Few-step Flow for 3D Generation via Marginal-Data Transport Distillation
作者: Zanwei Zhou, Taoran Yi, Jiemin Fang, Chen Yang, Lingxi Xie, Xinggang Wang, Wei Shen, Qi Tian
分类: cs.CV
发布日期: 2025-09-04
备注: Project page: https://github.com/Zanue/MDT-dist
💡 一句话要点
提出MDT-dist框架,通过边缘数据传输蒸馏加速3D生成模型的采样过程。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 3D生成 流模型 蒸馏 边缘数据传输 速度匹配 速度蒸馏 模型加速
📋 核心要点
- 现有的基于流的3D生成模型推理时需要大量的采样步骤,计算成本高昂。
- 提出MDT-dist框架,通过边缘数据传输蒸馏,将优化目标分解为速度匹配和速度蒸馏两个可优化目标。
- 实验表明,该方法显著减少了采样步骤,并在保持视觉和几何保真度的前提下,实现了更高的生成速度。
📝 摘要(中文)
本文提出了一种名为MDT-dist的新框架,用于加速3D流模型的采样过程。该方法基于一个核心目标:蒸馏预训练模型以学习边缘数据传输。直接学习此目标需要积分速度场,但该积分难以实现。因此,论文提出了两个可优化的目标,即速度匹配(VM)和速度蒸馏(VD),以等效地将优化目标从传输级别转换为速度级别和分布级别。速度匹配(VM)学习稳定地匹配学生和教师之间的速度场,但不可避免地提供有偏差的梯度估计。速度蒸馏(VD)通过利用学习到的速度场来执行概率密度蒸馏,从而进一步增强优化过程。在TRELLIS框架上的评估表明,该方法将每个流变换器的采样步骤从25步减少到1或2步,在A800上实现了0.68秒(1步x 2)和0.94秒(2步x 2)的延迟,速度分别提高了9.0倍和6.5倍,同时保持了较高的视觉和几何保真度。大量实验表明,该方法明显优于现有的CM蒸馏方法,并使TRELLIS能够在少步3D生成中实现卓越的性能。
🔬 方法详解
问题定义:现有的基于流的3D生成模型,在推理阶段需要大量的采样步骤,导致计算开销巨大,限制了其在实际应用中的部署。现有的加速方法,如Consistency Models (CMs),在2D扩散模型上取得了显著进展,但在更复杂的3D生成任务中仍未得到充分探索。
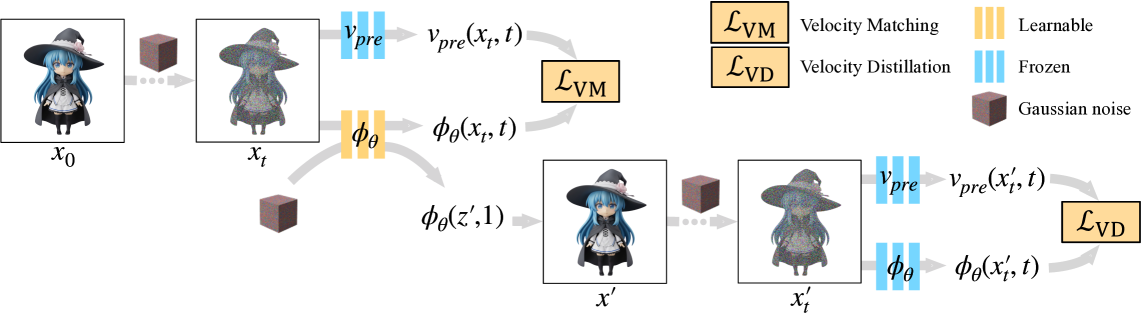
核心思路:论文的核心思路是通过蒸馏预训练模型,学习边缘数据传输。由于直接学习边缘数据传输需要积分速度场,而该积分难以实现,因此将优化目标分解为两个可优化的目标:速度匹配(VM)和速度蒸馏(VD)。通过这种方式,将优化目标从传输层面转换到速度和分布层面,从而简化了优化过程。
技术框架:MDT-dist框架包含两个主要阶段:首先,通过速度匹配(VM)学习学生模型和教师模型之间的速度场,使学生模型能够模仿教师模型的行为。然后,通过速度蒸馏(VD),利用学习到的速度场进行概率密度蒸馏,进一步提高学生模型的生成质量。整体流程是先通过VM初步对齐速度场,再通过VD进行精细的概率密度蒸馏。
关键创新:该方法最重要的技术创新在于将边缘数据传输的蒸馏问题,分解为速度匹配和速度蒸馏两个可优化的目标。这种分解避免了直接积分速度场的难题,使得可以使用更有效的优化方法来训练学生模型。此外,速度蒸馏(VD)利用学习到的速度场进行概率密度蒸馏,进一步提高了生成质量。
关键设计:速度匹配(VM)使用均方误差损失函数来衡量学生模型和教师模型速度场之间的差异。速度蒸馏(VD)使用KL散度或类似的概率密度距离度量来衡量学生模型和教师模型生成分布之间的差异。具体的网络结构取决于所使用的3D生成框架(例如,TRELLIS中的流变换器)。关键参数包括蒸馏的步数、学习率以及VM和VD损失函数的权重。
🖼️ 关键图片


📊 实验亮点
在TRELLIS框架上,MDT-dist将采样步骤从25步减少到1或2步,在A800 GPU上实现了0.68秒(1步x 2)和0.94秒(2步x 2)的延迟,速度分别提高了9.0倍和6.5倍,同时保持了较高的视觉和几何保真度。该方法显著优于现有的CM蒸馏方法。
🎯 应用场景
该研究成果可应用于实时3D内容生成、虚拟现实/增强现实、游戏开发、以及需要快速生成3D模型的各种应用场景。通过减少采样步骤,可以显著降低计算成本,提高用户体验,并促进3D生成技术在资源受限设备上的部署。
📄 摘要(原文)
Flow-based 3D generation models typically require dozens of sampling steps during inference. Though few-step distillation methods, particularly Consistency Models (CMs), have achieved substantial advancements in accelerating 2D diffusion models, they remain under-explored for more complex 3D generation tasks. In this study, we propose a novel framework, MDT-dist, for few-step 3D flow distillation. Our approach is built upon a primary objective: distilling the pretrained model to learn the Marginal-Data Transport. Directly learning this objective needs to integrate the velocity fields, while this integral is intractable to be implemented. Therefore, we propose two optimizable objectives, Velocity Matching (VM) and Velocity Distillation (VD), to equivalently convert the optimization target from the transport level to the velocity and the distribution level respectively. Velocity Matching (VM) learns to stably match the velocity fields between the student and the teacher, but inevitably provides biased gradient estimates. Velocity Distillation (VD) further enhances the optimization process by leveraging the learned velocity fields to perform probability density distillation. When evaluated on the pioneer 3D generation framework TRELLIS, our method reduces sampling steps of each flow transformer from 25 to 1 or 2, achieving 0.68s (1 step x 2) and 0.94s (2 steps x 2) latency with 9.0x and 6.5x speedup on A800, while preserving high visual and geometric fidelity. Extensive experiments demonstrate that our method significantly outperforms existing CM distillation methods, and enables TRELLIS to achieve superior performance in few-step 3D generation.