Focus Through Motion: RGB-Event Collaborative Token Sparsification for Efficient Object Detection
作者: Nan Yang, Yang Wang, Zhanwen Liu, Yuchao Dai, Yang Liu, Xiangmo Zhao
分类: cs.CV
发布日期: 2025-09-04
🔗 代码/项目: GITHUB
💡 一句话要点
提出FocusMamba,通过RGB-Event协同Token稀疏化实现高效目标检测
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RGB-Event 目标检测 Token稀疏化 多模态融合 事件相机 自适应稀疏化 计算效率
📋 核心要点
- 现有RGB-Event目标检测方法对低信息区域统一处理,造成计算冗余和性能瓶颈。
- FocusMamba通过事件引导的多模态稀疏化(EGMS)和跨模态聚焦融合(CMFF)实现自适应特征提取。
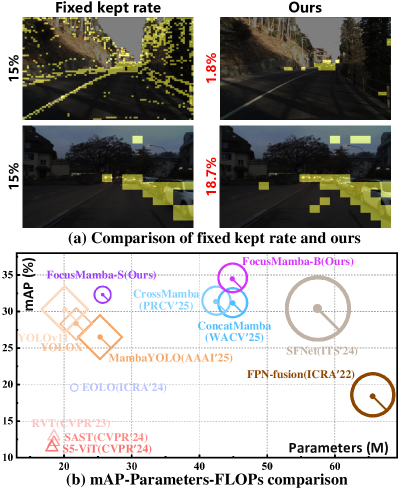
- 实验结果表明,FocusMamba在DSEC-Det和PKU-DAVIS-SOD数据集上实现了精度和效率的双重提升。
📝 摘要(中文)
现有的RGB-Event检测方法在特征提取和融合过程中,对两种模态中的低信息区域(图像中的背景和事件数据中的非事件区域)进行统一处理,导致计算成本高昂且性能欠佳。为了减少特征提取过程中的计算冗余,研究人员分别针对图像和事件模态提出了token稀疏化方法。然而,这些方法采用固定数量或阈值进行token选择,阻碍了信息量丰富的token的保留,尤其是在处理复杂度不同的样本时。为了在精度和效率之间取得更好的平衡,我们提出了FocusMamba,它执行多模态特征的自适应协同稀疏化,并有效地整合互补信息。具体来说,我们设计了一种事件引导的多模态稀疏化(EGMS)策略,通过利用事件相机感知的场景内容变化来识别并自适应地丢弃每种模态内的低信息区域。基于稀疏化结果,我们提出了一种跨模态聚焦融合(CMFF)模块,以有效地捕获和整合来自两种模态的互补特征。在DSEC-Det和PKU-DAVIS-SOD数据集上的实验表明,与现有方法相比,该方法在准确性和效率方面均表现出优异的性能。
🔬 方法详解
问题定义:现有的RGB-Event目标检测方法在处理图像和事件数据时,通常会平等地对待所有区域,即使是背景区域或者没有事件发生的区域。这种均匀处理方式导致了大量的计算冗余,因为在这些低信息区域上的计算并没有带来显著的性能提升。此外,现有的token稀疏化方法通常采用固定的阈值或数量来选择token,无法根据输入数据的复杂程度进行自适应调整,导致重要信息的丢失或计算资源的浪费。
核心思路:FocusMamba的核心思路是利用事件相机对场景变化的敏感性,引导图像和事件数据的特征稀疏化过程。通过事件数据来判断哪些区域包含重要的信息,从而自适应地保留这些区域的特征,并丢弃低信息区域的特征。这种自适应的稀疏化策略可以有效地减少计算量,同时保证关键信息的完整性。此外,FocusMamba还设计了一个跨模态聚焦融合模块,用于有效地整合来自RGB图像和事件数据的互补信息。
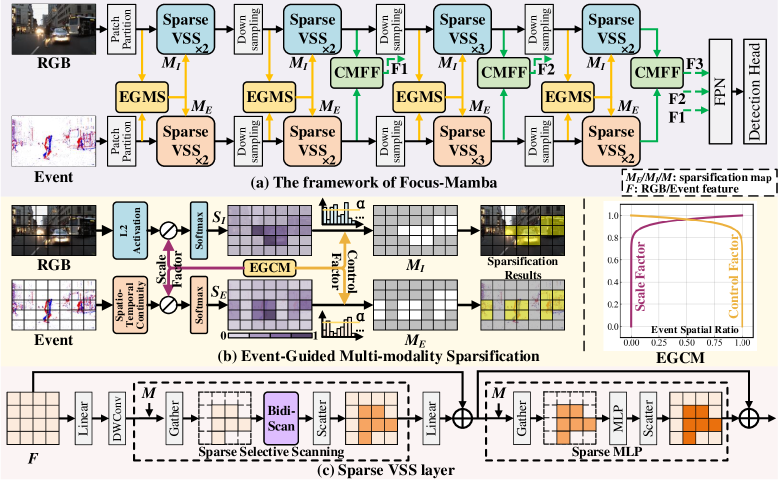
技术框架:FocusMamba的整体框架主要包含两个核心模块:事件引导的多模态稀疏化(EGMS)和跨模态聚焦融合(CMFF)。首先,EGMS模块利用事件数据来指导图像和事件数据的特征稀疏化,自适应地丢弃低信息区域的token。然后,CMFF模块将稀疏化后的图像和事件特征进行融合,提取互补信息,用于最终的目标检测任务。整个流程旨在提高计算效率,同时保持或提升检测精度。
关键创新:FocusMamba的关键创新在于其自适应的协同稀疏化策略。与现有的token稀疏化方法不同,FocusMamba不是采用固定的阈值或数量来选择token,而是根据事件数据来动态地调整稀疏化的程度。这种自适应的策略可以更好地适应不同场景和不同复杂度的输入数据,从而在精度和效率之间取得更好的平衡。此外,跨模态聚焦融合模块的设计也能够更有效地利用RGB图像和事件数据的互补信息。
关键设计:EGMS模块的关键设计在于如何有效地利用事件数据来指导特征稀疏化。具体来说,可以通过分析事件数据的密度和分布来判断哪些区域包含重要的信息。例如,事件密度高的区域通常对应于场景中发生变化的区域,这些区域的特征应该被保留。CMFF模块的关键设计在于如何有效地融合来自RGB图像和事件数据的特征。可以使用注意力机制来学习不同模态特征之间的权重,从而更好地利用互补信息。具体的损失函数和网络结构的选择取决于具体的应用场景和数据集。
🖼️ 关键图片

📊 实验亮点
FocusMamba在DSEC-Det和PKU-DAVIS-SOD数据集上取得了显著的性能提升。在DSEC-Det数据集上,FocusMamba在保持较高检测精度的同时,显著降低了计算量。与现有方法相比,FocusMamba在PKU-DAVIS-SOD数据集上的目标分割精度也得到了显著提升,证明了其在处理复杂场景时的有效性。
🎯 应用场景
FocusMamba在自动驾驶、机器人导航、视频监控等领域具有广泛的应用前景。在这些场景中,快速准确地检测目标至关重要。通过降低计算成本和提高检测效率,FocusMamba可以帮助这些系统更好地适应资源受限的环境,并提高实时性。此外,该方法还可以应用于其他多模态融合任务,例如图像描述生成和视频理解。
📄 摘要(原文)
Existing RGB-Event detection methods process the low-information regions of both modalities (background in images and non-event regions in event data) uniformly during feature extraction and fusion, resulting in high computational costs and suboptimal performance. To mitigate the computational redundancy during feature extraction, researchers have respectively proposed token sparsification methods for the image and event modalities. However, these methods employ a fixed number or threshold for token selection, hindering the retention of informative tokens for samples with varying complexity. To achieve a better balance between accuracy and efficiency, we propose FocusMamba, which performs adaptive collaborative sparsification of multimodal features and efficiently integrates complementary information. Specifically, an Event-Guided Multimodal Sparsification (EGMS) strategy is designed to identify and adaptively discard low-information regions within each modality by leveraging scene content changes perceived by the event camera. Based on the sparsification results, a Cross-Modality Focus Fusion (CMFF) module is proposed to effectively capture and integrate complementary features from both modalities. Experiments on the DSEC-Det and PKU-DAVIS-SOD datasets demonstrate that the proposed method achieves superior performance in both accuracy and efficiency compared to existing methods. The code will be available at https://github.com/Zizzzzzzz/FocusMamba.