A Generative Foundation Model for Chest Radiography
作者: Yuanfeng Ji, Dan Lin, Xiyue Wang, Lu Zhang, Wenhui Zhou, Chongjian Ge, Ruihang Chu, Xiaoli Yang, Junhan Zhao, Junsong Chen, Xiangde Luo, Sen Yang, Jin Fang, Ping Luo, Ruijiang Li
分类: cs.CV
发布日期: 2025-09-04
💡 一句话要点
ChexGen:用于胸部X光片的生成式基础模型,提升医疗AI性能与公平性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式模型 胸部X光片 数据增强 扩散模型 医学图像 公平性 视觉-语言模型
📋 核心要点
- 医学图像数据标注成本高昂且多样性不足,限制了可靠AI模型的发展。
- ChexGen通过统一的框架,实现了文本、掩码和边界框引导的胸部X光片合成。
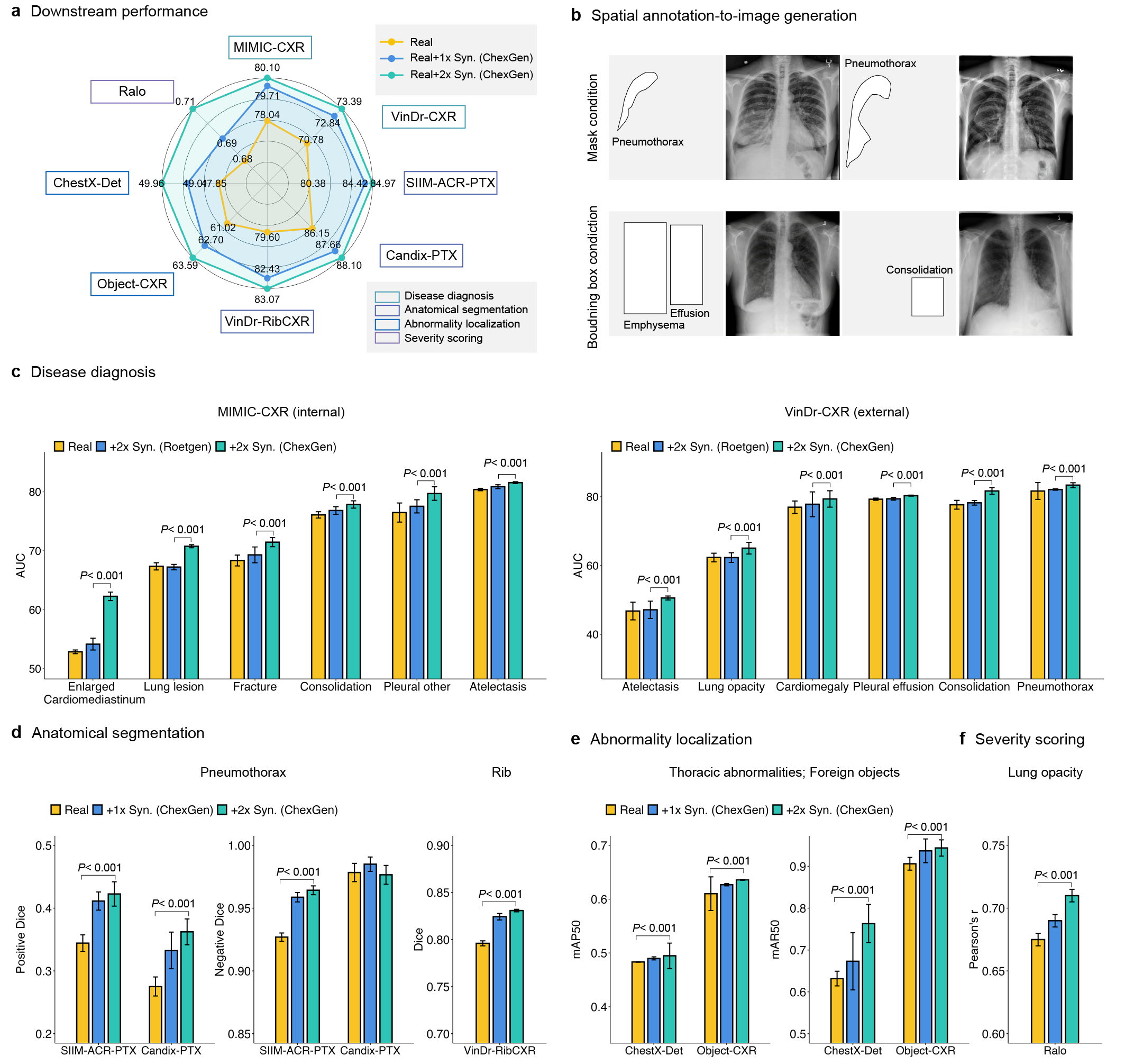
- ChexGen在数据增强和预训练中表现出色,提升了疾病分类、检测和分割的性能,并改善了模型公平性。
📝 摘要(中文)
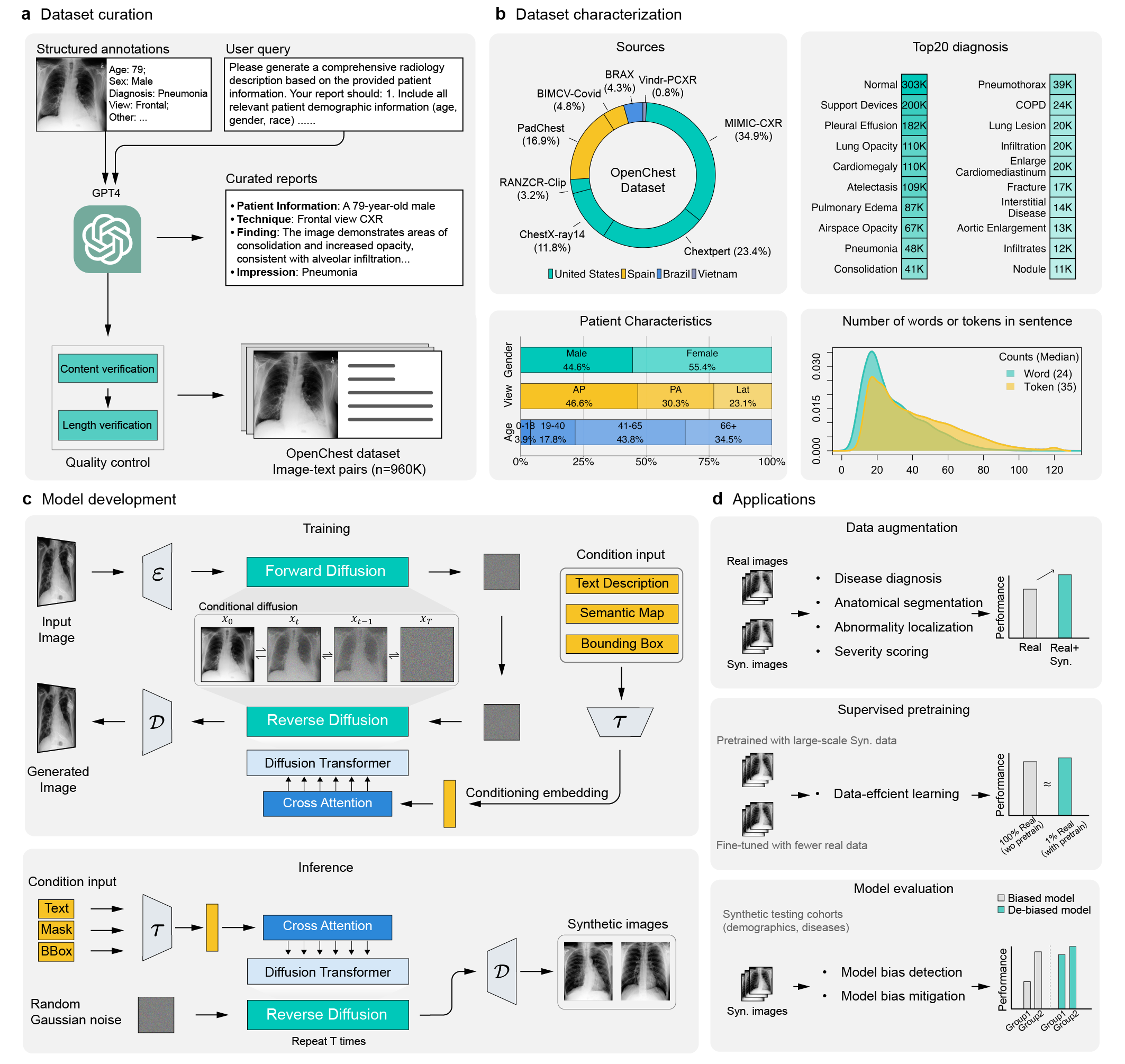
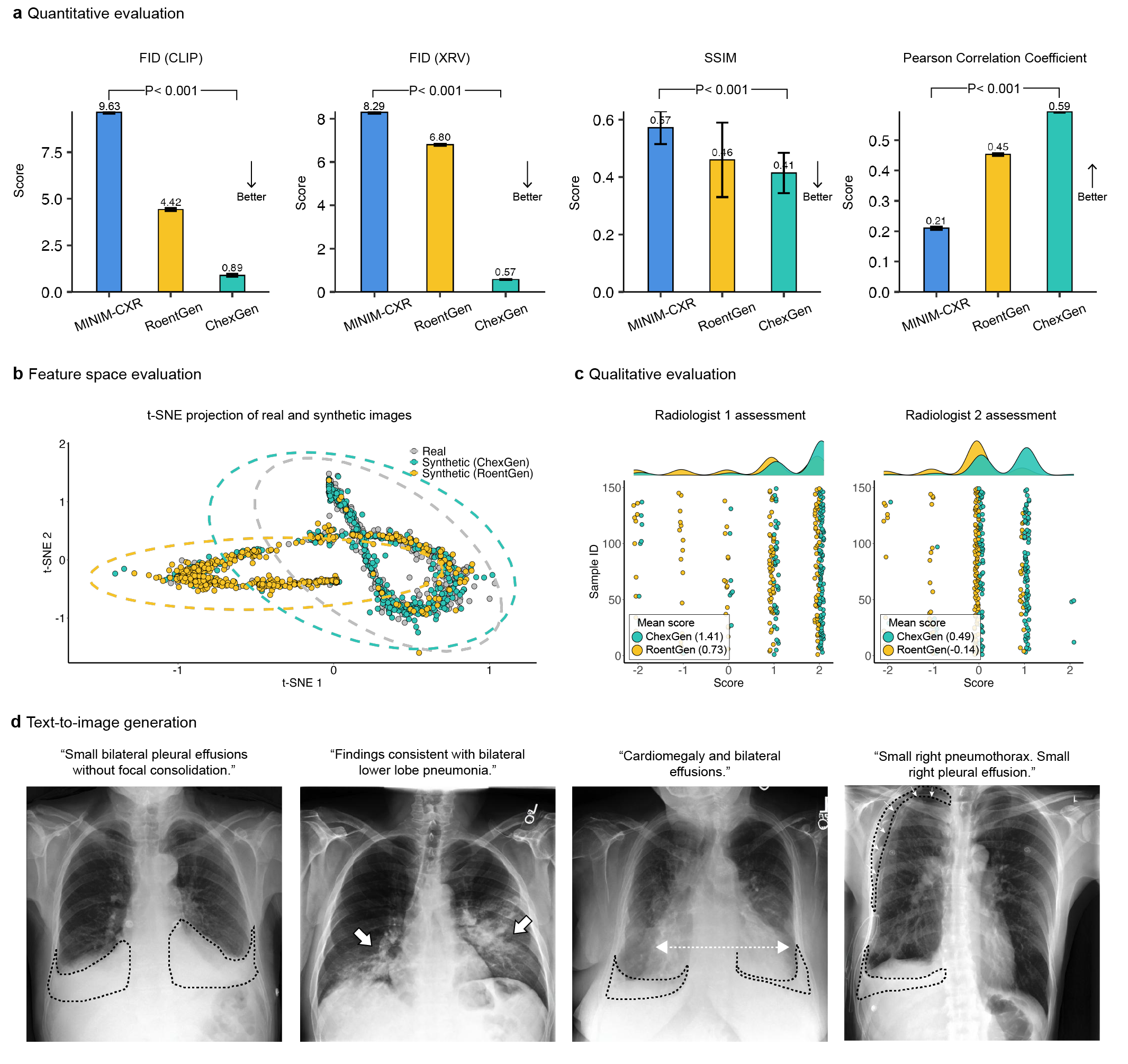
本文提出了ChexGen,一个生成式视觉-语言基础模型,用于胸部X光片的文本、掩码和边界框引导合成,旨在解决医学图像数据匮乏的问题。ChexGen基于潜在扩散Transformer架构,并使用包含96万张X光片-报告对的大规模数据集进行预训练。实验表明,ChexGen能够准确合成X光片,并通过专家评估和定量指标验证。ChexGen可用于训练数据增强和监督预训练,从而在使用少量训练数据的情况下,提高疾病分类、检测和分割任务的性能。此外,该模型能够创建多样化的患者队列,通过检测和减轻人口统计偏差来增强模型的公平性。这项研究表明了生成式基础模型在构建更准确、数据高效和公平的医疗AI系统中的变革性作用。
🔬 方法详解
问题定义:医学领域中,高质量、多样化的标注图像数据稀缺,严重制约了深度学习模型的发展。现有方法难以有效利用有限的数据,且容易受到数据偏差的影响,导致模型泛化能力和公平性不足。
核心思路:ChexGen的核心在于利用生成式模型,特别是扩散模型,学习胸部X光片的潜在表示,并结合文本描述、掩码和边界框等信息,生成高质量、多样化的合成图像。通过合成数据增强训练集,可以有效缓解数据稀缺问题,并减轻数据偏差的影响。
技术框架:ChexGen基于潜在扩散Transformer架构。整体流程包括:1)使用大规模胸部X光片-报告对数据集进行预训练,学习图像和文本的联合表示;2)利用文本描述、掩码和边界框等条件信息,引导扩散模型生成X光片;3)将合成的X光片用于数据增强、预训练等下游任务,提升模型性能。
关键创新:ChexGen的关键创新在于将生成式模型应用于胸部X光片合成,并结合文本、掩码和边界框等多种条件信息,实现对生成过程的精细控制。此外,ChexGen使用了大规模数据集进行预训练,使其能够学习到更丰富的医学知识。
关键设计:ChexGen采用潜在扩散模型,在潜在空间中进行图像生成,降低计算复杂度。Transformer架构用于建模图像和文本之间的关系。损失函数包括扩散模型的重建损失和对抗损失,以保证生成图像的质量和真实性。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
ChexGen通过数据增强和预训练,在疾病分类、检测和分割任务中取得了显著的性能提升。具体性能数据和对比基线未在摘要中给出,属于未知信息。此外,ChexGen能够检测和减轻人口统计偏差,增强模型的公平性,这在医疗AI领域具有重要意义。
🎯 应用场景
ChexGen具有广泛的应用前景,包括:1)数据增强,提升医学图像分析模型的性能;2)生成罕见病例,辅助医生进行诊断;3)创建多样化的患者队列,评估和改善模型的公平性;4)用于医学教育和培训,提供逼真的模拟图像。该研究有望推动医疗AI的发展,提高诊断准确性和效率,并促进医疗资源的公平分配。
📄 摘要(原文)
The scarcity of well-annotated diverse medical images is a major hurdle for developing reliable AI models in healthcare. Substantial technical advances have been made in generative foundation models for natural images. Here we develop `ChexGen', a generative vision-language foundation model that introduces a unified framework for text-, mask-, and bounding box-guided synthesis of chest radiographs. Built upon the latent diffusion transformer architecture, ChexGen was pretrained on the largest curated chest X-ray dataset to date, consisting of 960,000 radiograph-report pairs. ChexGen achieves accurate synthesis of radiographs through expert evaluations and quantitative metrics. We demonstrate the utility of ChexGen for training data augmentation and supervised pretraining, which led to performance improvements across disease classification, detection, and segmentation tasks using a small fraction of training data. Further, our model enables the creation of diverse patient cohorts that enhance model fairness by detecting and mitigating demographic biases. Our study supports the transformative role of generative foundation models in building more accurate, data-efficient, and equitable medical AI systems.