Veritas: Generalizable Deepfake Detection via Pattern-Aware Reasoning
作者: Hao Tan, Jun Lan, Zichang Tan, Ajian Liu, Chuanbiao Song, Senyuan Shi, Huijia Zhu, Weiqiang Wang, Jun Wan, Zhen Lei
分类: cs.CV, cs.AI
发布日期: 2025-08-28
备注: Project: https://github.com/EricTan7/Veritas
💡 一句话要点
提出Veritas,通过模式感知推理实现深度伪造检测的泛化性,并使用HydraFake数据集进行评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度伪造检测 多模态学习 大型语言模型 模式感知推理 泛化能力
📋 核心要点
- 现有深度伪造检测方法在实际应用中泛化性不足,因为学术数据集与真实场景存在较大差距,缺乏多样性和高质量的伪造样本。
- Veritas通过引入模式感知推理,模拟人类取证过程中的规划和自我反思,提升模型对未知伪造模式的识别能力。
- 在HydraFake数据集上的实验表明,Veritas在跨域泛化能力上显著优于现有方法,能够提供更可靠的检测结果。
📝 摘要(中文)
深度伪造检测由于现实场景中伪造内容的复杂性和不断发展而仍然是一个巨大的挑战。然而,现有的学术基准与工业实践存在严重差异,通常具有同质的训练来源和低质量的测试图像,这阻碍了当前检测器的实际部署。为了弥合这一差距,我们引入了HydraFake数据集,该数据集通过分层泛化测试来模拟现实世界的挑战。具体来说,HydraFake涉及多样化的深度伪造技术和野外伪造,以及严格的训练和评估协议,涵盖了未见过的模型架构、新兴的伪造技术和新的数据领域。在此基础上,我们提出了一种基于多模态大型语言模型(MLLM)的深度伪造检测器Veritas。与普通的思维链(CoT)不同,我们引入了模式感知推理,其中包含诸如“规划”和“自我反思”之类的关键推理模式,以模拟人类的取证过程。我们进一步提出了一个两阶段的训练流程,以将这种深度伪造推理能力无缝地内化到当前的MLLM中。在HydraFake数据集上的实验表明,虽然以前的检测器在跨模型场景中表现出很好的泛化能力,但它们在新出现的伪造和数据领域中表现不佳。我们的Veritas在不同的OOD场景中取得了显著的收益,并且能够提供透明和忠实的检测输出。
🔬 方法详解
问题定义:现有深度伪造检测方法在面对真实场景中的复杂伪造技术和未知数据领域时,泛化能力不足。学术数据集的同质性和低质量限制了模型在实际应用中的有效性。现有方法难以模拟人类专家在取证过程中的推理能力,导致对新型伪造手段的识别率较低。
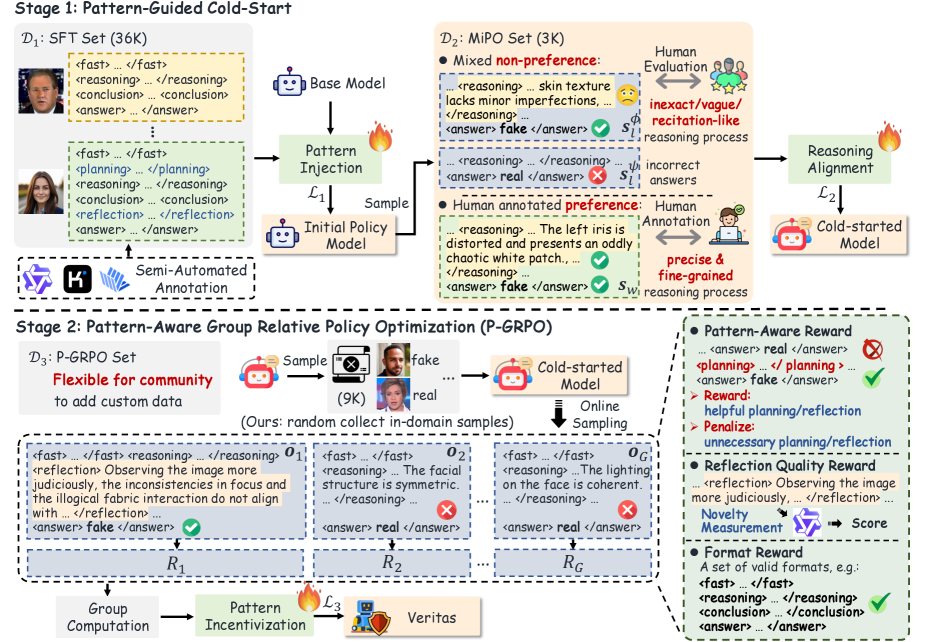
核心思路:Veritas的核心思路是引入模式感知推理,模仿人类专家在深度伪造检测中的推理过程。通过让模型学习规划和自我反思等关键推理模式,增强其对未知伪造模式的识别能力。利用多模态大型语言模型(MLLM)的强大能力,将视觉信息与推理过程相结合,提高检测的准确性和可解释性。
技术框架:Veritas采用两阶段训练流程。第一阶段,利用HydraFake数据集对MLLM进行预训练,使其具备基本的深度伪造识别能力。第二阶段,引入模式感知推理模块,通过强化学习或监督学习的方式,训练模型学习规划和自我反思等推理模式。检测时,模型首先提取输入图像的视觉特征,然后利用模式感知推理模块生成推理路径,最终输出检测结果和推理过程。
关键创新:Veritas的关键创新在于模式感知推理模块。与传统的思维链(CoT)方法不同,Veritas强调学习关键的推理模式,如规划和自我反思,从而更好地模拟人类的取证过程。这种方法使得模型能够更好地理解深度伪造的本质,并提高对未知伪造手段的泛化能力。
关键设计:HydraFake数据集的设计是关键。它包含多样化的深度伪造技术和野外伪造,以及严格的训练和评估协议,涵盖了未见过的模型架构、新兴的伪造技术和新的数据领域。两阶段训练流程的设计也至关重要,它确保了MLLM能够有效地学习和利用模式感知推理能力。具体的损失函数和网络结构细节未知。
🖼️ 关键图片


📊 实验亮点
Veritas在HydraFake数据集上进行了广泛的实验,结果表明,Veritas在跨模型、跨伪造技术和跨数据领域的泛化能力显著优于现有方法。具体性能数据未知,但论文强调了Veritas在不同OOD场景中取得了显著的收益,并能够提供透明和忠实的检测输出。
🎯 应用场景
Veritas可应用于社交媒体平台、新闻媒体、金融机构等领域,用于检测和识别深度伪造内容,防止虚假信息传播和欺诈行为。该研究有助于提高公众对深度伪造的防范意识,维护网络安全和社会稳定。未来,该技术可进一步应用于视频监控、身份验证等领域。
📄 摘要(原文)
Deepfake detection remains a formidable challenge due to the complex and evolving nature of fake content in real-world scenarios. However, existing academic benchmarks suffer from severe discrepancies from industrial practice, typically featuring homogeneous training sources and low-quality testing images, which hinder the practical deployments of current detectors. To mitigate this gap, we introduce HydraFake, a dataset that simulates real-world challenges with hierarchical generalization testing. Specifically, HydraFake involves diversified deepfake techniques and in-the-wild forgeries, along with rigorous training and evaluation protocol, covering unseen model architectures, emerging forgery techniques and novel data domains. Building on this resource, we propose Veritas, a multi-modal large language model (MLLM) based deepfake detector. Different from vanilla chain-of-thought (CoT), we introduce pattern-aware reasoning that involves critical reasoning patterns such as "planning" and "self-reflection" to emulate human forensic process. We further propose a two-stage training pipeline to seamlessly internalize such deepfake reasoning capacities into current MLLMs. Experiments on HydraFake dataset reveal that although previous detectors show great generalization on cross-model scenarios, they fall short on unseen forgeries and data domains. Our Veritas achieves significant gains across different OOD scenarios, and is capable of delivering transparent and faithful detection outputs.