Mitigating Multimodal Hallucinations via Gradient-based Self-Reflection
作者: Shan Wang, Maying Shen, Nadine Chang, Chuong Nguyen, Hongdong Li, Jose M. Alvarez
分类: cs.CV, cs.CL
发布日期: 2025-09-03 (更新: 2025-11-13)
💡 一句话要点
提出基于梯度的自反机制以缓解多模态幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 幻觉现象 梯度分析 视觉基础 约束解码 大型语言模型 模型优化
📋 核心要点
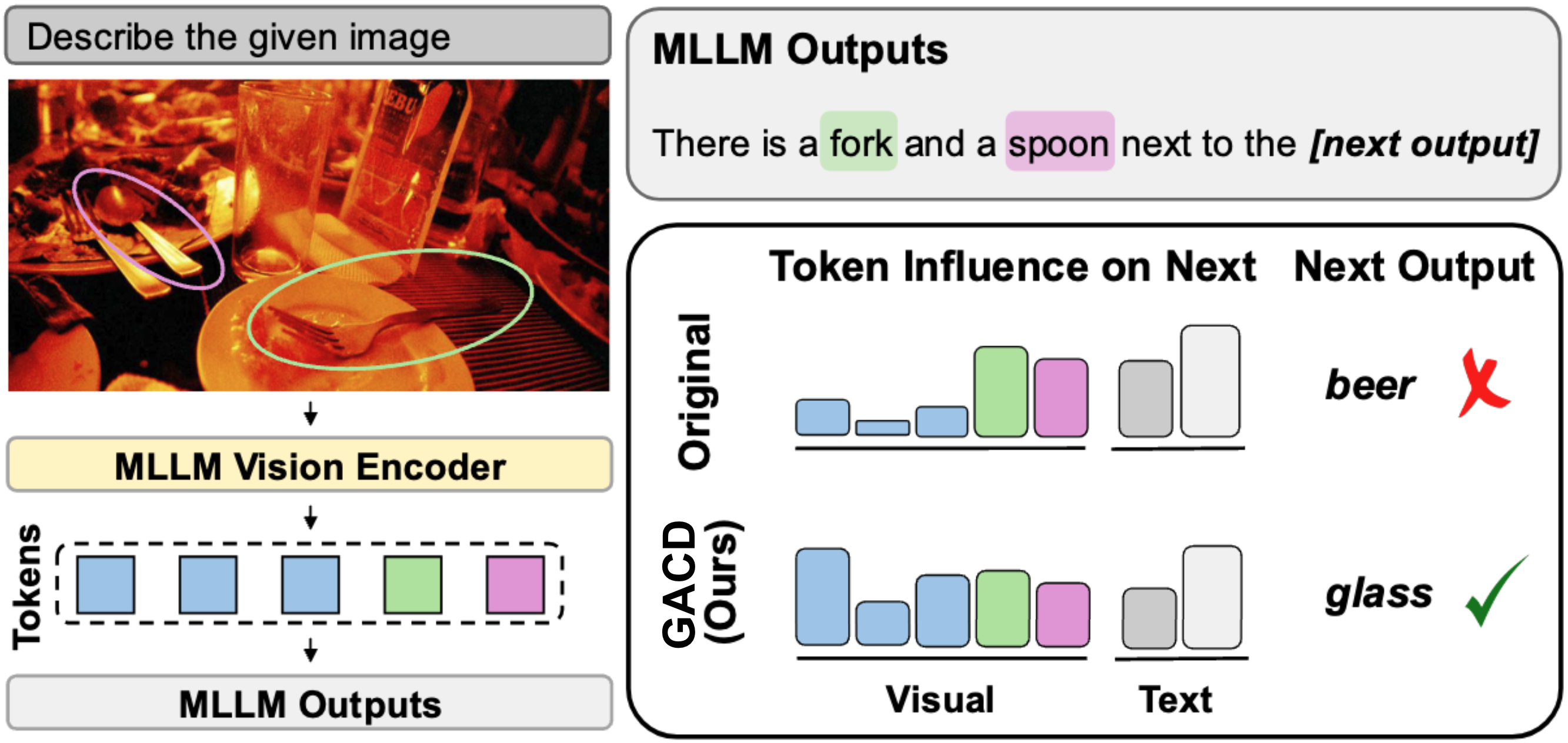
- 现有多模态大型语言模型在生成输出时容易出现幻觉,主要由于对文本和视觉输入的过度依赖。
- 本文提出的GACD方法通过梯度分析来估计偏差,抑制虚假视觉特征并增强视觉信息的贡献。
- 实验结果显示,GACD在多个基准测试中显著减少了幻觉现象,提高了模型的视觉基础能力。
📝 摘要(中文)
多模态大型语言模型在多种任务中表现出色,但仍然容易出现幻觉现象,即输出未能与视觉输入相结合。该问题主要源于文本-视觉偏差和共现偏差。本文提出了一种名为梯度影响感知约束解码(GACD)的方法,旨在解决这两种偏差,而无需辅助模型,并且可以直接应用于现有模型而无需微调。GACD通过使用一阶泰勒梯度来估计偏差,从而理解单个标记和视觉特征对当前输出的贡献。基于此分析,GACD通过抑制与输出对象相关的虚假视觉特征和重新平衡跨模态贡献来减轻幻觉。实验结果表明,GACD有效降低了幻觉现象,并改善了多模态大型语言模型输出的视觉基础。
🔬 方法详解
问题定义:本文旨在解决多模态大型语言模型在生成过程中出现的幻觉问题,现有方法往往依赖于文本提示和先前输出,导致输出与视觉输入不一致。
核心思路:GACD方法通过梯度分析来估计文本和视觉特征对输出的影响,从而抑制虚假视觉特征并增强视觉信息的相对贡献,解决了现有方法的不足。
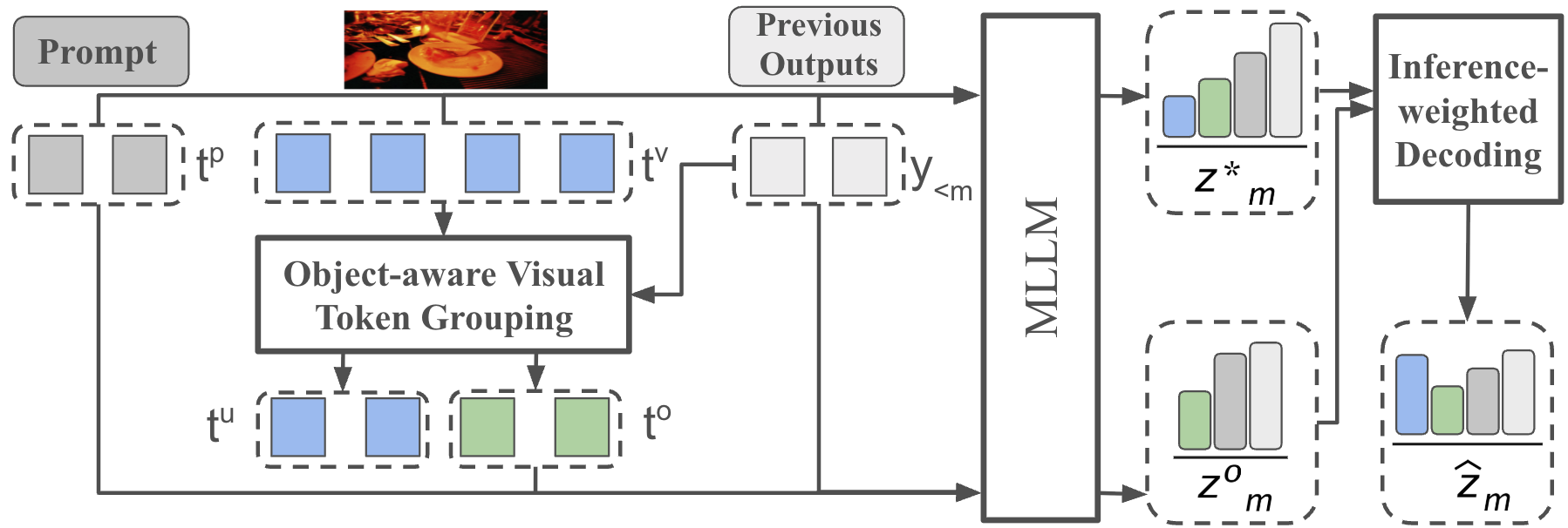
技术框架:GACD的整体架构包括偏差估计模块和约束解码模块。偏差估计模块使用一阶泰勒梯度分析特征贡献,约束解码模块则根据分析结果调整输出。
关键创新:GACD的主要创新在于其无须辅助模型的设计,直接在现有模型上应用,并通过梯度分析实现对偏差的有效控制,显著区别于传统方法。
关键设计:在GACD中,采用了一阶泰勒梯度来评估特征贡献,设计了特定的损失函数以抑制虚假特征,并通过调整解码过程中的权重来实现跨模态的平衡。具体的参数设置和网络结构细节在实验部分进行了详细描述。
🖼️ 关键图片
📊 实验亮点
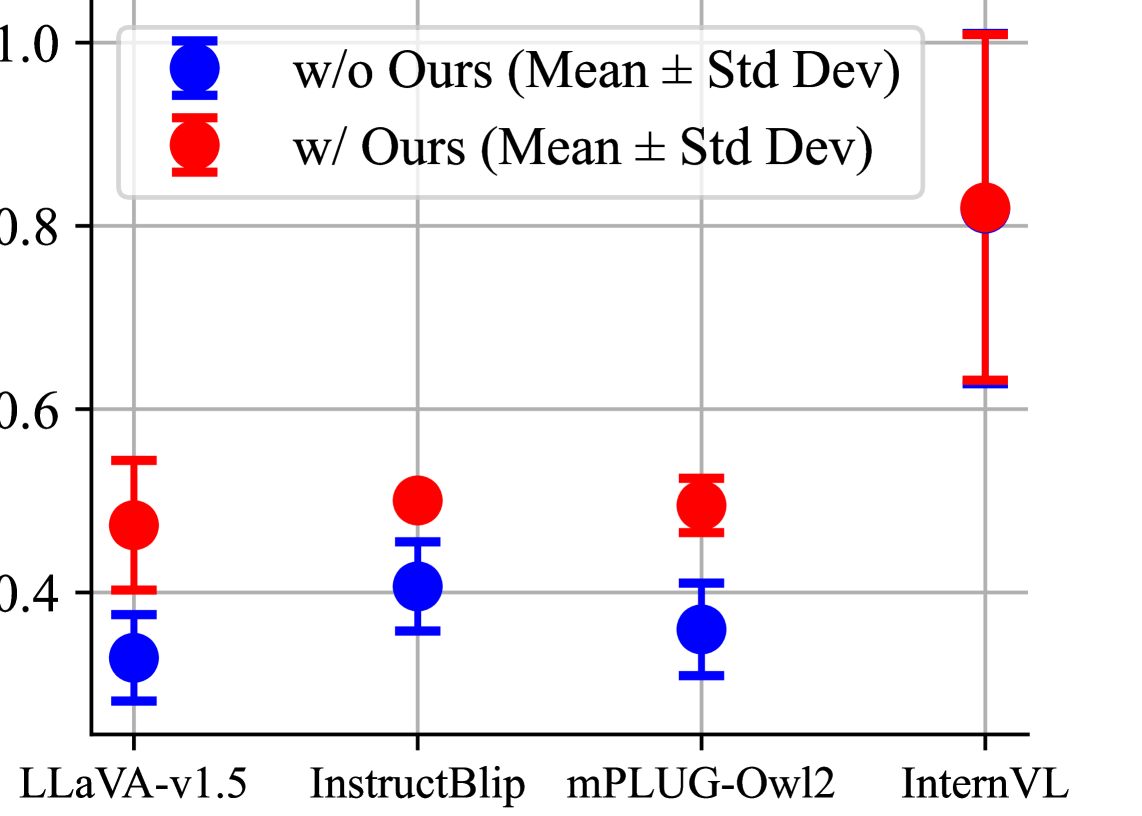
实验结果表明,GACD在多个基准测试中有效降低了幻觉现象,具体表现为在某些任务上相较于基线模型减少了约20%的幻觉输出,显著提升了多模态大型语言模型的视觉基础能力。
🎯 应用场景
该研究的潜在应用领域包括多模态内容生成、智能助手和自动驾驶等场景。通过改善模型的视觉基础能力,GACD可以提升这些系统在复杂环境中的决策和生成能力,具有重要的实际价值和未来影响。
📄 摘要(原文)
Multimodal large language models achieve strong performance across diverse tasks but remain prone to hallucinations, where outputs are not grounded in visual inputs. This issue can be attributed to two main biases: text-visual bias, the overreliance on prompts and prior outputs, and co-occurrence bias, spurious correlations between frequently paired objects. We propose Gradient-based Influence-Aware Constrained Decoding (GACD), an inference-based method, that addresses both biases without auxiliary models, and is readily applicable to existing models without finetuning. The core of our approach is bias estimation, which uses first-order Taylor gradients to understand the contribution of individual tokens-visual features and text tokens-to the current output. Based on this analysis, GACD mitigates hallucinations through two components: (1) suppressing spurious visual features correlated with the output objects, and (2) rebalancing cross-modal contributions by strengthening visual features relative to text. Experiments across multiple benchmarks demonstrate that GACD effectively reduces hallucinations and improves the visual grounding of MLLM outputs.