Efficient Odd-One-Out Anomaly Detection
作者: Silvio Chito, Paolo Rabino, Tatiana Tommasi
分类: cs.CV
发布日期: 2025-09-04
备注: Accepted at ICIAP 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出一种高效的基于DINO的奇数项异常检测模型,在保持性能的同时显著降低参数量和训练时间。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奇数项异常检测 DINO 自监督学习 视觉推理 高效模型
📋 核心要点
- 奇数项异常检测需要模型具备空间和关系推理能力,以应对复杂场景和泛化挑战。
- 论文提出基于DINO的高效模型,旨在减少参数量和训练时间,同时保持甚至提升性能。
- 实验结果表明,该模型在效率上优于现有方法,并分析了多模态大语言模型在此任务上的局限性。
📝 摘要(中文)
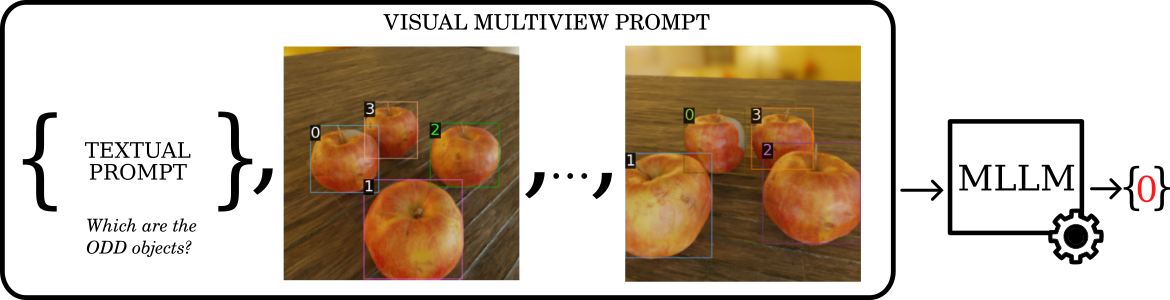
本文提出了一种用于奇数项异常检测任务的高效模型。该任务旨在识别多对象场景中看起来异常的实例。对于现代深度学习模型而言,该问题极具挑战性,它需要跨多个视图进行空间推理,并进行关系推理以理解上下文,以及在不同的对象类别和布局中进行泛化。我们认为,解决这些挑战必须以效率为前提。为此,我们提出了一种基于DINO的模型,与当前最先进的模型相比,该模型将参数数量减少了三分之一,并将训练时间缩短了三倍,同时保持了具有竞争力的性能。我们的实验评估还引入了一个多模态大型语言模型基线,提供了对其在结构化视觉推理任务中当前局限性的见解。
🔬 方法详解
问题定义:论文旨在解决奇数项异常检测问题,即在包含多个对象的场景中,识别出与其他对象不同的“异常”对象。现有方法通常计算量大,训练时间长,难以满足实际应用的需求。因此,如何在保证检测性能的同时,提高模型的效率是本文要解决的关键问题。
核心思路:论文的核心思路是利用DINO(DETR with Improved deNoising auto-encoder)自监督学习框架,通过减少模型参数和优化训练流程来提高效率。DINO能够学习到良好的视觉表征,从而支持后续的异常检测任务。同时,论文强调在设计模型时要兼顾空间推理和关系推理能力,以更好地理解场景上下文。
技术框架:整体框架基于DINO,主要包括以下几个模块:首先,使用DINO预训练的视觉Transformer提取图像特征。然后,设计一个轻量级的异常检测头,用于根据提取的特征判断每个对象是否异常。最后,通过优化损失函数,使模型能够准确地识别出奇数项。论文还探索了使用多模态大语言模型作为基线,但发现其在结构化视觉推理任务中存在局限性。
关键创新:论文的关键创新在于提出了一种高效的DINO-based模型,该模型在保持竞争力的性能的同时,显著降低了参数量和训练时间。具体来说,通过对DINO模型进行裁剪和优化,减少了冗余参数,并设计了更有效的训练策略,从而提高了模型的效率。此外,论文还对多模态大语言模型在奇数项异常检测任务中的表现进行了分析,为未来的研究提供了新的思路。
关键设计:论文对DINO模型进行了裁剪,减少了Transformer层的数量和隐藏层的大小,从而降低了参数量。在训练过程中,使用了对比学习损失和交叉熵损失,以提高模型的判别能力。此外,论文还探索了不同的数据增强策略,以提高模型的泛化能力。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的DINO-based模型在保持与当前最先进方法相当的性能水平下,将参数数量减少了三分之一,并将训练时间缩短了三倍。这表明该模型在效率方面具有显著优势。此外,论文还分析了多模态大语言模型在此任务上的局限性,为未来的研究提供了新的方向。
🎯 应用场景
该研究成果可应用于工业质检、医疗影像分析、视频监控等领域。例如,在工业质检中,可以利用该模型快速检测出生产线上不合格的产品;在医疗影像分析中,可以辅助医生识别出异常的病灶;在视频监控中,可以检测出异常行为或事件。该研究有助于提高异常检测的效率和准确性,具有重要的实际应用价值。
📄 摘要(原文)
The recently introduced odd-one-out anomaly detection task involves identifying the odd-looking instances within a multi-object scene. This problem presents several challenges for modern deep learning models, demanding spatial reasoning across multiple views and relational reasoning to understand context and generalize across varying object categories and layouts. We argue that these challenges must be addressed with efficiency in mind. To this end, we propose a DINO-based model that reduces the number of parameters by one third and shortens training time by a factor of three compared to the current state-of-the-art, while maintaining competitive performance. Our experimental evaluation also introduces a Multimodal Large Language Model baseline, providing insights into its current limitations in structured visual reasoning tasks. The project page can be found at https://silviochito.github.io/EfficientOddOneOut/