模型的边缘设备和移动平台,例如智能手机、无人机、自动驾驶汽车等。通过降低模型的计算和存储开销,可以提高模型的推理速度和能效,从而实现更高效的AI应用。此外,该方法还可以用于模型加速和模型压缩,为深度学习在资源受限环境下的应用提供了一种有效的解决方案。
📄 摘要(原文)
Deep Convolutional Neural Networks have achieved state of the art performance across various computer vision tasks, however their practical deployment is limited by computational and memory overhead. This paper introduces Differential Sensitivity Fusion Pruning, a novel single shot filter pruning framework that focuses on evaluating the stability and redundancy of filter importance scores across multiple criteria. Differential Sensitivity Fusion Pruning computes a differential sensitivity score for each filter by fusing the discrepancies among gradient based sensitivity, first order Taylor expansion, and KL divergence of activation distributions. An exponential scaling mechanism is applied to emphasize filters with inconsistent importance across metrics, identifying candidates that are structurally unstable or less critical to the model performance. Unlike iterative or reinforcement learning based pruning strategies, Differential Sensitivity Fusion Pruning is efficient and deterministic, requiring only a single forward-backward pass for scoring and pruning. Extensive experiments across varying pruning rates between 50 to 70 percent demonstrate that Differential Sensitivity Fusion Pruning significantly reduces model complexity, achieving over 80 percent Floating point Operations Per Seconds reduction while maintaining high accuracy. For instance, at 70 percent pruning, our approach retains up to 98.23 percent of baseline accuracy, surpassing traditional heuristics in both compression and generalization. The proposed method presents an effective solution for scalable and adaptive Deep Convolutional Neural Networks compression, paving the way for efficient deployment on edge and mobile platforms.