3D and 4D World Modeling: A Survey
作者: Lingdong Kong, Wesley Yang, Jianbiao Mei, Youquan Liu, Ao Liang, Dekai Zhu, Dongyue Lu, Wei Yin, Xiaotao Hu, Mingkai Jia, Junyuan Deng, Kaiwen Zhang, Yang Wu, Tianyi Yan, Shenyuan Gao, Song Wang, Linfeng Li, Liang Pan, Yong Liu, Jianke Zhu, Wei Tsang Ooi, Steven C. H. Hoi, Ziwei Liu
分类: cs.CV, cs.RO
发布日期: 2025-09-04 (更新: 2025-12-03)
备注: Survey; 50 pages, 10 figures, 14 tables; GitHub Repo at https://github.com/worldbench/awesome-3d-4d-world-models
🔗 代码/项目: GITHUB
💡 一句话要点
对3D和4D世界建模与生成进行全面综述,填补了该领域系统性研究的空白。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D世界建模 4D世界建模 世界模型 综述 深度学习 计算机视觉 机器人 场景理解
📋 核心要点
- 现有世界建模研究主要集中在2D图像和视频,忽略了3D/4D数据建模的潜力与挑战。
- 该综述对3D/4D世界建模进行了系统性梳理,建立了统一的定义和分类体系,填补了领域空白。
- 论文总结了3D/4D世界建模的数据集、评估指标和应用,并探讨了未来研究方向。
📝 摘要(中文)
世界建模已成为人工智能研究的基石,使智能体能够理解、表示和预测其所处的动态环境。以往的工作主要强调2D图像和视频数据的生成方法,而忽略了利用原生3D和4D表示(如RGB-D图像、 occupancy grids 和 LiDAR 点云)进行大规模场景建模的快速增长的研究。同时,由于缺乏对“世界模型”的标准化定义和分类,导致文献中出现碎片化和不一致的说法。本综述通过首次全面回顾专门针对3D和4D世界建模和生成的研究来解决这些问题。我们建立了精确的定义,引入了一个结构化的分类,涵盖了基于视频(VideoGen)、基于 occupancy (OccGen)和基于 LiDAR(LiDARGen)的方法,并系统地总结了为3D/4D设置量身定制的数据集和评估指标。我们进一步讨论了实际应用,识别了开放的挑战,并强调了有希望的研究方向,旨在为推进该领域提供一个连贯和基础的参考。
🔬 方法详解
问题定义:现有世界建模研究主要集中在2D图像和视频的生成方法,忽略了原生3D和4D表示(如RGB-D图像、 occupancy grids 和 LiDAR 点云)在大规模场景建模中的应用。此外,缺乏对“世界模型”的标准化定义和分类,导致研究方向分散,结论不一致。
核心思路:本综述旨在通过对3D和4D世界建模与生成进行全面回顾,建立精确的定义和结构化的分类体系,为该领域的研究提供一个连贯和基础的参考。核心思路是系统性地整理和分析现有文献,并从视频、occupancy和LiDAR三种模态出发,对相关方法进行归纳和比较。
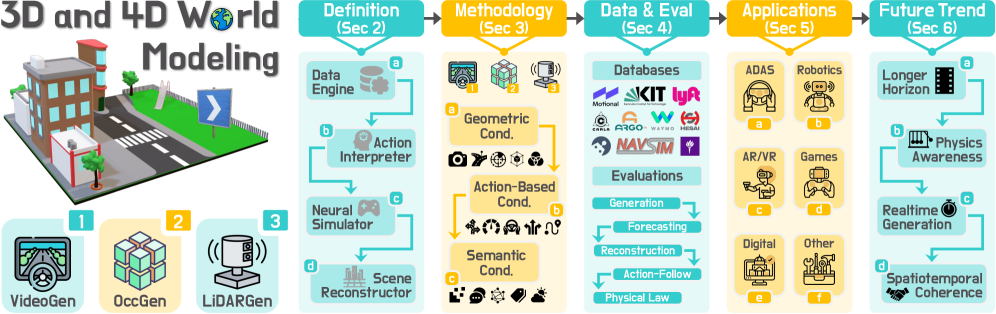
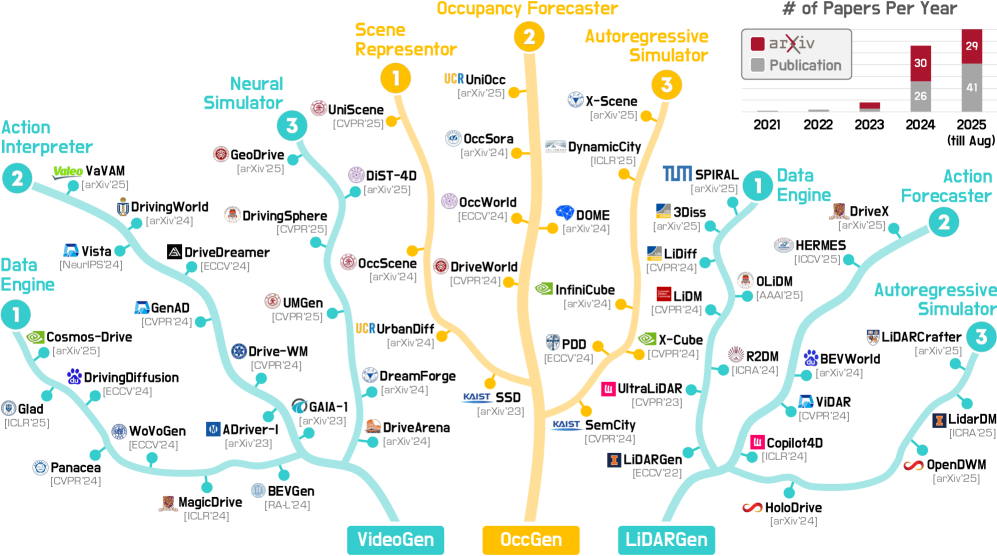
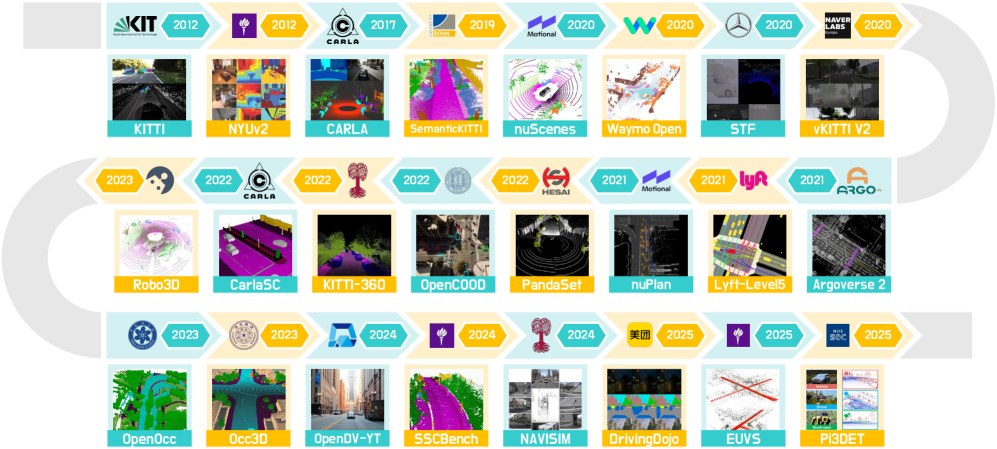
技术框架:该综述的技术框架主要包括以下几个方面:首先,对“世界模型”进行精确定义,明确其内涵和外延。其次,构建一个结构化的分类体系,将现有方法划分为VideoGen、OccGen和LiDARGen三大类。然后,对每一类方法进行详细的介绍和分析,包括其基本原理、优缺点和适用场景。此外,还总结了3D/4D世界建模常用的数据集和评估指标。最后,讨论了该领域的实际应用、开放挑战和未来研究方向。
关键创新:该综述的关键创新在于:1) 首次全面回顾了3D和4D世界建模与生成的研究,填补了该领域的空白;2) 建立了精确的定义和结构化的分类体系,为该领域的研究提供了一个统一的框架;3) 系统地总结了3D/4D世界建模的数据集和评估指标,为研究人员提供了便利。
关键设计:该综述的关键设计在于其结构化的分类体系,将现有方法划分为VideoGen、OccGen和LiDARGen三大类,并对每一类方法进行详细的介绍和分析。这种分类方式能够帮助研究人员更好地理解和比较不同的方法,并为未来的研究提供指导。
🖼️ 关键图片
📊 实验亮点
该综述系统性地总结了3D/4D世界建模的数据集和评估指标,为研究人员提供了便利。同时,论文还讨论了该领域的实际应用、开放挑战和未来研究方向,为未来的研究提供了指导。该综述在github上开源了相关资源,方便研究人员进一步学习和探索。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、虚拟现实、增强现实等领域。通过构建精确的3D/4D世界模型,智能体可以更好地理解和预测周围环境,从而实现更安全、更高效的自主行为。此外,该综述还可以为相关领域的研究人员提供参考,促进该领域的进一步发展。
📄 摘要(原文)
World modeling has become a cornerstone in AI research, enabling agents to understand, represent, and predict the dynamic environments they inhabit. While prior work largely emphasizes generative methods for 2D image and video data, they overlook the rapidly growing body of work that leverages native 3D and 4D representations such as RGB-D imagery, occupancy grids, and LiDAR point clouds for large-scale scene modeling. At the same time, the absence of a standardized definition and taxonomy for ``world models'' has led to fragmented and sometimes inconsistent claims in the literature. This survey addresses these gaps by presenting the first comprehensive review explicitly dedicated to 3D and 4D world modeling and generation. We establish precise definitions, introduce a structured taxonomy spanning video-based (VideoGen), occupancy-based (OccGen), and LiDAR-based (LiDARGen) approaches, and systematically summarize datasets and evaluation metrics tailored to 3D/4D settings. We further discuss practical applications, identify open challenges, and highlight promising research directions, aiming to provide a coherent and foundational reference for advancing the field. A systematic summary of existing literature is available at https://github.com/worldbench/awesome-3d-4d-world-models