Human Motion Video Generation: A Survey
作者: Haiwei Xue, Xiangyang Luo, Zhanghao Hu, Xin Zhang, Xunzhi Xiang, Yuqin Dai, Jianzhuang Liu, Zhensong Zhang, Minglei Li, Jian Yang, Fei Ma, Zhiyong Wu, Changpeng Yang, Zonghong Dai, Fei Richard Yu
分类: cs.CV, cs.MM
发布日期: 2025-09-04
备注: Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence 2025
DOI: 10.1109/TPAMI.2025.3594034
🔗 代码/项目: GITHUB
💡 一句话要点
全面综述人体运动视频生成技术,涵盖关键阶段与未来趋势。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体运动视频生成 数字人 运动规划 视频生成 大型语言模型 视觉 文本 音频
📋 核心要点
- 现有的人体运动视频生成综述侧重于单一方法,缺乏对完整生成流程的系统性分析。
- 该综述深入分析了人体运动视频生成的五个关键阶段,并探讨了大型语言模型在该领域的应用潜力。
- 论文回顾了视觉、文本和音频三种模态下的最新技术进展,并总结了该领域的重要里程碑。
📝 摘要(中文)
人体运动视频生成因其广泛的应用而备受关注,例如逼真的歌唱头部或无缝地随音乐跳舞的动态化身。然而,现有的综述主要集中于单个方法,缺乏对整个生成过程的全面概述。本文弥补了这一空白,对人体运动视频生成进行了深入的综述,涵盖了十多个子任务,并详细介绍了生成过程的五个关键阶段:输入、运动规划、运动视频生成、细化和输出。值得注意的是,这是第一篇讨论大型语言模型在增强人体运动视频生成方面潜力的综述。我们的综述回顾了视觉、文本和音频三种主要模态下人体运动视频生成的最新进展和技术趋势。通过涵盖200多篇论文,我们对该领域进行了全面的概述,并重点介绍了推动重大技术突破的里程碑式工作。本综述旨在揭示人体运动视频生成的前景,并为推进数字人的全面应用提供有价值的资源。
🔬 方法详解
问题定义:人体运动视频生成旨在创建逼真且连贯的人体运动视频,但现有方法在生成过程的各个阶段都存在挑战。例如,运动规划可能不够自然,生成的视频可能存在伪影,并且难以与文本或音频等其他模态精确对齐。此外,如何利用大型语言模型来提升生成效果也是一个待解决的问题。
核心思路:该综述的核心思路是将人体运动视频生成过程分解为五个关键阶段:输入、运动规划、运动视频生成、细化和输出。通过对每个阶段的现有方法进行详细分析,可以更清晰地了解该领域的进展和挑战。此外,探讨大型语言模型在该领域的应用潜力,为未来的研究方向提供了新的思路。
技术框架:该综述没有提出新的技术框架,而是对现有的人体运动视频生成方法进行了分类和总结。它涵盖了视觉、文本和音频三种模态下的方法,并详细介绍了每个阶段的关键技术。例如,在运动规划阶段,综述讨论了基于物理的方法、基于学习的方法等。在运动视频生成阶段,综述讨论了基于GAN的方法、基于扩散模型的方法等。
关键创新:该综述的主要创新在于其全面性和系统性。它是第一篇对人体运动视频生成过程进行全面概述的综述,涵盖了十多个子任务和五个关键阶段。此外,该综述还首次探讨了大型语言模型在该领域的应用潜力,为未来的研究方向提供了新的思路。
关键设计:该综述没有涉及具体的技术细节,而是对现有方法的关键设计进行了总结。例如,在基于GAN的方法中,综述讨论了不同的生成器和判别器结构、损失函数等。在基于扩散模型的方法中,综述讨论了不同的噪声添加策略、采样方法等。
🖼️ 关键图片
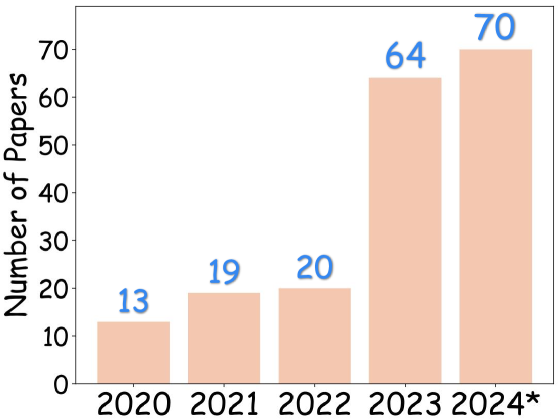
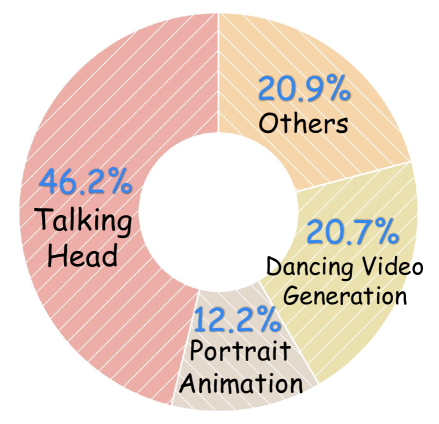
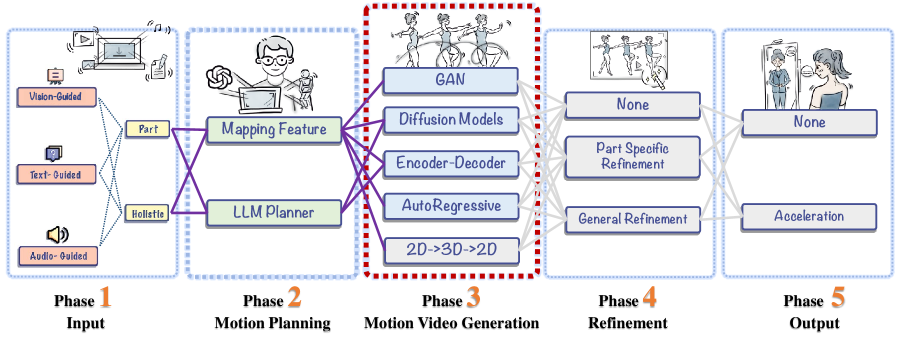
📊 实验亮点
该综述涵盖了200多篇相关论文,对人体运动视频生成领域的最新进展进行了全面回顾。它总结了现有方法的优缺点,并指出了未来的研究方向。特别值得关注的是,该综述首次探讨了大型语言模型在该领域的应用潜力,为未来的研究提供了新的思路。
🎯 应用场景
人体运动视频生成技术具有广泛的应用前景,包括创建逼真的虚拟化身、开发沉浸式游戏和娱乐体验、辅助运动分析和康复训练、以及生成用于教育和培训的视频内容。该技术还可以用于创建个性化的数字内容,例如根据用户的喜好生成定制的舞蹈视频或健身教程。
📄 摘要(原文)
Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.