Human Preference-Aligned Concept Customization Benchmark via Decomposed Evaluation
作者: Reina Ishikawa, Ryo Fujii, Hideo Saito, Ryo Hachiuma
分类: cs.CV
发布日期: 2025-09-03
备注: Accepted to ICCV Workshop 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出D-GPTScore,用于对齐人类偏好的概念定制生成图像评估。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 概念定制 图像生成 多模态大语言模型 人类偏好对齐 评估指标
📋 核心要点
- 现有概念定制评估指标与人类直觉存在偏差,无法准确衡量生成图像的质量和概念间的交互。
- D-GPTScore将评估标准分解为更细粒度的方面,利用多模态大语言模型进行更精准的评估。
- CC-AlignBench基准数据集包含单概念和多概念任务,为概念定制评估提供了全面的测试平台。
📝 摘要(中文)
概念定制的评估极具挑战性,因为它需要全面评估生成提示和概念图像的保真度。此外,评估多个概念比评估单个概念困难得多,因为它不仅需要对每个单独的概念进行详细评估,还需要对概念之间的交互进行评估。虽然人类可以直观地评估生成的图像,但现有的指标通常提供过于狭隘或过于泛化的评估,导致与人类偏好不一致。为了解决这个问题,我们提出了一种新的人类对齐评估方法D-GPTScore,该方法将评估标准分解为更精细的方面,并结合使用多模态大型语言模型(MLLM)进行方面评估。此外,我们发布了人类偏好对齐的概念定制基准(CC-AlignBench),这是一个包含单概念和多概念任务的基准数据集,可以在广泛的难度范围内进行阶段性评估——从个人行为到多人互动。我们的方法在这个基准上显著优于现有方法,表现出与人类偏好更高的相关性。这项工作为评估概念定制建立了一个新的标准,并突出了未来研究的关键挑战。基准和相关材料可在https://github.com/ReinaIshikawa/D-GPTScore获得。
🔬 方法详解
问题定义:概念定制生成图像的评估是一个复杂的问题,尤其是在涉及多个概念时。现有的评估指标要么过于简单,无法捕捉概念之间的复杂交互,要么过于宽泛,无法准确反映人类对图像质量的偏好。因此,如何设计一个与人类偏好对齐的、能够细粒度评估概念定制效果的指标,是本文要解决的核心问题。
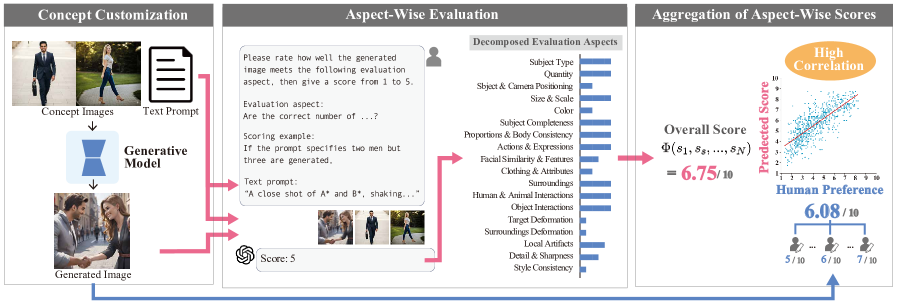
核心思路:本文的核心思路是将概念定制的评估过程分解为多个更小的、更易于理解的方面,例如概念的保真度、图像的真实性、概念之间的关系等。然后,利用多模态大型语言模型(MLLM)对每个方面进行评估,最后将各个方面的评估结果综合起来,得到一个整体的评估分数。这种分解评估的方法可以更准确地反映人类对图像质量的判断。
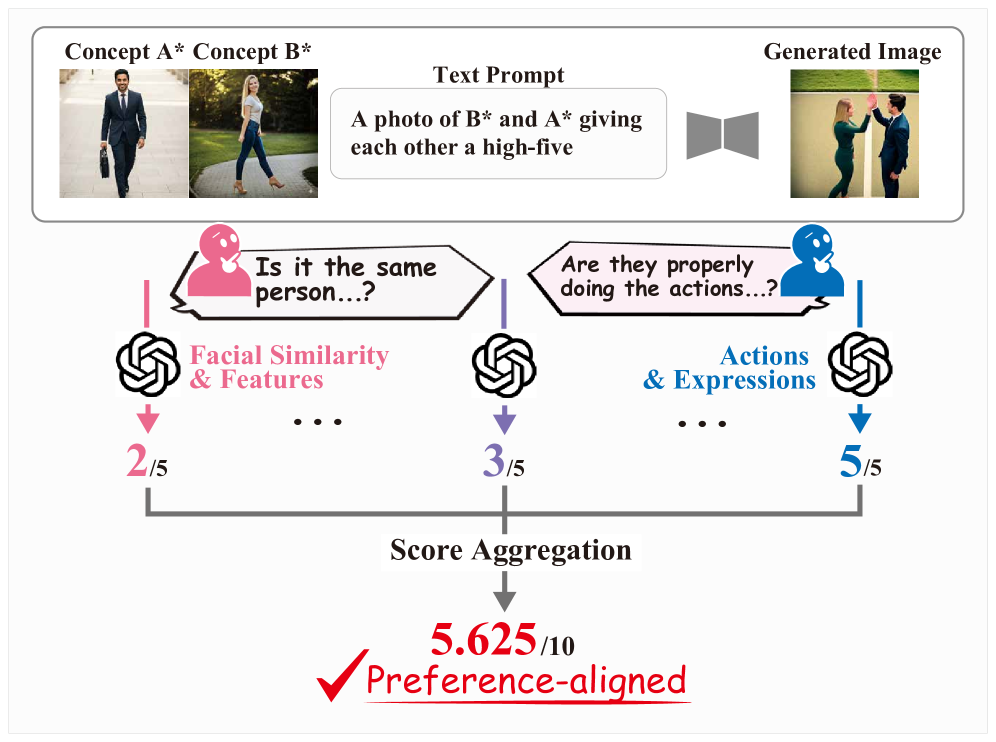
技术框架:D-GPTScore的整体框架包括以下几个主要步骤:1) 将评估任务分解为多个方面;2) 使用MLLM对每个方面进行评估,MLLM接收生成图像和相关文本提示作为输入,输出对该方面质量的评分;3) 将各个方面的评分进行加权平均,得到最终的D-GPTScore。CC-AlignBench数据集包含单概念和多概念任务,用于评估D-GPTScore的性能。
关键创新:D-GPTScore的关键创新在于其分解评估的思想,以及利用MLLM进行方面评估的方法。与传统的整体评估方法相比,分解评估可以更准确地捕捉概念定制的细微差别。利用MLLM进行评估,可以更好地模拟人类的判断过程,从而提高评估结果与人类偏好的一致性。
关键设计:D-GPTScore的关键设计包括:1) 评估方面的选择,需要根据具体的概念定制任务进行调整;2) MLLM的选择和训练,需要选择具有较强多模态理解能力的MLLM,并使用高质量的数据进行训练;3) 评分的加权方式,需要根据各个方面的重要性进行调整。论文中没有明确给出具体的参数设置、损失函数、网络结构等技术细节,这些可能需要根据实际应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
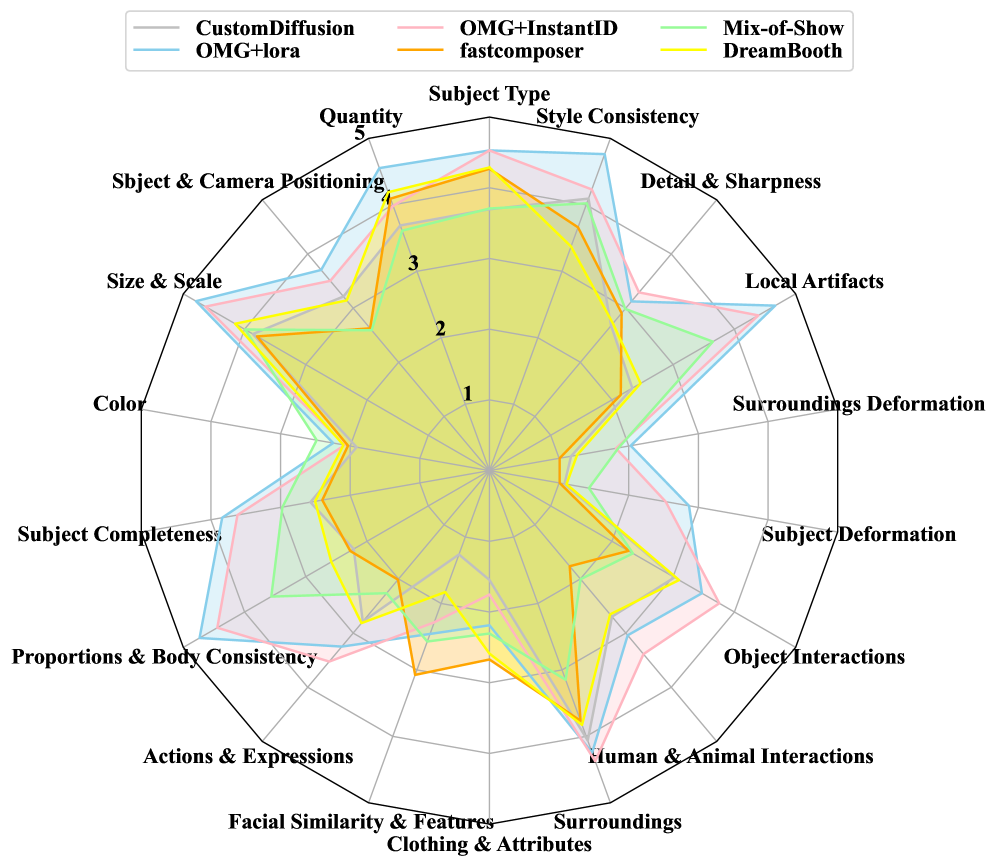
D-GPTScore在CC-AlignBench基准测试中显著优于现有方法,与人类偏好具有更高的相关性。具体性能数据和对比基线在论文中未明确给出,但摘要中强调了“显著优于现有方法”,表明D-GPTScore在概念定制评估方面取得了重要进展。
🎯 应用场景
该研究成果可应用于各种生成式AI应用,例如图像编辑、虚拟现实内容创作、游戏开发等。通过更准确地评估生成图像的质量,可以提升用户体验,并促进相关技术的发展。此外,CC-AlignBench数据集可以作为未来研究的基准,推动概念定制技术的进步。
📄 摘要(原文)
Evaluating concept customization is challenging, as it requires a comprehensive assessment of fidelity to generative prompts and concept images. Moreover, evaluating multiple concepts is considerably more difficult than evaluating a single concept, as it demands detailed assessment not only for each individual concept but also for the interactions among concepts. While humans can intuitively assess generated images, existing metrics often provide either overly narrow or overly generalized evaluations, resulting in misalignment with human preference. To address this, we propose Decomposed GPT Score (D-GPTScore), a novel human-aligned evaluation method that decomposes evaluation criteria into finer aspects and incorporates aspect-wise assessments using Multimodal Large Language Model (MLLM). Additionally, we release Human Preference-Aligned Concept Customization Benchmark (CC-AlignBench), a benchmark dataset containing both single- and multi-concept tasks, enabling stage-wise evaluation across a wide difficulty range -- from individual actions to multi-person interactions. Our method significantly outperforms existing approaches on this benchmark, exhibiting higher correlation with human preferences. This work establishes a new standard for evaluating concept customization and highlights key challenges for future research. The benchmark and associated materials are available at https://github.com/ReinaIshikawa/D-GPTScore.