PromptEnhancer: A Simple Approach to Enhance Text-to-Image Models via Chain-of-Thought Prompt Rewriting
作者: Linqing Wang, Ximing Xing, Yiji Cheng, Zhiyuan Zhao, Donghao Li, Tiankai Hang, Jiale Tao, Qixun Wang, Ruihuang Li, Comi Chen, Xin Li, Mingrui Wu, Xinchi Deng, Shuyang Gu, Chunyu Wang, Qinglin Lu
分类: cs.CV
发布日期: 2025-09-04 (更新: 2025-09-23)
备注: Technical Report. Project Page: https://hunyuan-promptenhancer.github.io/
💡 一句话要点
提出PromptEnhancer,通过思维链提示重写增强文本到图像生成模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 提示工程 思维链 强化学习 奖励模型
📋 核心要点
- 现有的文本到图像模型在处理复杂用户提示时,尤其是在属性绑定、否定和组合关系方面存在困难,导致用户意图与生成结果不匹配。
- PromptEnhancer通过训练一个思维链(CoT)重写器来优化提示,该重写器由一个专门的奖励模型AlignEvaluator指导,从而生成更精确的提示。
- 实验表明,PromptEnhancer显著提高了图像-文本对齐,并在HunyuanImage 2.1模型上进行了验证,同时还引入了一个新的高质量人类偏好基准。
📝 摘要(中文)
本文提出PromptEnhancer,一种新颖且通用的提示重写框架,用于增强预训练的文本到图像(T2I)模型,无需修改模型权重。与依赖于模型特定微调或隐式奖励信号(如图像奖励分数)的现有方法不同,该框架将重写器与生成器解耦。通过强化学习训练一个思维链(CoT)重写器,并由一个名为AlignEvaluator的专用奖励模型指导。AlignEvaluator基于24个关键点的系统分类提供显式和细粒度的反馈,这些关键点源于对常见T2I失败模式的全面分析。通过优化CoT重写器以最大化来自AlignEvaluator的奖励,该框架学习生成能够被T2I模型更精确地解释的提示。在HunyuanImage 2.1模型上的大量实验表明,PromptEnhancer显著提高了各种语义和组合挑战中的图像-文本对齐。此外,还引入了一个新的高质量人类偏好基准,以促进未来在这方面的研究。
🔬 方法详解
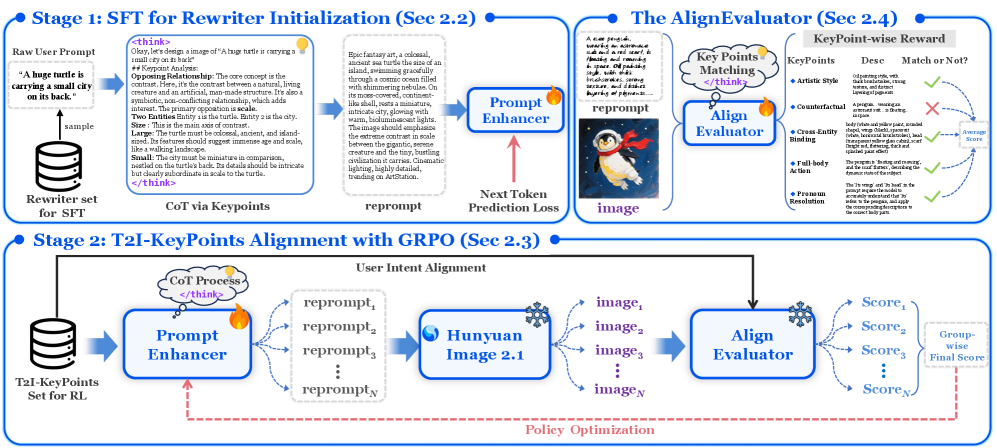
问题定义:文本到图像生成模型难以准确理解和生成复杂的用户提示,尤其是在处理属性绑定、否定和组合关系时,导致生成图像与用户意图不符。现有方法通常需要模型特定微调或依赖隐式奖励信号,缺乏通用性和可解释性。
核心思路:将提示重写器与图像生成器解耦,通过强化学习训练一个思维链(CoT)重写器,使其能够生成更易于图像生成模型理解的提示。核心在于利用一个专门训练的奖励模型(AlignEvaluator)提供细粒度的反馈,指导重写器优化提示。
技术框架:PromptEnhancer框架包含两个主要模块:CoT重写器和AlignEvaluator。CoT重写器负责根据原始提示生成新的提示,AlignEvaluator则评估新提示与原始提示的对齐程度,并提供奖励信号。通过强化学习,CoT重写器不断优化其生成策略,以最大化来自AlignEvaluator的奖励。整个过程无需修改预训练的图像生成模型。
关键创新:核心创新在于解耦了提示重写器和图像生成器,并引入了AlignEvaluator作为显式和细粒度的奖励模型。AlignEvaluator基于对T2I模型失败模式的系统分析,定义了24个关键点,从而能够更准确地评估提示的质量。此外,使用思维链(CoT)方法增强了重写器的推理能力。
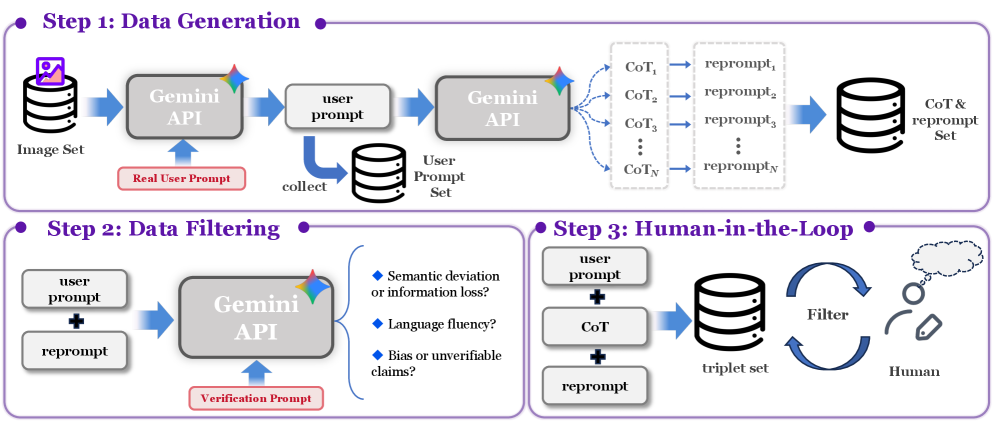
关键设计:AlignEvaluator的训练数据来源于对T2I模型失败案例的分析,并人工标注了24个关键点。强化学习算法使用PPO(Proximal Policy Optimization)进行训练。CoT重写器采用Transformer架构,输入为原始提示,输出为重写后的提示。奖励函数的设计至关重要,它直接影响重写器的优化方向。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PromptEnhancer在HunyuanImage 2.1模型上显著提高了图像-文本对齐,尤其是在处理复杂的语义和组合关系时。具体性能数据和提升幅度未在摘要中给出,属于未知信息。此外,该论文还引入了一个新的高质量人类偏好基准,为未来的研究提供了参考。
🎯 应用场景
PromptEnhancer可广泛应用于各种文本到图像生成任务,例如艺术创作、产品设计、内容生成等。通过提高生成图像与用户意图的对齐程度,可以提升用户体验,并降低人工干预的需求。该研究对于推动文本到图像生成技术在实际场景中的应用具有重要意义。
📄 摘要(原文)
Recent advancements in text-to-image (T2I) diffusion models have demonstrated remarkable capabilities in generating high-fidelity images. However, these models often struggle to faithfully render complex user prompts, particularly in aspects like attribute binding, negation, and compositional relationships. This leads to a significant mismatch between user intent and the generated output. To address this challenge, we introduce PromptEnhancer, a novel and universal prompt rewriting framework that enhances any pretrained T2I model without requiring modifications to its weights. Unlike prior methods that rely on model-specific fine-tuning or implicit reward signals like image-reward scores, our framework decouples the rewriter from the generator. We achieve this by training a Chain-of-Thought (CoT) rewriter through reinforcement learning, guided by a dedicated reward model we term the AlignEvaluator. The AlignEvaluator is trained to provide explicit and fine-grained feedback based on a systematic taxonomy of 24 key points, which are derived from a comprehensive analysis of common T2I failure modes. By optimizing the CoT rewriter to maximize the reward from our AlignEvaluator, our framework learns to generate prompts that are more precisely interpreted by T2I models. Extensive experiments on the HunyuanImage 2.1 model demonstrate that PromptEnhancer significantly improves image-text alignment across a wide range of semantic and compositional challenges. Furthermore, we introduce a new, high-quality human preference benchmark to facilitate future research in this direction.