ANTS: Adaptive Negative Textual Space Shaping for OOD Detection via Test-Time MLLM Understanding and Reasoning
作者: Wenjie Zhu, Yabin Zhang, Xin Jin, Wenjun Zeng, Lei Zhang
分类: cs.CV
发布日期: 2025-09-04 (更新: 2025-11-19)
💡 一句话要点
提出自适应负文本空间塑造方法以解决OOD检测问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布外检测 负标签 多模态大语言模型 自适应加权 图像理解 异常检测 计算机视觉
📋 核心要点
- 现有方法在构建准确的负空间时缺乏对OOD图像的理解,限制了其在近OOD检测中的能力。
- 本文提出通过多模态大语言模型的理解和推理能力,塑造自适应负文本空间,生成准确的负标签。
- 在ImageNet基准上,ANTS显著降低FPR95 3.1%,实现了新的最先进水平,且具备无训练和零样本的特性。
📝 摘要(中文)
引入负标签(NLs)在增强分布外(OOD)检测方面已被证明有效。然而,现有方法往往缺乏对OOD图像的理解,难以构建准确的负空间。此外,缺乏与ID标签语义相似的负标签限制了其在近OOD检测中的能力。为了解决这些问题,本文提出通过利用多模态大语言模型(MLLM)的理解和推理能力,塑造自适应负文本空间(ANTS)。具体而言,我们缓存可能是OOD样本的历史测试图像,并提示MLLM描述这些图像,生成准确表征OOD分布的负句子,从而增强远OOD检测。在近OOD设置中,我们缓存与历史测试图像视觉相似的ID类子集,并利用MLLM推理生成针对该子集的视觉相似负标签,有效减少假阴性并改善近OOD检测。通过设计自适应加权评分,我们的方法能够处理不同的OOD任务设置,具有高度适应性。在ImageNet基准上,ANTS显著降低了FPR95 3.1%,建立了新的最先进水平。此外,我们的方法是无训练和零样本的,具有高可扩展性。
🔬 方法详解
问题定义:本文旨在解决现有OOD检测方法在构建负空间时对OOD图像理解不足的问题,导致近OOD检测能力受限。
核心思路:通过利用多模态大语言模型(MLLM)的理解和推理能力,生成准确的负标签,从而改善OOD检测的效果。
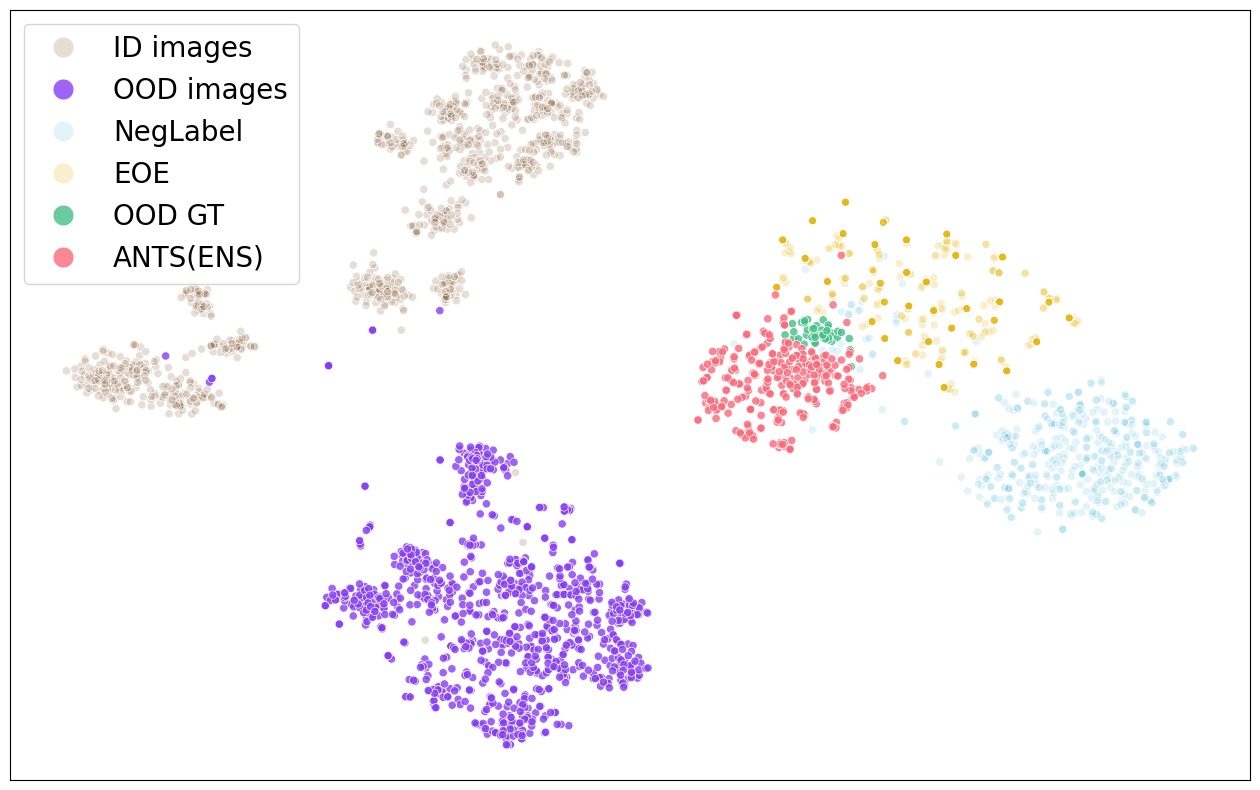
技术框架:整体架构包括两个主要阶段:首先缓存历史测试图像中可能的OOD样本,然后利用MLLM生成描述这些样本的负句子,最后根据视觉相似性生成针对近OOD的负标签。
关键创新:最重要的创新在于自适应负文本空间的构建,结合了远OOD和近OOD的检测需求,通过加权评分机制实现灵活适应。
关键设计:在设计中,采用了自适应加权评分来平衡不同类型的负文本空间,并确保生成的负标签与ID类视觉相似,减少假阴性。具体的损失函数和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
在ImageNet基准测试中,ANTS方法显著降低了FPR95 3.1%,相较于现有基线方法实现了新的最先进水平,展示了其在OOD检测中的有效性和优越性。
🎯 应用场景
该研究的潜在应用领域包括计算机视觉中的异常检测、自动驾驶中的安全监测以及医疗影像分析等。通过提高OOD检测的准确性,能够有效提升系统的鲁棒性和安全性,具有重要的实际价值和未来影响。
📄 摘要(原文)
The introduction of negative labels (NLs) has proven effective in enhancing Out-of-Distribution (OOD) detection. However, existing methods often lack an understanding of OOD images, making it difficult to construct an accurate negative space. Furthermore, the absence of negative labels semantically similar to ID labels constrains their capability in near-OOD detection. To address these issues, we propose shaping an Adaptive Negative Textual Space (ANTS) by leveraging the understanding and reasoning capabilities of multimodal large language models (MLLMs). Specifically, we cache images likely to be OOD samples from the historical test images and prompt the MLLM to describe these images, generating expressive negative sentences that precisely characterize the OOD distribution and enhance far-OOD detection. For the near-OOD setting, where OOD samples resemble the in-distribution (ID) subset, we cache the subset of ID classes that are visually similar to historical test images and then leverage MLLM reasoning to generate visually similar negative labels tailored to this subset, effectively reducing false negatives and improving near-OOD detection. To balance these two types of negative textual spaces, we design an adaptive weighted score that enables the method to handle different OOD task settings (near-OOD and far-OOD), making it highly adaptable in open environments. On the ImageNet benchmark, our ANTS significantly reduces the FPR95 by 3.1\%, establishing a new state-of-the-art. Furthermore, our method is training-free and zero-shot, enabling high scalability.