Multimodal Feature Fusion Network with Text Difference Enhancement for Remote Sensing Change Detection
作者: Yijun Zhou, Yikui Zhai, Zilu Ying, Tingfeng Xian, Wenlve Zhou, Zhiheng Zhou, Xiaolin Tian, Xudong Jia, Hongsheng Zhang, C. L. Philip Chen
分类: cs.CV, cs.AI
发布日期: 2025-09-04
🔗 代码/项目: GITHUB
💡 一句话要点
提出MMChange,一种结合图像和文本模态的遥感变化检测方法,提升精度和鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感变化检测 多模态融合 图像文本融合 视觉语言模型 语义变化 深度学习 特征精炼
📋 核心要点
- 现有遥感变化检测方法主要依赖图像模态,在光照变化和噪声干扰下,特征表示和泛化能力受限。
- MMChange结合图像和文本模态,利用视觉语言模型生成语义描述,并通过文本差异增强模块捕获细粒度语义变化。
- 在LEVIRCD、WHUCD和SYSUCD数据集上,MMChange超越了现有最佳方法,验证了其有效性。
📝 摘要(中文)
深度学习推动了遥感变化检测(RSCD)的发展,但多数方法仅依赖图像模态,限制了特征表示、变化模式建模和泛化能力,尤其是在光照和噪声干扰下。为了解决这个问题,我们提出了MMChange,一种结合图像和文本模态的RSCD方法,以提高精度和鲁棒性。引入了图像特征精炼(IFR)模块来突出关键区域并抑制环境噪声。为了克服图像特征的语义局限性,我们采用视觉语言模型(VLM)来生成双时相图像的语义描述。然后,文本差异增强(TDE)模块捕获细粒度的语义变化,引导模型关注有意义的变化。为了弥合模态之间的异构性,我们设计了图像文本特征融合(ITFF)模块,以实现深度跨模态集成。在LEVIRCD、WHUCD和SYSUCD上的大量实验表明,MMChange在多个指标上始终优于最先进的方法,验证了其在多模态RSCD中的有效性。
🔬 方法详解
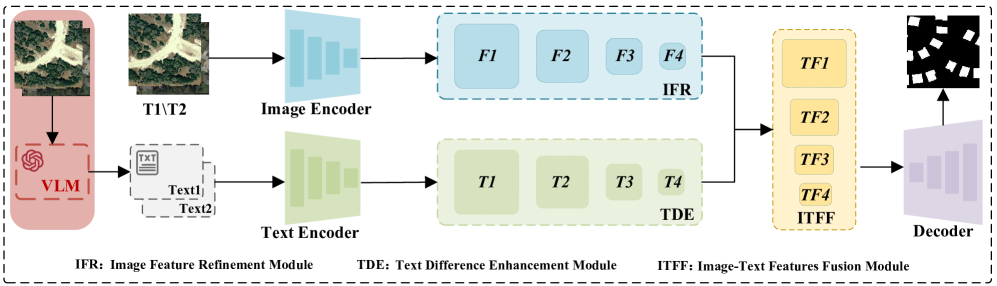
问题定义:遥感变化检测任务旨在识别不同时间点同一地理区域的变化。现有方法主要依赖图像信息,忽略了文本语义信息,导致在复杂环境(如光照变化、噪声干扰)下,特征表达能力不足,难以准确检测变化。
核心思路:MMChange的核心思路是融合图像和文本两种模态的信息,利用视觉语言模型(VLM)提取图像的语义描述,并通过文本差异增强模块(TDE)捕捉细粒度的语义变化。通过跨模态融合,弥补图像特征的语义局限性,提高变化检测的精度和鲁棒性。
技术框架:MMChange主要包含三个模块:图像特征精炼(IFR)模块、文本差异增强(TDE)模块和图像文本特征融合(ITFF)模块。首先,IFR模块用于突出图像中的关键区域并抑制噪声。然后,VLM用于生成双时相图像的文本描述,TDE模块用于捕捉文本描述中的语义变化。最后,ITFF模块用于融合图像和文本特征,得到最终的变化检测结果。
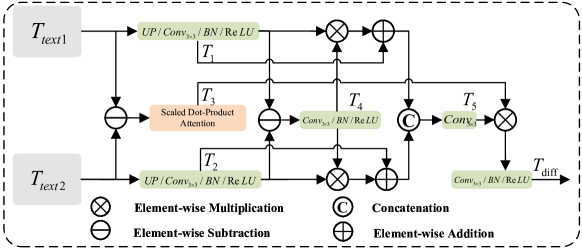
关键创新:MMChange的关键创新在于引入了文本模态信息,并设计了文本差异增强模块(TDE),能够有效地捕捉细粒度的语义变化。此外,图像文本特征融合模块(ITFF)实现了深度跨模态集成,充分利用了图像和文本两种模态的互补信息。
关键设计:IFR模块的具体结构未知,但其目标是突出关键区域和抑制噪声。VLM的选择和训练细节未知。TDE模块的设计目标是捕捉文本描述中的细微语义变化,具体实现方式未知。ITFF模块的具体融合策略和网络结构未知,但其目标是有效融合图像和文本特征。
🖼️ 关键图片

📊 实验亮点
MMChange在LEVIRCD、WHUCD和SYSUCD三个遥感变化检测数据集上进行了广泛的实验,结果表明,该方法在多个指标上均优于当前最先进的方法。具体的性能提升幅度未知,但论文强调了MMChange在不同数据集上的一致性优越性,验证了其有效性和泛化能力。
🎯 应用场景
该研究成果可应用于城市规划、灾害监测、资源管理、环境评估等领域。通过结合图像和文本信息,可以更准确地识别地表变化,为相关决策提供更可靠的依据。未来,该方法可以扩展到更多模态的数据融合,例如结合LiDAR数据、高光谱数据等,进一步提升变化检测的精度和应用范围。
📄 摘要(原文)
Although deep learning has advanced remote sensing change detection (RSCD), most methods rely solely on image modality, limiting feature representation, change pattern modeling, and generalization especially under illumination and noise disturbances. To address this, we propose MMChange, a multimodal RSCD method that combines image and text modalities to enhance accuracy and robustness. An Image Feature Refinement (IFR) module is introduced to highlight key regions and suppress environmental noise. To overcome the semantic limitations of image features, we employ a vision language model (VLM) to generate semantic descriptions of bitemporal images. A Textual Difference Enhancement (TDE) module then captures fine grained semantic shifts, guiding the model toward meaningful changes. To bridge the heterogeneity between modalities, we design an Image Text Feature Fusion (ITFF) module that enables deep cross modal integration. Extensive experiments on LEVIRCD, WHUCD, and SYSUCD demonstrate that MMChange consistently surpasses state of the art methods across multiple metrics, validating its effectiveness for multimodal RSCD. Code is available at: https://github.com/yikuizhai/MMChange.